
この記事では、言語処理100本ノック第4章の解説に引き続き、言語処理100本ノック第5章の解説を行っていきます。 第5章では、日本語Wikipediaの「人工知能」に関する記事をCaboChaを使って係り受け解析を行い、その結果を用いて処理を行っていきます。それでは、第5章の問題を解きましたので、処理の流れとポイントを踏まえて、解説していきます。
問題と解説
日本語Wikipediaの「人工知能」に関する記事からテキスト部分を抜き出したファイルがai.ja.zipに収録されている. この文章をCaboChaやKNP等のツールを利用して係り受け解析を行い,その結果をai.ja.txt.parsedというファイルに保存せよ.このファイルを読み込み,以下の問に対応するプログラムを実装せよ.
- ai.ja.zipをインストールする。
- ai.ja.zipを解凍しai.ja.txtを取得する。
- CaboChaに必要なソースをそれぞれインストールする。
- CaboChaをインストールする。
- ai.ja.txtを係り受け解析し、ai.ja.txt.parsedに保存する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
#ai.ja.zipをインストールし、解凍する !wget https://nlp100.github.io/data/ai.ja.zip !unzip ai.ja.zip # MeCabをインストール(CaboChaの実行に必要) !apt install mecab libmecab-dev mecab-ipadic-utf8 # CRF++をインストール(CaboChaの実行に必要) FILE_ID = "0B4y35FiV1wh7QVR6VXJ5dWExSTQ" FILE_NAME = "crfpp.tar.gz" !wget 'https://docs.google.com/uc?export=download&id=$FILE_ID' -O $FILE_NAME !tar xvf crfpp.tar.gz %cd CRF++-0.58 !./configure && make && make install && ldconfig %cd .. # CaboChaをインストール FILE_ID = "0B4y35FiV1wh7SDd1Q1dUQkZQaUU" FILE_NAME = "cabocha-0.69.tar.bz2" !wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=$FILE_ID' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=$FILE_ID" -O $FILE_NAME && rm -rf /tmp/cookies.txt !tar -xvf cabocha-0.69.tar.bz2 %cd cabocha-0.69 !./configure -with-charset=utf-8 && make && make check && make install && ldconfig %cd .. #係り受け解析結果をai.ja.txt.parsedに保存 !cabocha -f1 -o ai.ja.txt.parsed ai.ja.txt |
係り受け解析結果の読み込み(形態素)
形態素を表すクラスMorphを実装せよ.このクラスは表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をメンバ変数に持つこととする.さらに,係り受け解析の結果(ai.ja.txt.parsed)を読み込み,各文をMorphオブジェクトのリストとして表現し,冒頭の説明文の形態素列を表示せよ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
class Morph: def __init__(self, line): surface, other = line.split("\t") other = other.split(",") self.surface = surface self.base = other[-3] self.pos = other[0] self.pos1 = other[1] sentences = [] #文リスト morphs = [] #形態素リスト with open("./ai.ja.txt.parsed") as f: for line in f: if line[0] == "*": continue elif line != "EOS\n": morphs.append(Morph(line)) else: #EOS(文末)の場合 sentences.append(morphs) morphs = [] for i in sentences[0]: print(vars(i)) |
【出力結果】

【処理の流れ】
- 指示の通り、Morphクラスを実装する。
- ファイルを1行ずつ読み込んで、以下の条件分岐を行う。
- *(アスタリスク)の行の場合、次の行を読み込む。
- 文末(EOS)でない場合、データをMorphオブジェクトに変換し、morphsリストに保存しておく。
- 文末の場合、morphsリストをsentencesリストに追加する。morphsを空にすることに注意する。(文ごとにまとめるため)
- vars()を使用して、冒頭の説明文の形態素列を表示する。
