
この記事では、言語処理100本ノック第5章の解説に引き続き、言語処理100本ノック第6章の解説を行っていきます。 第6章では、Fabio Gasparetti氏が公開しているNews Aggregator Data Setを用いて、ニュース記事の見出しを「ビジネス」「科学技術」「エンターテイメント」「健康」のカテゴリに分類するタスク(カテゴリ分類)に取り組みます。それでは、第6章の問題を解きましたので、処理の流れとポイントを踏まえて、解説していきます。
問題と解説
50. データの入手・整形
News Aggregator Data Setをダウンロードし、以下の要領で学習データ(train.txt),検証データ(valid.txt),評価データ(test.txt)を作成せよ.
- ダウンロードしたzipファイルを解凍し,
readme.txtの説明を読む. - 情報源(publisher)が”Reuters”, “Huffington Post”, “Businessweek”, “Contactmusic.com”, “Daily Mail”の事例(記事)のみを抽出する.
- 抽出された事例をランダムに並び替える.
- 抽出された事例の80%を学習データ,残りの10%ずつを検証データと評価データに分割し,それぞれ
train.txt,valid.txt,test.txtというファイル名で保存する.ファイルには,1行に1事例を書き出すこととし,カテゴリ名と記事見出しのタブ区切り形式とせよ(このファイルは後に問題70で再利用する).
学習データと評価データを作成したら,各カテゴリの事例数を確認せよ.
【コード】
|
1 2 3 |
#ファイルのダウンロード、解凍 !wget https://archive.ics.uci.edu/ml/machine-learning-databases/00359/NewsAggregatorDataset.zip !unzip ./NewsAggregatorDataset.zip |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import pandas as pd from sklearn.model_selection import train_test_split #ファイルを読み込む df = pd.read_csv("newsCorpora.csv", sep="\t", header=None, names=["ID", "TITLE", "URL", "PUBLISHER", "CATEGORY", "STORY", "HOSTNAME", "TIMESTAMP"]) #各カラムのデータ数、欠損値、オブジェクトを確認する df.info() #情報源(publisher)が”Reuters”, “Huffington Post”, “Businessweek”, “Contactmusic.com”, “Daily Mail”の事例(記事)のみを抽出する df = df[df["PUBLISHER"].isin(["Reuters", "Huffington Post", "Businessweek", "Contactmusic.com", "Daily Mail"])] df = df[["TITLE", "CATEGORY"]] #学習、検証、評価データに分割する train_full, test = train_test_split(df, test_size=0.1, shuffle=True) train, valid = train_test_split(train_full, test_size=0.1, shuffle=True) #学習、検証、評価データをファイルに保存する train.to_csv("train.txt", sep="\t", index=False, header=None) valid.to_csv("valid.txt", sep="\t", index=False, header=None) test.to_csv("test.txt", sep="\t", index=False, header=None) print("\n【CATEGORYの事例数】") print("train\n", "-"*50,"\n", train["CATEGORY"].value_counts()) print() print("valid\n", "-"*50,"\n", valid["CATEGORY"].value_counts()) print() print("test\n", "-"*50,"\n", test["CATEGORY"].value_counts()) |
【出力結果】

【処理の流れ】
- ファイルをダウンロードし、解凍する。
- ライブラリをimportする。
- readme.txtを読み込む。
- ファイルのデータ数や欠損値の有無などを確認する。
- 問題に、指定された”PUBLISHER”を抽出し、”TITLE”、”CATEGORY”の列を抽出する。
- train_test_split()を2回使用して、学習データ80%、検証データ10%、評価データ10%に分割し、タブ区切りで、ファイルに保存する。
- value_counts()を使用して、”CATEGORY”列の要素数を表示する。
【ポイント】
- pd.read_csv()関数:csvファイルを読み込む。
- DataFrame.to_csv()メソッド:DataFrameをcsvファイルとして書き込む。
- pandas.DataFrame.info()メソッド:行数・列数や全体のメモリ使用量、各列のデータ型や欠損値ではない要素数などの情報を表示できる。
- pandas.Series.isin()メソッド:DataFrameの条件抽出ができる。戻り値はbool型。引数に、取得したい要素を指定する。
- DataFrame列の抽出:df[“列名”]を指定することで、DataFrameの列を抽出することができる。
- sklearn.model_selection.train_test_split()関数:データセットの分割ができる。引数のtest_sizeには、テスト用データの割合を指定できる。shuffle=Trueにすることで、データをシャッフルすることができる。
- pandas.Series.value_counts()メソッド:要素数をカウントすることができる。
51. 特徴量抽出
学習データ,検証データ,評価データから特徴量を抽出し,それぞれtrain.feature.txt,valid.feature.txt,test.feature.txtというファイル名で保存せよ. なお,カテゴリ分類に有用そうな特徴量は各自で自由に設計せよ.記事の見出しを単語列に変換したものが最低限のベースラインとなるであろう.
