
はじめに
この記事では、PerceiverとPerceiver IOについて、そのモデルアーキテクチャとソースコードを解説します。これまで数多くの深層学習モデルが開発されてきましたが、単一のモデルで様々なタスクを解くことは人工知能分野における大きなテーマの一つでもありました。PerceiverやPerceiver IOでは、その課題を解決する汎用アーキテクチャです。なおかつ計算効率の面でも他のモデルを圧倒する成果を出しています。
Perceiverとは
Perceiverは2021年6月にDeepMindが公開したTransformerベースの深層学習モデルです。元来、深層学習で用いられるモデルは、モダリティやタスクに特化するように設計されていました。例えば、画像データを扱う際にはCNN、シーケンスデータを扱い際にはRNNなどです。しかしながら、こういったモデルは帰納的バイアスを持っており、モデルを個々のモダリティに制限しています。そこで、Perceiverが提案されました。Perceiverは、前提として入力データの種別を仮定しないTransformerをベースとして構築されており、画像、点群、音声、ビデオ、ビデオ+音声といった様々なモダリティに対応することができます。
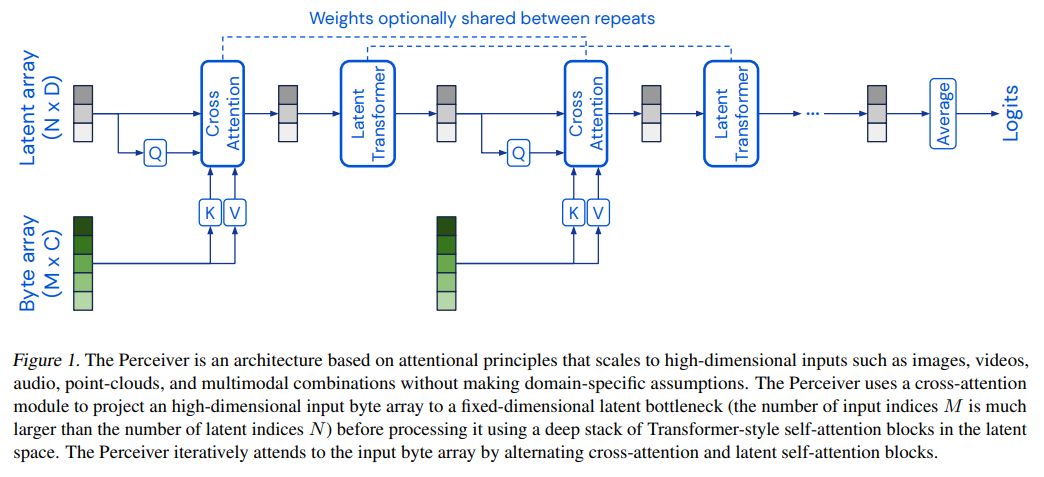
上図がPerceiverのモデルアーキテクチャになります。Perceiverは主にCross AttentionとLatent Transformerから構成されています。Cross Attentionは図に示されているバイト配列(Byte array)と潜在配列(Latent array)を対応付ける役割を持っています。バイト配列のサイズは入力データによって決まりますが、ハイパーパラメータとしてサイズを決めることができる潜在配列に対応付けることによって、Attentionの二次スケーリング問題を解決しています。Latent Transformerは複数のTransformerが重なったものです。Latent Transformerでは、Cross Attentionによって対応付けられた潜在配列からさらに潜在配列を出力します。このようにCross AttentionとLatent Transformerを交互に適用することによって特徴表現を獲得します。Perceiverはこれにより任意の入力を扱うことができる表現力と柔軟性を保持しつつ、高次元のデータを扱うことができます。