【ポイント】
- 形態素解析出力フォーマット:形態素の情報が、タブやカンマで区切られているので注意。
- CaboCha出力フォーマット:形態素解析済みデータに対して、文節の区切り情報が付与される。
- アスタリスク:文節の開始位置を意味する。
- EOS(end of sentence):文末を表す。
- Morphオブジェクト:ファイルの各行を指定のフォーマット(形態素)に変換する。
- vars()関数(組み込み):クラスの属性をdict型で返す。
係り受け解析結果の読み込み(文節・係り受け)
40に加えて,文節を表すクラスChunkを実装せよ.このクラスは形態素(Morphオブジェクト)のリスト(morphs),係り先文節インデックス番号(dst),係り元文節インデックス番号のリスト(srcs)をメンバ変数に持つこととする.さらに,入力テキストの係り受け解析結果を読み込み,1文をChunkオブジェクトのリストとして表現し,冒頭の説明文の文節の文字列と係り先を表示せよ.本章の残りの問題では,ここで作ったプログラムを活用せよ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
class Sentence: def __init__(self, chunks): self.chunks = chunks for i, chunk in enumerate(self.chunks): if chunk.dst not in [None, -1]: self.chunks[chunk.dst].srcs.append(i) class Chunk: def __init__(self, morphs, dst, chunk_id): self.morphs = morphs self.dst = dst self.srcs = [] self.chunk_id = chunk_id class Morph: def __init__(self, line): surface, other = line.split("\t") other = other.split(",") self.surface = surface self.base = other[-3] self.pos = other[0] self.pos1 = other[1] sentences = [] #文リスト chunks = [] #節リスト morphs = [] #形態素リスト chunk_id = 0 #文節番号 with open("./ai.ja.txt.parsed") as f: for line in f: if line[0] == "*": if morphs: chunks.append(Chunk(morphs, dst, chunk_id)) chunk_id += 1 morphs = [] dst = int(line.split()[2].replace("D", "")) elif line != "EOS\n": morphs.append(Morph(line)) else: chunks.append(Chunk(morphs, dst, chunk_id)) sentences.append(Sentence(chunks)) morphs = [] chunks = [] dst = None chunk_id = 0 for chunk in sentences[2].chunks: chunk_str = "".join([morph.surface for morph in chunk.morphs]) print(f"文節の文字列:{chunk_str}\n係り先の文節番号:{chunk.dst}\n") |
【出力結果】

【処理の流れ】
- 指示通り、Chunkオブジェクトを作成する。
- 係り元文節番号を取得するために、文節を1文でまとめるSentenceクラスを作成する。
- 文、文節、形態素をまとめるために空のリストを作成する。
- 問40の処理と異なる点を以下で説明する。
- if line[0] == “*”:では、形態素列を文節で区切り、Chunkオブジェクトに変換し、chunksリストにまとめる。文節番号の更新と、morphsの初期化を行うことに注意。
- 文末(EOS)が来た場合、Chunkオブジェクトをchunksに追加し、1文の文節をchunksにまとめる。
- chunksをSentenceオブジェクトに変換し、sentencesリストにまとめる。morphs、chunks、dst、chunk_idを初期化することに注意。
- 1文目の最初の文節は、係っている文節がない(係り先文節番号が-1なので)ので、2文目の文節の文字列と、係り先番号を出力する。
【ポイント】
- sentences:文リスト(要素:Sentenceクラス)
- Sentenceクラス:文節リスト(chunks)を持つ。係り元文章番号を取得する。(1文の文節)
- chunks:文節リスト(要素:Chunkクラス)
- Chunkクラス:文節ごとの形態素リスト(morphs)、係り先文章番号、係り元文章番号、文章番号を持つ。
- Morphクラス:ファイルの各行の形態素を持つ。
- 各文の文節ごとに形態素をまとめること。(形態素を文節単位でまとめ、文節を文単位でまとめる)
係り元と係り先の文節の表示
係り元の文節と係り先の文節のテキストをタブ区切り形式ですべて抽出せよ.ただし,句読点などの記号は出力しないようにせよ.