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
import string import re from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import train_test_split #前処理(関数) def preprocessing(text): text = "".join([i for i in text if i not in string.punctuation]) text = text.lower() text = re.sub("[0-9]+", "", text) return text #データの連結、前処理を行う df = pd.concat([train, valid, test], axis=0) df["TITLE"] = df["TITLE"].map(lambda x: preprocessing(x)) # 単語ベクトル化、DataFrameに変換する vec_tfidf = TfidfVectorizer() data = vec_tfidf.fit_transform(df["TITLE"]) data = pd.DataFrame(data.toarray(), columns=vec_tfidf.get_feature_names()) # dataを3分割する(ラベルも同時に分割させるため、train_test_splitは使用しない) split_point_1 = int(len(data) // 3) split_point_2 = int(split_point_1 * 2) #学習、検証、評価データ x_train = data[:split_point_1] x_valid = data[split_point_1:split_point_2] x_test = data[split_point_2:] #学習、検証、評価ラベル y_data = df["CATEGORY"] y_train = y_data[:split_point_1] y_valid = y_data[split_point_1:split_point_2] y_test = y_data[split_point_2:] # 特徴量をファイルに保存する x_train.to_csv('train.feature.txt', sep='\t', index=False) x_valid.to_csv('valid.feature.txt', sep='\t', index=False) x_test.to_csv('test.feature.txt', sep='\t', index=False) |
【出力結果】
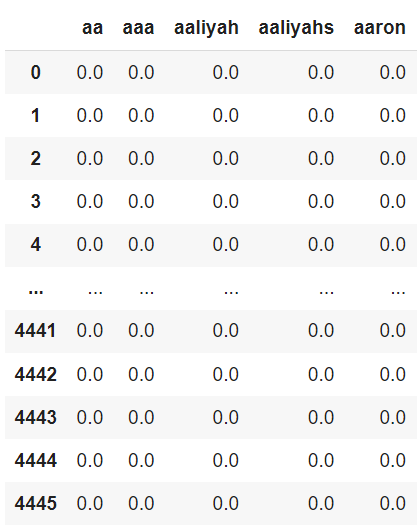
【処理の流れ】
- テキストの前処理を行う関数を実装する。
- 問50で作成した学習、検証、評価データを1つに連結させ、前処理を行う。
- 各テキストの単語をベクトル化し、DataFrameに変換する。
- DataFrameを学習、検証、評価データに分割する。ラベルも同様に処理を行う。
- 各データの特徴量をファイルに保存する。
【ポイント】
- 機械学習モデルにテキストデータを入力する前に、単語をベクトルに変換する必要がある。ベクトル化手法は色々あるが、ここではTfidfVectorizer()を使用した。
- 3つのデータを連結させた理由:モデル学習を行う際は学習、検証、評価データのベクトルの次元数を一致させる必要があるため。
- TfidfVectorizer.fit_transform()メソッド:引数にテキストデータを入力し、TF-IDFを使用して単語をベクトルに変換する。戻り値はscipy型。
- TF-IDF:各文書に含まれる各単語が「その文書内でどれくらい重要か」を評価する方法。
- TfidfVectorizer.get_feature_names()メソッド:特徴量(単語)を取得する。
- scipy.sparse.csr_matrix.toarray()メソッド:scipyオブジェクトをnumpyオブジェクトに変換する。
- np.savetxt()関数:numpyオブジェクトをファイルに保存することができる。第一引数に、ファイル名を指定し、第二引数に保存したいnumpy配列データを指定する。
52. 学習
51で構築した学習データを用いて,ロジスティック回帰モデルを学習せよ.