Perceiver IOとは
Perceiver IOは、先述のPerceiverに続いて2021年8月に発表された深層学習モデルです。Perceiverでは分類といった単純なタスクを扱っていましたが、Perceiver IOでは入力データが持つ一般性と同じレベルの出力を得ること目指し、言語、オプティカルフロー、オーディオビジュアルシーケンス、記号的な非順序集合など構造化された出力をPerceiverから直接デコードする機構を備えています。

Perceiver IOのアーキテクチャは上図に示す通りです。主にEncode、Process、Decodeの3つの要素から構成されています。Encodeでは、Attentionモジュールを適用して入力配列(Input array)を潜在配列(Latent array)に符号化します。次にProcessでは潜在配列をAttentionモジュールに適用し、さらに潜在配列を出力します。この部分はドメインに依存しません。最後にDecodeで潜在配列と出力配列(Output query array)で対応付けを行い復号します。ここで、図に示すサイズM、C、O、Eはタスクデータの特性であり、非常に大きくなることがあります。一方でNとDはハイパーパラメータであり、モデルの計算が扱いやすくなるように選択することができます。したがって、エンコーダとデコーダのAttentionモジュールはそれぞれ入力と出力のサイズに線形に依存しますが、潜在的なAttentionは入力と出力の両方のサイズに依存しません。これにより計算の効率化が図られています。
コード解説
次にソースコードを見ていきたいと思います。DeepMindがPerceiverとPerceiver IOのソースコードを公開していますので、そちらを参照しながら解説します。解説するコードは、主なコンポーネントであるPerceiver、Encoder、Decoderです。ちなみにGoogleが開発した機械学習のための数値計算ライブラリJAXを用いて実装されています。
Perceiver