【コード】
|
1 2 3 4 5 6 7 |
for chunk in sentences[2].chunks: if int(chunk.dst) == -1: continue else: surf = "".join([morph.surface for morph in chunk.morphs if morph.pos != "記号"]) next_surf = "".join([morph.surface for morph in sentences[2].chunks[int(chunk.dst)].morphs if morph.pos != "記号"]) print(f"{surf}\t{next_surf}") |
【出力結果】

【処理の流れ】
- 問41の実装結果をもとに、冒頭の文の文節で反復処理を行う。
- 係り先文節がない場合(係り先文節番号が-1の場合)は、スキップする。
- 係り先文節がある場合、文節内の各表層形を連結させる。
- 係り先文節についても同じ処理を行う。
- 係り元の文節と係り先の文節のテキストをタブで区切って出力する。
【ポイント】
- surf変数:文節内のテキストを連結させる。
- nex_surf変数:係り先文節内のテキストを連結させる。
名詞を含む文節が動詞を含む文節に係るものを抽出
名詞を含む文節が,動詞を含む文節に係るとき,これらをタブ区切り形式で抽出せよ.ただし,句読点などの記号は出力しないようにせよ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 |
for chunk in sentences[2].chunks: if int(chunk.dst) == -1: continue else: surf = "".join([morph.surface for morph in chunk.morphs if morph.pos != "記号"]) next_surf = "".join([morph.surface for morph in sentences[2].chunks[int(chunk.dst)].morphs if morph.pos != "記号"]) pos_noun = [morph.surface for morph in chunk.morphs if morph.pos == "名詞"] pos_verb = [morph.surface for morph in sentences[2].chunks[int(chunk.dst)].morphs if morph.pos == "動詞"] if pos_noun and pos_verb: print(f"{surf}\t{next_surf}") |
【出力結果】

【処理の流れ】
- 問42の追加点のみ説明する。
- 名詞を含む文節の表層形を取得する。
- 動詞を含む係り先文節の表層形を取得する。
- pos_noun、pos_verbリストに表層形が含まれていれば、両文節をタブ区切りで出力する。
【ポイント】
- if pos_noun and pos_verb:文:両変数がTrueであれば出力する。
係り受け木の可視化
与えられた文の係り受け木を有向グラフとして可視化せよ.可視化には,Graphviz等を用いるとよい.