【コード】
|
1 2 3 4 |
from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(x_train, y_train) |
【出力結果】
【処理の流れ】
- クラスをimportしてロジステック回帰モデルを実装する。
- 学習データをモデルに渡して学習を行う。
【ポイント】
- sklearn.linear_model.LogisticRegressionクラス:ロジスティック回帰モデルを実装できる。
- LogisticRegression.fit()メソッド:第一引数に学習データを指定し、第二引数にラベルを指定する。
53. 予測
52で学習したロジスティック回帰モデルを用い,与えられた記事見出しからカテゴリとその予測確率を計算するプログラムを実装せよ.
【コード】
|
1 2 3 4 5 6 7 8 |
print(f"カテゴリ順:{model.classes_}\n") Y_pred = model.predict(x_valid) print(f"各記事のカテゴリ(ラベル):{y_valid.values}") print(f"各記事のカテゴリ予測:{Y_pred}\n") Y_pred = model.predict_proba(x_valid) print(f"カテゴリの予測確率:\n{Y_pred}") |
【出力結果】

【処理の流れ】
- model.predict()に検証データを入力し、カテゴリを予測する。
- model.predict_proba()を使用して、カテゴリごとの予測確率を求めて出力する。
【ポイント】
- LogisticRegression.predict()メソッド:カテゴリのラベルを予測する。
- LogisticRegression.predict_proba()メソッド:各カテゴリの予測確率を求める。
54. 正解率の計測
52で学習したロジスティック回帰モデルの正解率を,学習データおよび評価データ上で計測せよ.
【コード】
|
1 2 3 4 5 6 7 |
from sklearn.metrics import accuracy_score Y_pred_train = model.predict(x_train) Y_pred_test = model.predict(x_test) print(f"train_accuracy:{accuracy_score(y_train, Y_pred_train)}") print(f"test_accuracy:{accuracy_score(y_test, Y_pred_test)}") |
【出力結果】

【処理の流れ】
- 関数をimportする。
- model.predict()を用いて学習、評価データを予測する。
- accuracy_score()を用いて学習、評価データの正解率をもとめる。
【ポイント】
- sklearn.metrics.accuracy_score()関数:第一引数にラベルを指定し、第二引数にモデルの予測結果を指定する。
55. 混同行列の作成
52で学習したロジスティック回帰モデルの混同行列(confusion matrix)を,学習データおよび評価データ上で作成せよ.
