
先日、情報処理学会 第84回全国大会に参加してきましたので、本大会の概要や興味深かった研究について報告します。
情報処理学会 第84回全国大会について

情報処理学会 全国大会は、一般社団法人情報処理学会が主催する年1回(春季)の学会最大のイベントです。最新の学術・技術動向や情報に関する新しい研究成果やアイディア発表を通し意見交換・交流を行っています。約1200件の一般講演発表に加えて、招待講演やパネル討論などのイベントも合わせて開催しています。
第84回全国大会の概要
基本情報
- 開催期間:2022/03/03(木)~2022/03/05(土)
- 開催形式:オンラインと現地(城北キャンパス)のハイブリット開催
- 参加費用:こちらを確認
- 一般セッション:45件
- 学生セッション:162件
- 招待講演:4件
- イベント企画:29件
- スポンサー:14社
※一般、学生セッションともに1セッションあたり6~9件の発表がありました
コロナ禍のため、昨年に続きオンラインでの開催となりましたが、招待講演などは現地の会場から行うハイブリッドでの開催となりました。
発表分野

発表分野は大きく分けて8つあり、様々な研究に触れることができます。
大会プログラム
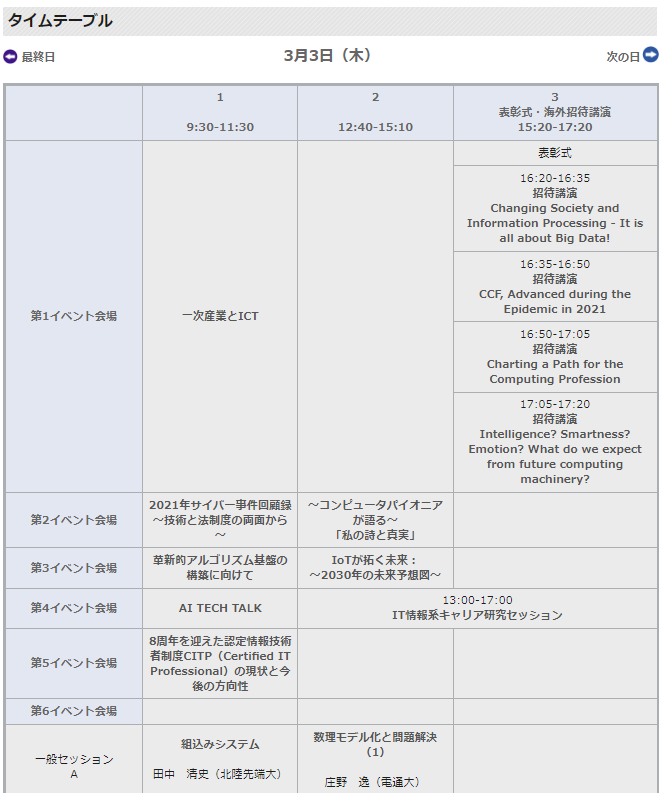
大会当日は、セッション名の横にZoomのアイコンが表示され、クリックするだけで簡単に聴講することができました。大会後も大会参加者は参加者専用ページから論文を読むことができます。また、本大会の論文は大会の6ヵ月後よりこちらに掲載されるとのことです。
興味深かった研究
今回、聴講した中で興味深かった発表について紹介します。発表内容はクローズドな情報なので、私がとったメモをベースとしてまとめていることを予めご了承ください。
BERT による日本語文の感情分析と話題分析 / 圓谷顯信,高橋宏和,安達由洋(東洋大)
- 本研究ではBERTを用いた日本語の感情分析と話題に基づく日本語文の分類・検索についての実験結果を述べている。
- 感情分析:
- 感情分析では、11種類の感情を分類するため著者等でラベル付けを行った計13,116文の日本語データセット(AmazonレビューやGoogleの口コミなど)を用いて東北大BERTをファインチューニングし、著者等が提案していた従来手法を用いて分類精度と学習速度を比較していた。
- 今回のモデルの方がいくつかの感情カテゴリで従来手法よりF1scoreが10%以上高いことを示したが、F1scoreは0~80%と感情によってばらついていることが分かった。
- 学習時間については、今回のモデルの方が学習に時間がかかってしまうことを指摘していた。
- 今回のモデルは、10,000文の感情分析の実行にGPU上でmini-batchで実行して21秒かかるが従来モデルは、CPUのみで約1 秒で実行できるとのこと。
- 話題に基づく日本語文の分類・検索:
- モデルは感情分析と同様に東北大のBERTモデルを使用していたが、データセットは150文からなる新たなデータを使用している。
- 日本語文の分類方法は、まず、データセットをBERTモデルに入力し、各文に対する分散表現を出力した。
- 次に、これらの分散表現をk-means++手法でクラスタリングし、各クラスタに対してラベル付けを行っていた。
- 日本語文の検索方法については、検索文の分散表現と上記で出力した日本語文の分散表現との類似度を求め、最も類似度の高い日本語文をデータセットから抽出していた。
- 類似文の抽出結果について、ノイズが多いことを示した。
- 今後の課題として、より大規模な日本語データセットを作成して精度の高い11感情分析BERTモデルを開発すること、BERTで抽出したクラスタリングについては適切なクラスタラベルの付加方法の検討が必要であることを述べていた。