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#pydotをインストール !pip install pydot #日本語フォントをインストール !apt install fonts-ipafont-gothic import pydot_ng as pydot pair = [] for chunk in sentences[2].chunks: if int(chunk.dst) == -1: continue else: surf = "".join([morph.surface for morph in chunk.morphs if morph.pos != "記号"]) next_surf = "".join([morph.surface for morph in sentences[2].chunks[int(chunk.dst)].morphs if morph.pos != "記号"]) #文節のリストに係り先番号をindexに指定。その文節の形態素リストを取得 pair.append((surf, next_surf)) img = pydot.Dot() img.set_node_defaults(fontname="MS Mincho") for s, t in pair: img.add_edge(pydot.Edge(s, t)) img.write_png("./result44.png") |
【出力結果】
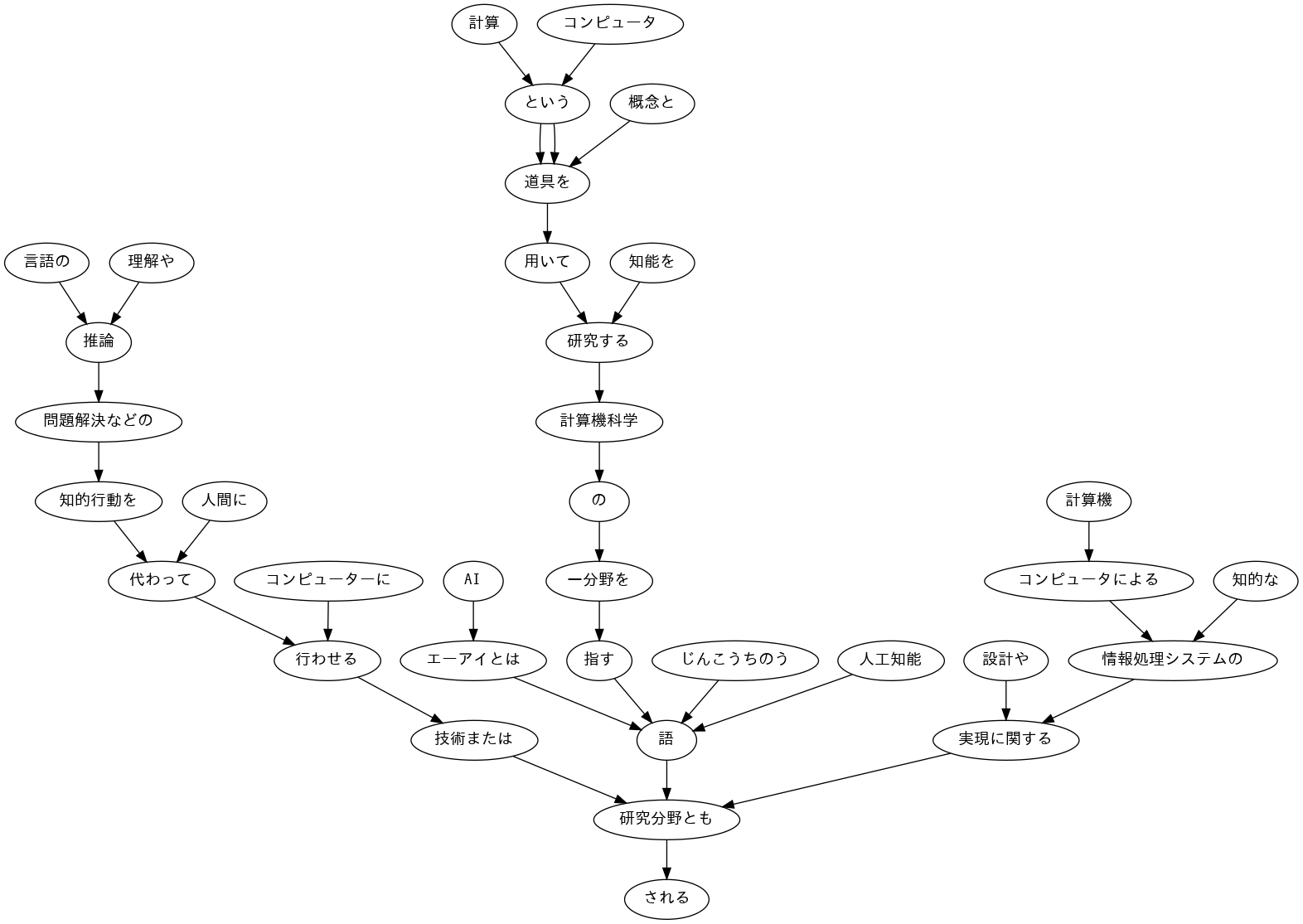
【処理の流れ】
- pydot, fonts-ipafont-gothicをインストールする。
- pydotをimportする。
- 問42のコードを用いる。
- surfとnext_surfをpairリストに追加する。
- Dotインスタンスを作成し、有効グラフで表示するフォントの設定を行う。
- エッジを追加していき、有効グラフ完成させる。
- 有効グラフをファイルに書き込む。
【ポイント】
- 有効グラフ:頂点と向きを持つ辺(矢印)によって構成されたグラフ。
- fonts-ipafont-gothic:日本語に対応するフォントのパッケージ。
- pydot:グラフを描画するツール。
- pydot.Dot.set_node_defaults()メソッド:有効グラフのフォントを設定する。ここでは、日本語に対応している”MS Mincho”を指定している。
- pydot.Edge()クラス:有効グラフを作成する。第一引数に、ノードを指定する。第二引数に、第一引数で指定したノードに続くノードを作成する。
- pydot.Dot.add_edge()メソッド:有効グラフにエッジを追加する。
- pydot.Dot.write_png()メソッド:有効グラフをファイルに保存する。
動詞の格パターンの抽出
今回用いている文章をコーパスと見なし,日本語の述語が取りうる格を調査したい. 動詞を述語,動詞に係っている文節の助詞を格と考え,述語と格をタブ区切り形式で出力せよ. ただし,出力は以下の仕様を満たすようにせよ.
- 動詞を含む文節において,最左の動詞の基本形を述語とする
- 述語に係る助詞を格とする
- 述語に係る助詞(文節)が複数あるときは,すべての助詞をスペース区切りで辞書順に並べる
このプログラムの出力をファイルに保存し,以下の事項をUNIXコマンドを用いて確認せよ.
