
言語処理学会第28回年次大会に参加してきましたので、本大会の概要や興味深かった研究について報告します。
言語処理学会第28回年次大会について

言語処理学会第28回年次大会は、言語処理学会が主催する年次大会で自然言語処理に関する様々な研究発表が行われます。参加登録者数およびスポンサー数は歴代1位、発表件数も歴代3位とオンライン形式でも非常に盛り上がりました。
第28回年次大会の概要
基本情報
コロナ禍のため、昨年と同様に招待講演など一部のイベントは現地会場から行われ、現地とオンラインのハイブリットでの開催となりました。
研究分野
- 語彙資源・辞書
- 言語資源・アノテーション
- 計算・形式言語学
- 心理言語学・認知モデリング
- 発達言語学・言語教育学
- 社会・フィールド言語学
- その他の言語学
- 形態素・構文解析
- 固有表現
- 埋め込み表現
- 意味解析
- 含意・言い換え
- 談話理解
- 生成
- 要約
- 音声言語処理
- マルチモーダル処理
- 知識獲得・情報抽出
- 機械学習
- 機械翻訳
- 検索・文書分類
- 評判・感情分析
- 推薦システム
- 対話
- 質問応答
- 実世界接地と言語処理
- Web・SNS応用
- 教育応用
- 他分野における言語処理
本大会では、自然言語処理に関する計29の研究分野が発表されました。
大会日程
- 3月14日(月):チュートリアル、スポンサーイブニング
- 3月15日(火):本会議 第1日
- 3月16日(水):本会議 第2日、オンライン懇親会
- 3月17日(木):本会議 第3日
- 3月18日(金)ワークショップ

本会議は、1セッション80~100分で構成され、4~5件の研究が発表されます。また、ポスターセッションではGatherを利用して聴講や議論に参加することができました。また、本大会に参加できなかった方でもこちらから論文を確認することができます。
興味深かった研究
ここからは興味深かった研究について、いくつか紹介します。著者の趣味嗜好に偏っているので、あらかじめご了承ください。
日本語GPT を用いたトークナイザの影響の調査 / 井上誠一, Nguyen Tung, 中町礼文, Shengzhe Li, 佐藤敏紀 (LINE)
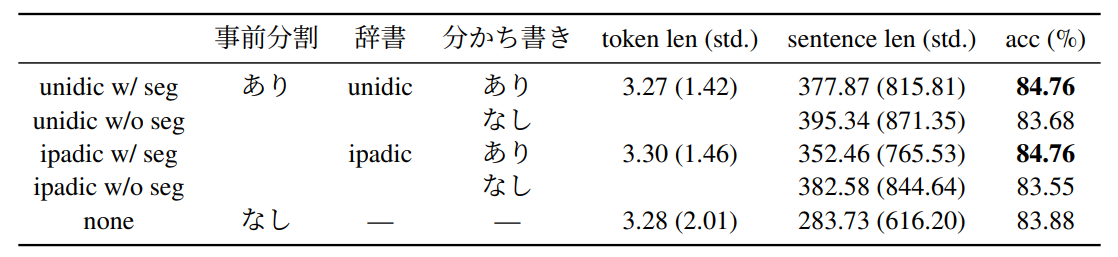
トークナイズ時の分かち書きを行った方が性能が高くなっている。
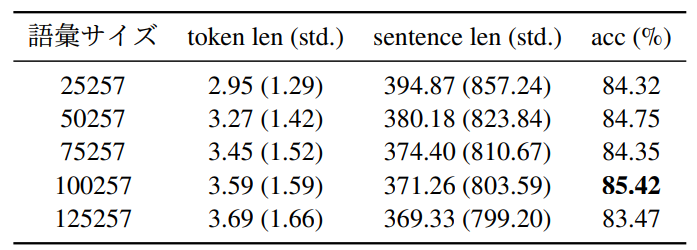
語彙サイズが比較的大きめな 100,257 のトークナイザ
を用いた際にスコアが最も高くなっている。
- 本研究では、条件の異なるByte-level BPEトークナイザを用いて、日本語GPTの事前学習と含意関係認識タスクを用いた転移学習を行い、トークナイザの違いが言語モデルの事前学習や下流タスクに与える影響を分析している。
- データセットについては、事前学習ではWikipedia、ニュースサイト、ブログサイト、新聞等の日本語を中心としたテキストから構築されたものを利用し、転移学習には日本語SNLI(JSNLI)を用いていた。