【コード】
|
1 2 3 4 |
from sklearn.metrics import confusion_matrix print(f"学習データの混同行列:\n{confusion_matrix(y_train, Y_pred_train)}\n") print(f"評価データの混同行列:\n{confusion_matrix(y_test, Y_pred_test)}") |
【出力結果】

【処理の流れ】
- 関数をimportする。
- confusion_matrix()を用いて学習、評価データで混同行列を作成する。
【ポイント】
- 混同行列:モデルの分類結果をまとめた行列。
- sklearn.metrics.confusion_matrix()関数:第一引数に正解ラベルを指定し、第二引数にモデルの予測結果を指定することで混同行列を作成する。
56. 適合率,再現率,F1スコアの計測
52で学習したロジスティック回帰モデルの適合率,再現率,F1スコアを,評価データ上で計測せよ.カテゴリごとに適合率,再現率,F1スコアを求め,カテゴリごとの性能をマイクロ平均(micro-average)とマクロ平均(macro-average)で統合せよ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from sklearn.metrics import precision_score, recall_score, f1_score def metrics(y_data, y_pred, ave=None): precision_sco = precision_score(y_data, y_pred, average=ave) recall_sco = recall_score(y_data, y_pred, average=ave) f1_sco = f1_score(y_data, y_pred, average=ave) form = "適合率:{}\n再現率:{}\nF1:{}\n".format(precision_sco, recall_sco, f1_sco) return form print(f"【カテゴリ順】{model.classes_}\n\n{metrics(y_test, Y_pred_test)}") print("【マクロ平均】\n", metrics(y_test, Y_pred_test, "macro")) print("【マイクロ平均】\n", metrics(y_test, Y_pred_test, "micro")) |
【出力結果】

【処理の流れ】
- 適合率、再現率、F1スコアを出力する関数をimportする。
- 評価データのカテゴリごとに、適合率、再現率、F1スコアを求める関数を実装する。
- カテゴリごとの性能をマクロ平均、マイクロ平均で求める。
【ポイント】
- sklearn.metrics.precision_score()関数:適合率が求まる。第一引数にラベルを指定し、第二引数にモデルの予測値を指定する。
- sklearn.metrics.recall_score関数:再現率が求まる。第一引数にラベルを指定し、第二引数にモデルの予測値を指定する。
- sklearn.metrics.f1_score関数:F1スコアが求まる。第一引数にラベルを指定し、第二引数にモデルの予測値を指定する。
- マクロ平均:カテゴリごとに評価指標を求め、全体の評価指標を平均する方法。上記3つの関数のaverage引数に”macro”を指定することで求まる。
- マイクロ平均:混合行列全体で TP、FP、FN を算出して、適合率、再現率、F値を計算する方法。上記3つの関数のaverage引数に”micro”を指定することで求まる。
57. 特徴量の重みの確認
52で学習したロジスティック回帰モデルの中で,重みの高い特徴量トップ10と,重みの低い特徴量トップ10を確認せよ.
【コード】
|
1 2 3 4 5 6 7 8 |
import numpy as np features = x_train.columns.values for c, coef in zip(model.classes_, model.coef_): top_10 = pd.DataFrame(features[np.argsort(-coef)[:10]], columns=[f"重みの高い特徴量トップ10(クラス名:{c})"], index=[i for i in range(1, 11)]) worst_10 = pd.DataFrame(features[np.argsort(coef)[:10]], columns=[f"重みの低い特徴量トップ10(クラス名:{c})"], index=[i for i in range(1, 11)]) print( top_10, "\n"), print(worst_10, "\n", "-"*70) |
【出力結果】

【処理の流れ】
- numpyをimportする。
- 学習データの特徴量を取得する。
- カテゴリごとにモデルの重みを反復させる。
- 最も重みの高い(低い)特徴量を出力する。
【ポイント】
58. 正則化パラメータの変更