- ポジティブ・ネガティブといったように分類クラスが少ない感情分析の研究を目にすることが多い中、本研究では11の感情を分析しており感情によってはばらつきがあるものの高い分類精度を示していたためめ興味深い研究だと感じた。
BERTを用いたSNS上における攻撃的文章訂正システム / 吉田基信,松本和幸,吉田 稔,北 研二(徳島大)
- 近年、SNSの利用者が増加する一方で誹謗中傷や炎上などの被害にあう件数が増加していることに焦点を当てて研究を行っている。
- この課題を解決すべく、SNSユーザーが発言を投稿する前に投稿文の攻撃性を判定し、攻撃性を緩和した文章に変換する提案システムの構築を目指していた。
- 本研究の提案手法は、入力文章の前処理、攻撃的文章の判定、攻撃的文章を緩和した文章の提案、訂正前文章と訂正後文章との類似度の比較の4つに分類される。
- TweetLライブラリを使用してTwitterのツイート文の前処理を行い安全、攻撃的、スパム3つのラベルを付与し、事前学習モデルを用いてファインチューニングをしていた(学習データは1,600件)。
- 次に、攻撃的と分類された文章はBERTによるMASK予測変換を行い、BERTscoreを用いて訂正前と訂正後の文章間の類似度を求めていた。
- 評価実験では、攻撃的文章の分類精度と訂正前、訂正後文章の類似度をもとに評価を行っている。
- 攻撃的文章の分類精度は70%で、文章の類似度は攻撃的と判断された文章の8割以は類似度が85%を超えていることが分かった。
- しかし、類似度が高いわりに訂正前の文章と意味が大きく異なった文章もいくつか確認された。
- 課題として、攻撃的文章の分類精度が低いことや文章訂正の見直しなどが挙げられていた。
- 今後は、ファインチューニングに用いるコーパスの量を増やすことにより精度向上を目指すとのこと。
- SNSの課題解決を目指すという現代社会のニーズにマッチしている研究だと感じた。
- また、提案手法には改善の余地が見られたがBERTを用いて攻撃的文章を緩和した文章に変換するというアプローチが興味深かった。
歌詞のストーリー展開に基づく時系列類似性による楽曲推薦方式 / 村田 賢,岡田龍太郎,峰松彩子,中西崇文(武蔵野大)
- 近年、インターネット上に楽曲コンテンツが膨大に蓄積されつつあり、どの曲がユーザー自身の印象やニーズとマッチしているかをユーザーが素早く発見できる新たな手法の実現が重要であることを述べた。
- 本研究では、類似楽曲の探索を可能にする手法を提案している。
- 楽曲の類似度を求めるため、歌詞中の単語と色の印象を表す印象語との類似度をWord2Vecを用いて計算し、歌詞中の単語と色をマッチさせることで歌詞のストーリーを色の変化で表現していた。
- 次に、歌詞のストーリーを色の変化で表現したものを時系列感性色彩表現と呼び、時系列感性色彩表現をRGB値に沿って3つの時系列データに変換した。
- DTWという時系列データの類似度を計算する手法を用いて、作成した時系列データから各楽曲の類似度を計算していた。
- 評価実験では、日本のポップス10曲を用いて類似度の評価を行っており、歌詞の内容が似ている楽曲の類似度が高くなっていることを示した。
- 歌詞のストーリーを色の変化で表現し、類似する楽曲を探索するというアプローチが興味深かった。
- 本研究の評価実験では、日本のポップス10曲しか使用していないため曲を増加した時でも類似する楽曲を探索できるのかが気になった。
- また、Word2Vec以外の単語ベクトル化手法を用いた場合との比較が知りたいところ。
おわりに
今回は人工知能分野をメインに聴講しましたが、人工知能に限らず様々な研究分野の動向を知ることができる場だと感じました。今回聴講した中には、上記で紹介したようにBERTを用いた従来手法の課題解決や現代社会の課題解決を目指すような発表が見られました。また、研究のアプローチが興味深いものが多かったです。次の大会は、電気通信大学で開催予定なので参加してみてはいかがでしょうか。
K.Y