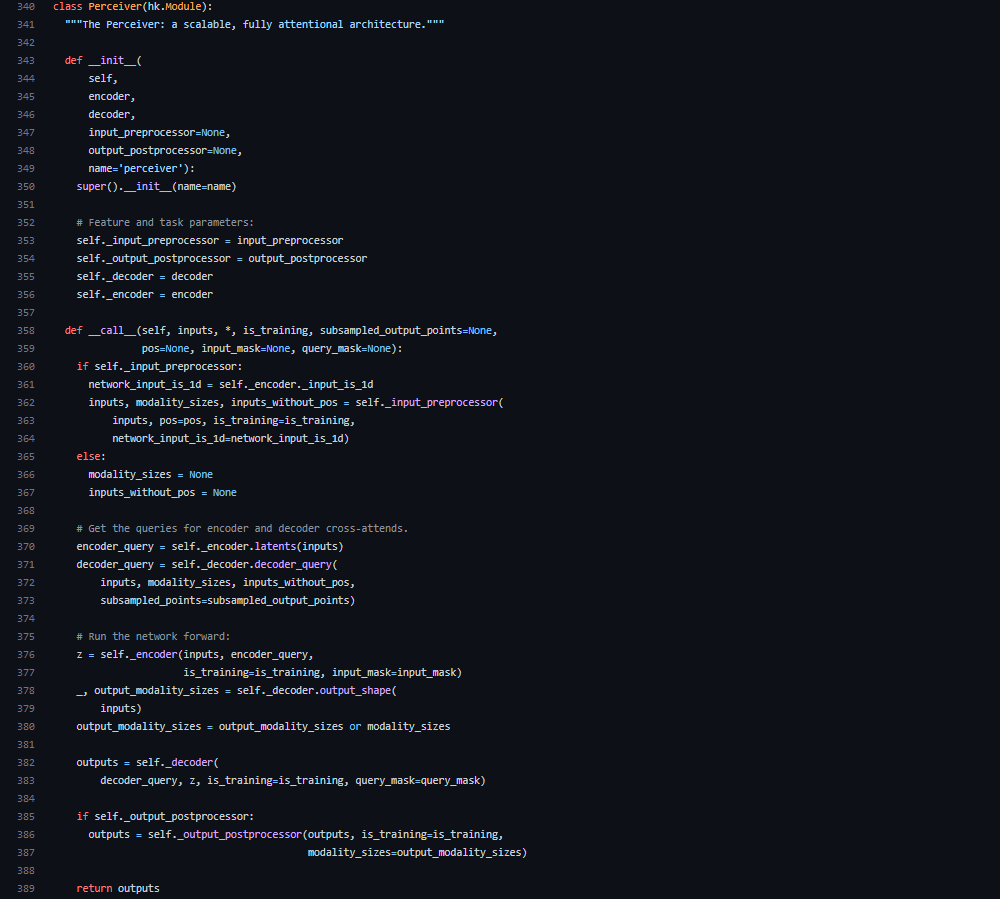
まずはPerceiverクラスを見てみましょう。__init__メソッドでは、self.decoder = decoder(355行目)やself.encoder = encoder(356行目)となっており、それぞれエンコーダーとデコーダーを設定するようになっています。
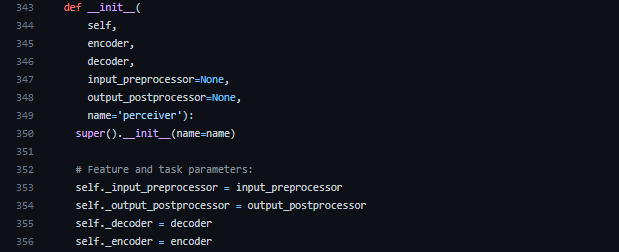
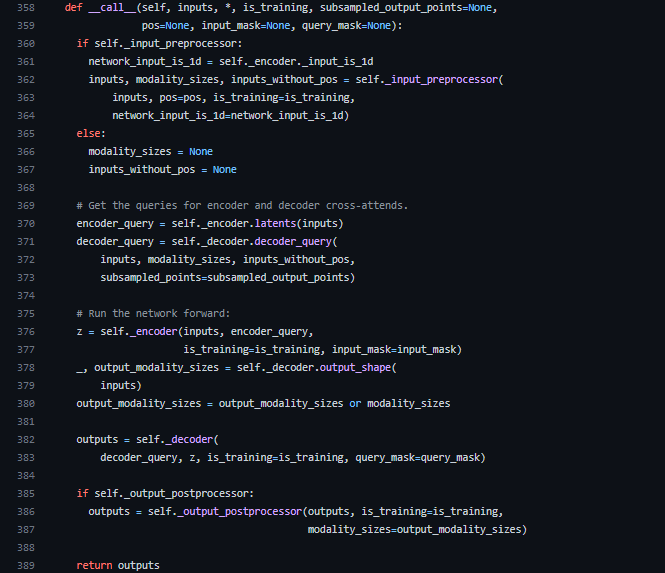
__call__メソッドは、インスタンスを関数のように呼び出すことができるメソッドです。370行目のencoder_query = self._encoder.latents(inputs)で潜在配列を初期化しています。その後、375行目以降ではPerceiver IOのアーキテクチャで説明した通り、入力配列と潜在配列が順に処理されていきます。
Encoder
続いて、Perceiverクラスで宣言されていたエンコーダーについて見ていきます。エンコーダーには、PerceiverEncoderクラスを用います。
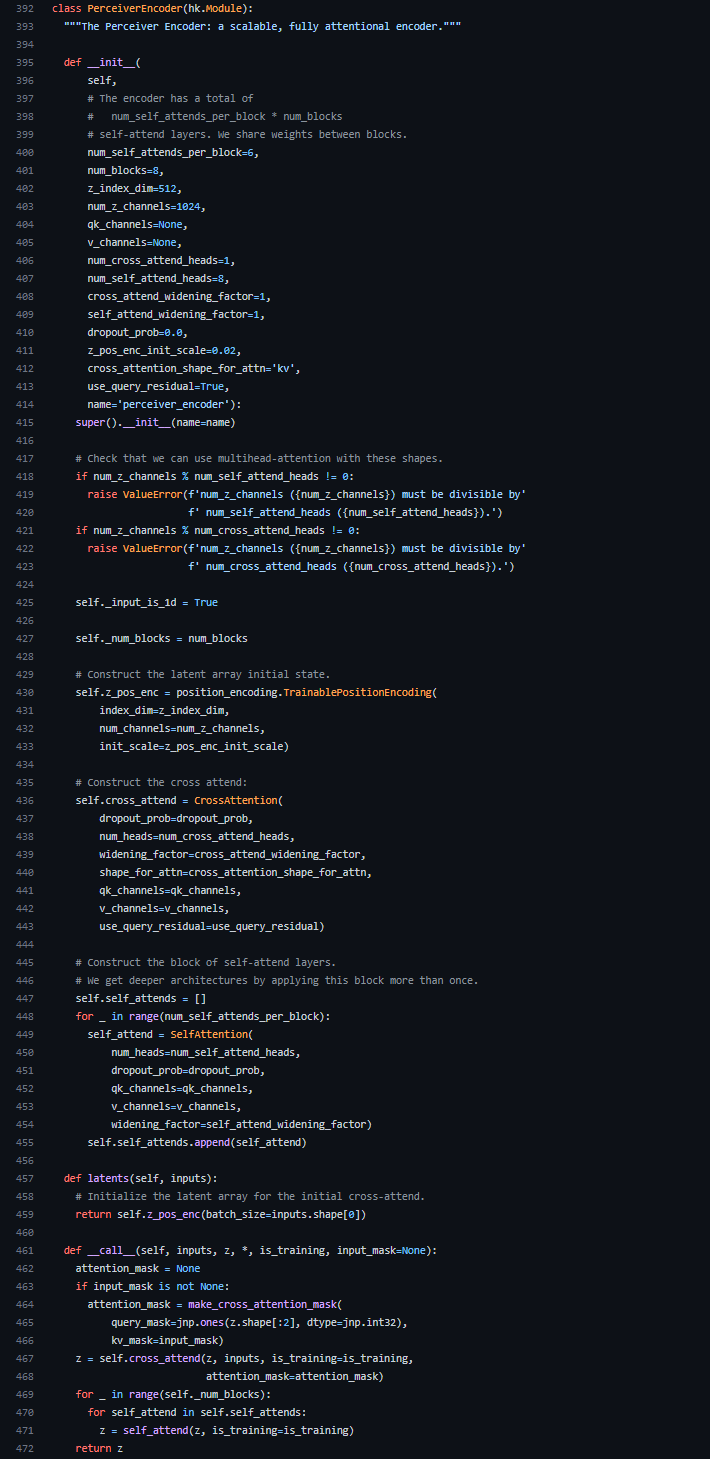
__init__メソッドでは、CrossAttention(436行目)とSelfAttention(449行目)が宣言されています。CrossAttentionは入力データと潜在配列を受け取って対応付けを行っていました。SelfAttentionはモデルアーキテクチャで説明したLatent Transformerにあたります。ここでは、num_self_attends_per_blockの数だけSelfAttentionが積み重ねられています。

__call__メソッドでは、coss_attend(CrossAttention)にデータ(inputs)と潜在配列(z)を入力していることが分かります(467行目)。その後、self_attends(Latent Transformer)をfor文で繰り返し取り出し、潜在配列(z)を処理しています。
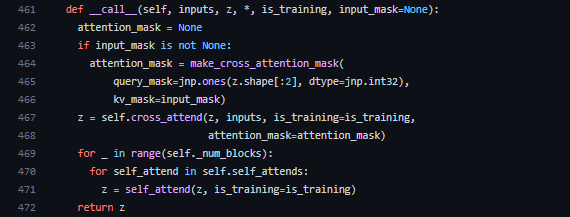
Cross AttentionとSelf Attentionの違い