- コーパス中で頻出する述語と格パターンの組み合わせ
- 「行う」「なる」「与える」という動詞の格パターン(コーパス中で出現頻度の高い順に並べよ)
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
with open("./result45.txt", "w") as f: for i in range(len(sentences)): for chunk in sentences[i].chunks: for morph in chunk.morphs: if morph.pos == "動詞": particles = [] for src in chunk.srcs: particles += [morph.surface for morph in sentences[i].chunks[src].morphs if morph.pos == "助詞"] if len(particles) > 1: particles = set(particles) particles = sorted(list(particles)) form = " ".join(particles) print(f"{morph.base}\t{form}", file=f) |
【出力結果】
【コード】
|
1 2 3 4 5 6 |
#コーパス中で頻出する述語と格パターンの組み合わせ !cat ./result45.txt | sort | uniq -c | sort -nr | head -n 5 #「行う」「なる」「与える」という動詞の格パターン !cat ./result45.txt |grep "行う" | sort |uniq -c | sort -nr |head -n 5 !cat ./result45.txt |grep "なる" | sort |uniq -c | sort -nr |head -n 5 !cat ./result45.txt |grep "与える" | sort |uniq -c | sort -nr |head -n 5 |
【出力結果】


【処理の流れ】
- 動詞を含む文節を対象に反復処理を行う。
- 動詞を含む文節の係り元文節で反復処理を行い、助詞を取得する。
- 動詞に係る助詞が複数あるとき、助詞を辞書順に並べ、スペースで区切る。
- 最後は、動詞と動詞に係る助詞をタブ区切りでファイルに書き込む。
【ポイント】
- for src in chunk.srcs:文:係り元文節から助詞を取得する。
- particle += ~ 行:文節内の次の動詞が出現するまで、動詞に係る助詞を保存しておく。
- particle = [] :再度、文節内に動詞が出現したとき、保存していた助詞をリセットする。
- sorted()関数(組み込み):辞書順に単語を並べ替える。単語の優先順位は、アルファベット>ひらがな>カタカナ>漢字。
- cat:ファイルを表示する。
- grep:指定した文字列が含まれている行を出力する。
- uniq -c:重複した行数を表示する。sortしてからuniqを使用する必要がある。
- sort -nr:降順に並び替える
- head -n:ここでは、先頭から5行を表示している。
動詞の格フレーム情報の抽出
45のプログラムを改変し,述語と格パターンに続けて項(述語に係っている文節そのもの)をタブ区切り形式で出力せよ.45の仕様に加えて,以下の仕様を満たすようにせよ.
- 項は述語に係っている文節の単語列とする(末尾の助詞を取り除く必要はない)
- 述語に係る文節が複数あるときは,助詞と同一の基準・順序でスペース区切りで並べる
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
with open("./result46.txt", "w") as f: for i in range(len(sentences)): for chunk in sentences[i].chunks: for morph in chunk.morphs: if morph.pos == "動詞": particles = [] items = [] for src in chunk.srcs: particles += [morph.surface for morph in sentences[i].chunks[src].morphs if morph.pos == "助詞"] items += ["".join([morph.surface for morph in sentences[i].chunks[src].morphs if morph.pos != "記号"])] if len(particles) > 1: if len(items) > 1: particles = sorted(set(particles)) items = sorted(set(items)) particles_form = " ".join(particles) items_form = " ".join(items) print(f"{morph.base}\t{particles_form}\t{items_form}", file=f) |
【出力結果】

【処理の流れ】
- 前半は、問45と同じなので、省略。
- for src in chunk.srcs:文内に、items変数を追加し、係り元文節の単語列(項)を取得する。
- 文節に助詞、項が複数含まれている場合は、助詞、項をスペースで区切り辞書順に並び替える。
- 最後は、動詞と動詞に係っている助詞、項をタブ区切りでファイルに書き込む。
【ポイント】
- items = [] :再度、文節内に動詞が出現したとき、保存していた項をリセットする。
機能動詞構文のマイニング
動詞のヲ格にサ変接続名詞が入っている場合のみに着目したい.46のプログラムを以下の仕様を満たすように改変せよ.