- 実験は、トークナイザ構築に用いるテキストの事前分割の有無(unidic、ipadicを用いる)、トークナイズ時の分かち書きの有無によって性能を比較する予備実験と、語彙サイズの変化によって性能を比較する語彙サイズの実験の2つに分けられる。
- 予備実験の結果から、事前学習ではトークナイザ構築に用いるテキストをunidicを用いて事前分割し、トークナイズ時の分かち書きは行わないという条件のものが最も性能が高いことを示したが、転移学習ではトークナイズ時の分かち書きを行った方が性能が高い結果となった。
- 語彙サイズの実験の結果から、事前学習では語彙サイズが小さい、つまり文章長(sentence_length)が長くなるトークナイザを用いたほうが性能が高い傾向が見られたが、転移学習ではその逆の傾向が見られた。
- これらの実験から、事前学習においては、文章長が長くなるとモデルの計算量が増加するという機械学習的な性質から文章長が長い方が性能が高くなるのではないかと仮説を立てていた。
- 転移学習においては、事前学習とは結果が異なっていたため他の下流タスクを用いてトークンの持つ性質を調査していきたいとのこと。
- トークナイザの影響によってモデルの性能が変化するという知見を得た。
- また、日本語かつGPTを対象として性能の変化を調査しているところが興味深いと感じた。
- URL:https://www.anlp.jp/proceedings/annual_meeting/2022/pdf_dir/A1-2.pdf
Transformer を多層にする際の勾配消失問題と解決法について / 高瀬翔 (東工大), 清野舜 (理研/東北大), 小林颯介 (PFN/東北大), 鈴木潤 (東北大/理研)
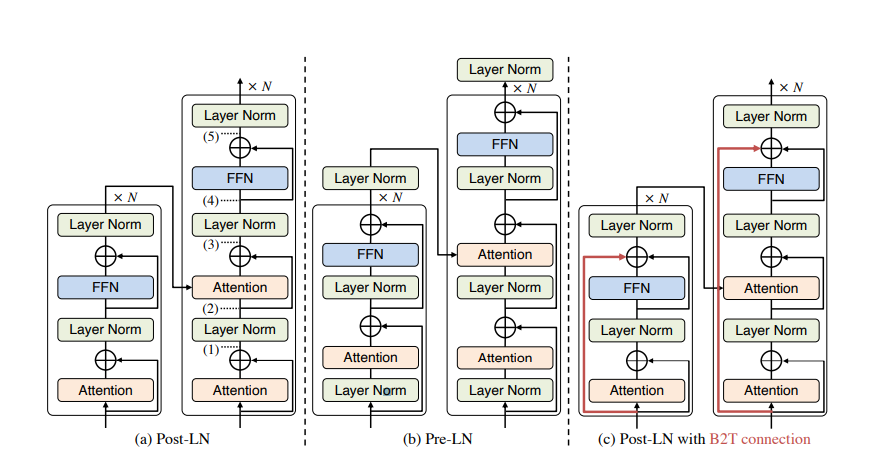
(a) は Post-LN、(b) は Pre-LN、(c) は Post-LN に提案手法(Residual Connectio)を組み
合わせたものを表している。
- Transformerは、勾配爆発や消失を防ぐためにLayer Normalization(LN)が採用されておりLNの位置の違いによってPost-LNとPre-LNに大きく分類されている。
- 先行研究では、学習の不安定性に目をつぶればPost-LNはpre-LNよりも優れていることが報告されているため、Post-LNの学習の安定性向上に取り組んでいた。
- 本研究では、Post-LNにResidual Connectionを追加するという手法(B2T Connection)を提案している。
- 評価実験では、機械翻訳タスクの下でPost-LN、Pre-LN、提案手法、既存手法(DLCL、Admin)が用いられ、それぞれレイヤ数が6の場合と18の場合の性能を比較していた。
- 学習には、450万の英語と独語の文章ペアからなるWMT 英-独データセットを用い、性能評価にはnewstest2013-2016を用いていた。