Perceiver IOのアーキテクチャの図からもわかるようにCross Attentionは入力配列と潜在配列との関係性を見ていて、Self Attentionは潜在配列自身に対する関係性を見ています。ソースコードでもその違いを見てみましょう。それぞれのクラスを見れば、ところどころ違いがありますが、一番大きな違いはAttentionの部分でしょう。
まず、CrossAttentionの__call__メソッド内のAttentionを見てみます。Attentionクラスが宣言されており、Attentionの__call__メソッドにはlayer_normを適用したinputs_q、inputs_kvが入力されています。エンコーダーの場合、inputs_qは潜在配列、inputs_kvは入力配列になり、潜在配列と入力配列の関係性を見ていることが分かります。

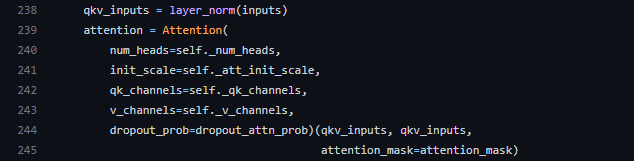
続いて、SelfAttentionの__call__メソッド内のAttentionを見てみます。CrossAttentionと同様にAttentionクラスが宣言されていますが、Attentionの__call__メソッドにはqkv_inputsが2つ入力されています。これは、238行目のinputsにlayer_normを適用したものですが、ここではqkv_inputsとqkv_inputs、つまり潜在配列と潜在配列の関係性を見ていることが分かります。
ちなみに各コンポーネントでのAttentionの違いを表したものが次の図になります。
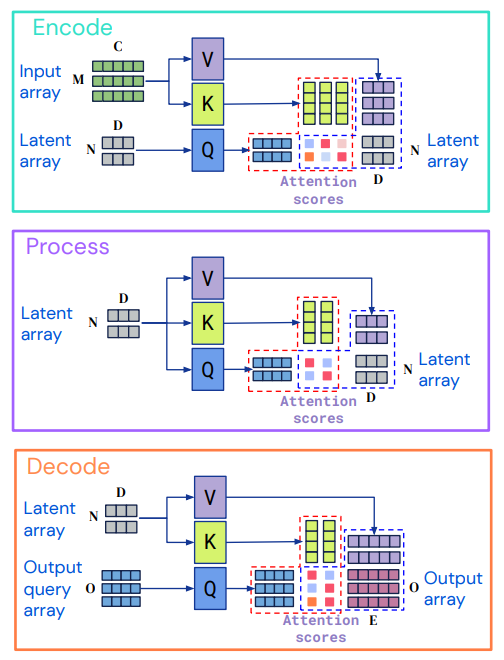
デコーダーでもエンコーダーと同じくCoss Attentionを行っていますが、この場合は出力配列と潜在配列の関係性を見ています。
Decoder
次にDecoderクラスを見てみましょう。Decoderクラスはモダリティやタスクにあわせて実装が変化しますので、一つ例を挙げて解説します。例えば、画像分類をするClassificationDecoderを見てみましょう。
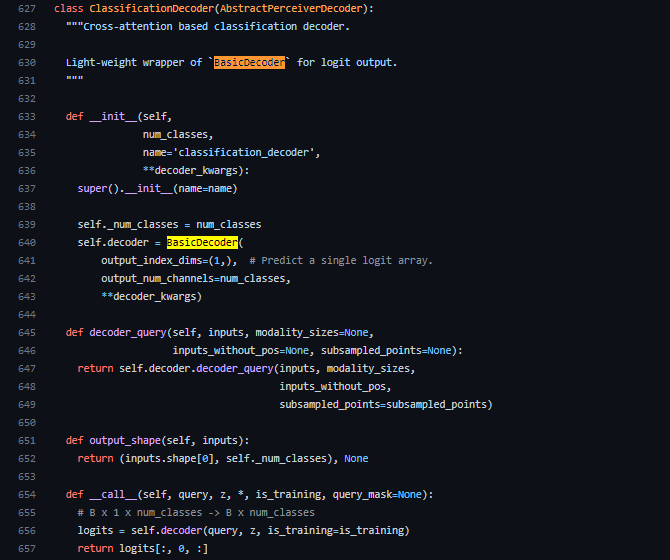
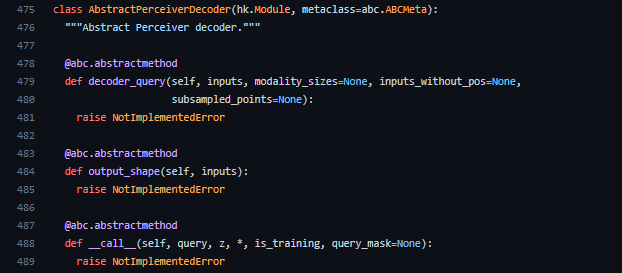