- 「サ変接続名詞+を(助詞)」で構成される文節が動詞に係る場合のみを対象とする
- 述語は「サ変接続名詞+を+動詞の基本形」とし,文節中に複数の動詞があるときは,最左の動詞を用いる
- 述語に係る助詞(文節)が複数あるときは,すべての助詞をスペース区切りで辞書順に並べる
- 述語に係る文節が複数ある場合は,すべての項をスペース区切りで並べる(助詞の並び順と揃えよ)
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
with open("./result47.txt", "w") as f: for sentence in sentences: for chunk in sentence.chunks: for morph in chunk.morphs: if morph.pos == "動詞": for src in chunk.srcs: predicates = [] if len(sentence.chunks[src].morphs) == 2 and sentence.chunks[src].morphs[0].pos1 == "サ変接続" and sentence.chunks[src].morphs[1].surface == "を": predicates = "".join([sentence.chunks[src].morphs[0].surface, sentence.chunks[src].morphs[1].surface, morph.base]) particles = [] items = [] for src in chunk.srcs: particles += [morph.surface for morph in sentence.chunks[src].morphs if morph.pos == "助詞"] item = "".join([morph.surface for morph in sentence.chunks[src].morphs if morph.pos != "記号"]) item = item.rstrip() if item not in predicates: items.append(item) if len(particles) > 1: if len(items) > 1: particles = sorted(set(particles)) items = sorted(set(items)) particles_form = " ".join(particles) items_form = " ".join(items) predicate = " ".join(predicates) print(f"{predicates}\t{particles_form}\t{items_form}", file=f) |
【出力結果】

【処理の流れ】
- 前半は、問46と同じなので、省略する。
- 「サ変接続名詞+を(助詞)」で構成された文節が、動詞に係っていれば、「サ変接続名詞+を+動詞の基本形」の形で、predicatesに保存する。
- 問46と同様に、predicates(述語)に係る助詞、項を取得していく。
- 最後は、述語と述語に係っている助詞、項をタブ区切りでファイルに書き込む。
【ポイント】
- if len(sentence.chunks[src].morphs) == 2~:文:「サ変接続名詞+を(助詞)」で構成される文節を取得する必要があるため、文節の単語数は2である。
- サ変接続の確認:MeCabの出力フォーマットより、品詞細分類1の場所から確認できる。
名詞から根へのパスの抽出
文中のすべての名詞を含む文節に対し,その文節から構文木の根に至るパスを抽出せよ. ただし,構文木上のパスは以下の仕様を満たすものとする.
- 各文節は(表層形の)形態素列で表現する
- パスの開始文節から終了文節に至るまで,各文節の表現を”
->“で連結する
【コード】
|
1 2 3 4 5 6 7 8 9 |
sentence = sentences[2] for chunk in sentence.chunks: for morph in chunk.morphs: if "名詞" in morph.pos: path = ["".join(morph.surface for morph in chunk.morphs if morph.pos != "記号")] while chunk.dst != -1: path.append("".join(morph.surface for morph in sentence.chunks[chunk.dst].morphs if morph.pos != "記号")) chunk = sentence.chunks[chunk.dst] print("->".join(path)) |
【出力結果】

【処理の流れ】
- 各文の文節で反復させ、文節内に名詞が含まれていれば処理を行う。
- pathで、名詞を含む文節内の単語を連結させる。
- 文節の係り先がなくなるまで、係り先文節の形態素列(表層形の)をpathに追加していく。
- 最後は、path内の要素を->で連結させて出力する。
【ポイント】
- 構文木:係り受け解析結果を木構造で表したもの。
- while chunk.dst != -1:文:係り先がなくなるまで処理を行う。(係り先番号が-1の文節は、係り先文節がない)
名詞間の係り受けパスの抽出
文中のすべての名詞句のペアを結ぶ最短係り受けパスを抽出せよ.ただし,名詞句ペアの文節番号がiとj(i<j)のとき,係り受けパスは以下の仕様を満たすものとする.
- 問題48と同様に,パスは開始文節から終了文節に至るまでの各文節の表現(表層形の形態素列)を”
->“で連結して表現する - 文節iとjに含まれる名詞句はそれぞれ,XとYに置換する
また,係り受けパスの形状は,以下の2通りが考えられる.