ロジスティック回帰モデルを学習するとき,正則化パラメータを調整することで,学習時の過学習(overfitting)の度合いを制御できる.異なる正則化パラメータでロジスティック回帰モデルを学習し,学習データ,検証データ,および評価データ上の正解率を求めよ.実験の結果は,正則化パラメータを横軸,正解率を縦軸としたグラフにまとめよ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score import matplotlib.pyplot as plt #モデル構築、学習(関数) def LR_model_fit(x_data, y_data, c): model = LogisticRegression(C=c) model.fit(x_data, y_data) return model #学習済みモデルを用いて予測する(関数) def LR_pred(x_data, y_data, model): Y_pred_data = model.predict(x_data) accuracy = accuracy_score(Y_pred_data, y_data) return accuracy train_acc = [] valid_acc = [] test_acc = [] #正則化パラメータ c_list = np.linspace(0.001, 0.1, 5) for c in c_list: model = LR_model_fit(x_train, y_train, c) pre_train = LR_pred(x_train, y_train, model) pre_valid = LR_pred(x_valid, y_valid, model) pre_test = LR_pred(x_test, y_test, model) train_acc.append(pre_train) valid_acc.append(pre_valid) test_acc.append(pre_test) print(f"【正則化パラメータ:{c}】\n") print(f"train_accuracy:{pre_train}") print(f"valid_accuracy:{pre_valid}") print(f"test_accuracy:{pre_test}\n") #可視化 plt.plot(c_list, train_acc, label="train", marker="o") plt.plot(c_list, valid_acc, label="valid", marker="o") plt.plot(c_list, test_acc, label="test", marker="o") plt.legend() plt.grid(True) plt.xlabel("Regularization") plt.ylabel("Accuracy") plt.show() |
【出力結果】

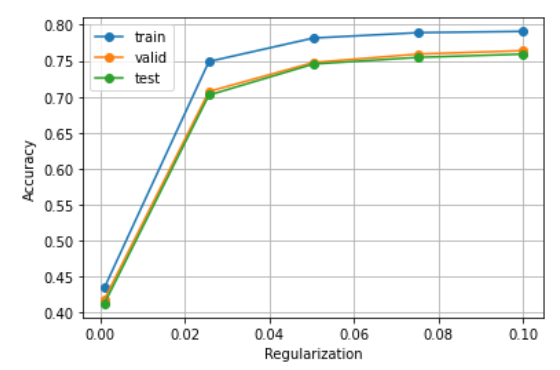
【処理の流れ】
- ロジスティック回帰モデルで学習を行う関数を実装する。
- 学習したモデルを用いて、正解率を計算する関数を実装する。
- モデルのパラメータを変えながら学習データを用いて学習を行う。
- 学習、検証、評価データを用いて予測を行い、正解率をtrain_acc = []、valid_acc = []、test_acc = []それぞれのリストに保存する。
- 正則化パラメータを横軸、正解率を縦軸としてグラフに表示する。
【ポイント】
- ロジスティック回帰のハイパーパラメータC:正則化の強さを表す。デフォルトは1。値が小さくなるほど正則化が強くなる。Cの値を大きく設定することでモデルの精度が向上するが、過学習のリスクが高まる。
59. ハイパーパラメータの探索
学習アルゴリズムや学習パラメータを変えながら,カテゴリ分類モデルを学習せよ.検証データ上の正解率が最も高くなる学習アルゴリズム・パラメータを求めよ.また,その学習アルゴリズム・パラメータを用いたときの評価データ上の正解率を求めよ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from sklearn.model_selection import GridSearchCV params = {"C": [0.001, 0.005, 10]} # グリッドサーチを行う gs_model = GridSearchCV(LogisticRegression(max_iter=1500),params, cv=5, verbose=1) gs_model.fit(x_train, y_train) #最適なモデルを取得する best_gs_model = gs_model.best_estimator_ print("\ntrain_score: {:.2%}".format(best_gs_model.score(x_train, y_train))) print("valid_score: {:.2%}".format(best_gs_model.score(x_valid, y_valid))) print("test_score: {:.2%}".format(best_gs_model.score(x_test, y_test))) |
【出力結果】

【処理の流れ】
- グリッドサーチを行い、最適なモデルを取得する。
- 取得したモデルを用いて、学習、検証、評価データの正解率を求める。
【ポイント】
- sklearn.model_selection.GridSearchCV()クラス:モデルの最適なハイパーパラメータを求めることができる。第一引数に、学習させたいモデルのインスタンスを指定する。第二引数に、使用したいハイパーパラメータの候補を辞書型で指定する。第三引数に、学習データを何分割して交差検証を行うのかを指定する。
- GridSearchCV.fit()メソッド:モデルの学習を行う。第一引数に学習データを指定する。第二引数にラベルを指定する。
- GridSearchCV.best_estimator_属性:最も精度の高かったハイパーパラメータのモデルを返す。
- GridSearchCV.score()メソッド:第一引数に学習データを指定する。第二引数にモデルの予測値を指定する。デフォルトで正解率を返す。
おわりに
以上が、言語処理100本ノック第6章の解説になります。この章では、テキストデータの前処理の流れやロジスティック回帰について学ぶことができました。実装方法は、一通りではないので、自分なりのコードで挑戦してみてはいかかでしょうか。次は、言語処理100本ノック第7章の解説を行っていきます。
K.Y