- また、語彙の構築にはBPEを用いている。
- 結果は、レイヤ数を18(多層)にすることでPost-LNが学習に失敗していることを確認した。
- また、提案手法は学習に成功し、Pre-LNよりも高く、従来手法と同等以上の性能を達成していた。
- Transformerを多層化する事で起きる勾配消失問題を提案手法によって改善し、Pre-LNよりも性能を向上させているところが興味深いと感じた。
- URL:https://www.anlp.jp/proceedings/annual_meeting/2022/pdf_dir/A2-5.pdf
RINA:マルチモーダル情報を利用したキャラクターの感情推定 / 頼展韜, 髙橋誠史 (バンダイナムコ研)
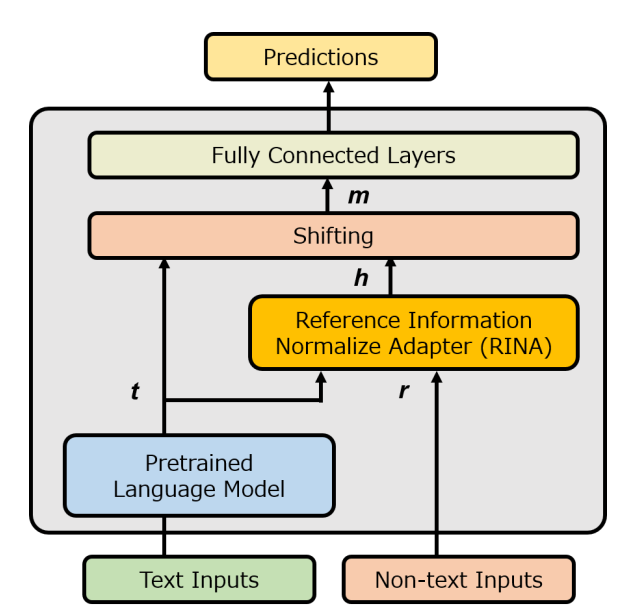
モデルは、BERTを用いて事前学習を行い、
RINAを用いてテキストと非テキスト情報を結合させた
後、複数の全結合層を経て予測値を出力する。
- 多数のキャラクターが登場するゲームにおいて、キャラクターのセリフに合わせて適切な感情表現や演出を指定するタスクが手作業で行われているという課題がある。
- これらの課題を解決するために、フィクション作品内のキャラクターのセリフ(テキスト)やキャラクターの名前、性別、セリフシーンのIDといった属性(非テキスト)を用いた感情推定を行っている。
- 本研究では、タスクに合わせて東北大BERTに追加事前学習を行った後、テキストと非テキストの関係性をベクトル空間上で表現するRINAモデルを提案していた。
- 本研究では、「通常」「怒り」「悲しみ」「驚き」「笑い」計5つの感情を推定するために28,195件からなる独自のゲームシナリオスクリプトを用いて実験が行われた。
- 提案手法(RINA)の比較対象として、テキストのみを学習させたBERTベースのモデルとテキストと非テキストを学習させたBERTベースのモデルを用いていた。
- 実験の結果は、提案手法によって従来手法より感情推定精度が向上することを確認した。
- また、テキストのみを学習したモデルが最も性能が低い結果となったため、非テキストデータが感情推定に寄与していることも確認できた。
- 人ではなく、作品中のキャラクターを対象とした感情推定が珍しく感じた。
- また、人間とは異なった感情推定へのアプローチを知ることができた。
- URL:https://www.anlp.jp/proceedings/annual_meeting/2022/pdf_dir/A6-2.pdf
おわりに
本大会では、自然言語処理に関する様々な研究に触れることができ、とても充実した5日間になりました。中でもTransformerやBERTに関する研究発表が多かった印象です。また、質の高い研究が多く、既存手法の課題や現代社会の課題を解決したものが多くみられました。沖縄で開催予定である言語処理学会第29回年次大会での研究発表に期待が高まります。
K.Y