- 文節iから構文木の根に至る経路上に文節jが存在する場合: 文節iから文節jのパスを表示
- 上記以外で,文節iと文節jから構文木の根に至る経路上で共通の文節kで交わる場合: 文節iから文節kに至る直前のパスと文節jから文節kに至る直前までのパス,文節kの内容を”
|“で連結して表示
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
from itertools import combinations import re sentence = sentences[2] nouns = [] for i, chunk in enumerate(sentence.chunks): if [morph for morph in chunk.morphs if morph.pos == "名詞"]: nouns.append(i) for i, j in combinations(nouns, 2): path_I = [] path_J = [] while i != j: if i < j: #文節iの構文木経路上に文節jが存在する場合 path_I.append(i) i = sentence.chunks[i].dst else: #文節iの構文木経路上に文節jがない場合 path_J.append(j) j = sentence.chunks[j].dst if len(path_J) == 0: # 文節Iの構文木上に文節Jが存在する場合 X = "X" + "".join([morph.surface for morph in sentence.chunks[path_I[0]].morphs if morph.pos != "名詞" and morph.pos != "記号"]) Y = "Y" + "".join([morph.surface for morph in sentence.chunks[i].morphs if morph.pos != "名詞" and morph.pos != "記号"]) chunk_X = re.sub("X+", "X", X) chunk_Y = re.sub("Y+", "Y", Y) path_ItoJ = [chunk_X] + ["".join(morph.surface for n in path_I[1:] for morph in sentence.chunks[n].morphs)] + [chunk_Y] print(" -> ".join(path_ItoJ)) else: # 文節Iの構文木上に文節Jが存在しない場合 X = "X" + "".join([morph.surface for morph in sentence.chunks[path_I[0]].morphs if morph.pos != "名詞" and morph.pos != "記号"]) Y = "Y" + "".join([morph.surface for morph in sentence.chunks[path_J[0]].morphs if morph.pos != "名詞" and morph.pos != "記号"]) chunk_X = re.sub("X+", "X", X) chunk_Y = re.sub("Y+", "Y", Y) chunk_k = "".join([morph.surface for morph in sentence.chunks[i].morphs if morph.pos != "記号"]) path_X = [chunk_X] + ["".join(morph.surface for n in path_I[1:] for morph in sentence.chunks[n].morphs if morph.pos != "記号")] path_Y = [chunk_Y] + ["".join(morph.surface for n in path_J[1: ]for morph in sentence.chunks[n].morphs if morph.pos != "記号")] print(" | ".join(["->".join(path_X), "->".join(path_Y), chunk_k])) |
【出力結果】

【処理の流れ】
- ライブラリをimportする
- 文節を反復させ、名詞を含む文節のインデックス番号をnounsに格納する。
- 名詞句ペアの文節番号i、jを反復させる。
- while文では、文節iの構文木根に至る経路上に文節jが存在する場合とそれ以外で条件分岐を行い、それぞれ名詞を含む文節番号とその文節の係り先文節番号を取得し、それぞれのpathリストに格納する。
- 文節iから構文木の根に至る経路上に文節jが存在する場合を説明する。(if len(path_J == 0:)
- 文節iとjに含まれる名詞句をXとYに置換する。
- 残りは、文節iと文節jの構文木経路の間のパスを取得し、連結させて出力する。
- 文節iから構文木の根に至る経路上に文節jが存在しない場合を説明する。(2つ目のelse:)
- 前半の条件分岐(if len(path_J == 0:)と同様に、文節iとjに含まれる名詞句をXとYに置換する。
- 文節iと文節jの構文木の根に至る経路上で交わる文節kを取得する。
- 文節iと文節jで、文節kに至るまでのパスを取得する。
- 文節iから文節kに至るまでのパスと、文節jから文節kに至るまでのパスと、文節kの内容をそれぞれ” | “で連結させて、出力する。
【ポイント】
- 問44で作成した有効グラフを見ると、出力結果をイメージしやすい。
- itertools.combinations()関数:組み合わせを求める。第一引数に、組み合わせを求めたい要素を指定する。第二引数に、何通りの組み合わせを求めるのかを指定する。
- while文:if文、else文内の変数i, jは名詞を含む文節の係り先の文節番号を格納する。つまり、次の反復処理の際にi < jがFalseになる場合、文節iの係り受け構文木の経路上に文節jが含まれないという事を意味する。
- path_I, path_J変数:名詞を含む文節の構文木経路を格納している。
- re.sub()関数:第一引数に、正規表現を指定する。第二引数に、置換する文字列を指定する。第三引数に、置換される文字列を指定する。
- if len(path_J) == 0:文:文節iの構文木の根に至る経路上に文節jが存在する場合。chunk_Xは、文節iの構文木経路の先頭の文節。chunk_Yは、文節iの構文木経路の末尾の文節を表す。
- 2つ目のelse文:chunk_Xは、文節iの構文木経路の先頭の文節。chunk_Yは、文節jの構文木経路の先頭の文節。chunk_kが、文節i, jの構文木経路の末尾の文節を表す。
おわりに
以上が、言語処理100本ノック第5章の解説になります。第4章の形態素解析で学んだことを活かし、係り受け解析の意味を理解しながら解き終えることができました。また、この章から問題のレベルが上がっているように感じました。実装方法は、一通りではないので、自分なりのコードで挑戦してみてはいかかでしょうか。次は、言語処理100本ノック第6章の解説を行っていきます。
K.Y