ClassificationDecoderはAbstractPerceiverDecoderを継承しています(627行目)。AbstractPerceiverDecoderは以下のようになっており、Decoderクラスの抽象クラスであることが分かります。
また、ClassificationDecoderでは、640行目でさらにself.decoder = BasicDecoder…とデコーダーが宣言されています。

もう一度ClassificationDecoderクラスの__call__メソッドに戻ってみると、デコーダーの出力logits[:, 0, :]を出力しています(これは線形層を用いて出力結果をターゲットクラスの数に投影しています)。よって、デコーダーのほとんどの処理はBasicDecoderで行われていることが分かります。
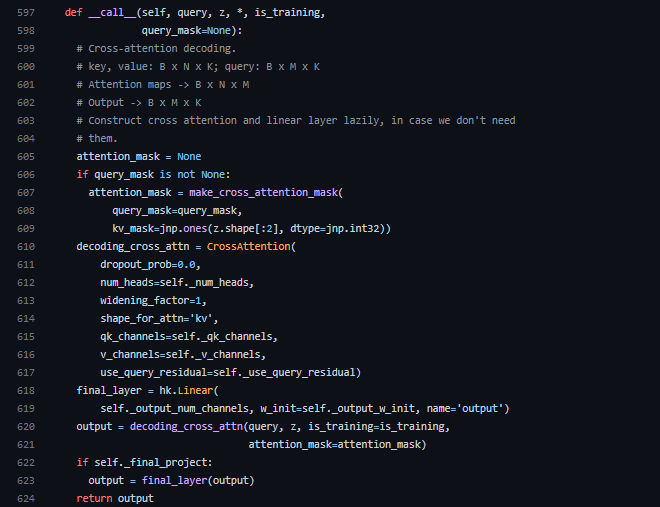
BasicDecoderクラスの__call__メソッドを見ると、CrossAttentionクラスが宣言されており、BasicDecoderはCross Attentionベースのデコーダーであることが分かります。この時、decoding_cross_attn(620行目)に入力されているqueryは出力配列をdecoder_query関数でデコードしたもの、zはエンコーダーから出力された潜在配列です。したがって、デコーダーではCrossAttentionを用いて潜在配列と出力配列の対応付けをしています。
Perceiverで重要な役割を果たしているTransformerやAttentionに関する詳細な解説は、過去の記事に記載しておりますので、そちらを参考にしてみてください。

おわりに
今回はPerceiverとPerceiver IOについて解説してきました。モデルアーキテクチャとソースコードに焦点を絞って解説しましたが、DeepMindのGitHubリポジトリには実際に事前トレーニング済みのPerceiver IOモデルを用いた画像分類やオプティカルフローの例が提供されています。興味のある方はぜひ実際に触ってみて、Perceiver IOが様々なモダリティに有効であることを確認してみてください。
- 参考文献
(K. K)

