
概要
- 今回は、基礎的な文書検索手法である「ベクトル空間法」を紹介します
- 現在では世の中に様々な検索エンジンが存在します。それらは様々なアルゴリズムを組み合わせ、検索文字列から妥当な結果を導き出すように調整されています。
- 「ベクトル空間法」単体では、そこまでの強力なアルゴリズムを含んでいないので、ある程度の検索性能を得ることしかできません。
- しかし、単純な仕組みでそこそこの成果を出すことができるので、ちょっとしたものを作りこむ際には重宝します。
- 以下では、その考え方について、簡単に解説します。
文書のベクトル表現
- 「ベクトル空間法」という名前の由来通り「ベクトル」を使います。文書をベクトル化し、ベクトル間の類似関係を用いて検索を行う手法です。
- そもそも文書を処理する際に、文字データのまま扱うのは非常に困難です。不可能ではありませんが、現実的でないような膨大な計算時間がかかる場合があります。
- それを現実的に処理するために、文書をベクトルに変換して数値データとして扱えるようにします。
- まず、文書をベクトルとして表現する方法を説明します。ここでは、基本的な方法として、「BOW」と「TF-IDF」の二つを提示します。
BOW(Bag of Word)
- 文書中の単語の出現頻度(出現回数)を要素とするベクトルです。
- 例えば、次のような例です。
「長い髪の黒い少女と、黒い眼の大きな少女」
| あの | この | … | 黒い | 大きな | 長い | … | 髪 | 神 | 眼 | … | 少女 |
| 0 | 0 | 2 | 1 | 1 | 1 | 0 | 1 | 2 |
TF-IDF
- 単語の出現頻度に重み(重要度)を付けます
- 重みは、検索対象であるすべての文書のうち、その単語が出現している文書の数からから計算されます
- なお、名前の由来である「TF」と「IDF」は次のように定義されています
| TF | Term Frequency | 文書中の単語の出現頻度 |
| IDF | Inverse Document Frequency | 単語が出現する文書数の逆数 |
- 計算式で書くと次のようになります
計算式
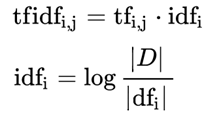

※ここでは基本的な計算式を示しておきます。実用においては調整されている場合があります。
- この計算結果により、それぞれの文書中の個々の単語に数値が与えられます。そしてその値を要素としたベクトルを作成することで、文書をベクトル化することができます。
文書中の特徴的な単語
- 「特徴的な単語」とは、その文書を代表する(説明する)単語です
- 検索の場合には、すべての単語は均等に扱うのではなく、特徴的な単語を用いることで、より適切な文書を順位付けすることができます
- その意味では、BOWよりはTF-IDFの方が、より特徴的な単語を表すことができているといえます。
- もちろん、TF-IDFの計算結果が特徴語を正確に表しているとは限りませんが、単純な計算式で、それなりの効果が出ていると言えます。
ベクトル空間法による検索
- 以下では、文書をTF-IDFによってベクトル化したものとします。
- ベクトル化された文書との照合を行うためには、検索文字列もベクトル化する必要があります。検索文字列を一つの文書とみなすことで、前述の計算式を適用してベクトル化することができます。
- これによって、検索対象の文書群も検索文字列も同じ多次元空間(次元数は、全単語の数)上のベクトルとして表現されます。
- あとはベクトル同士の比較を行います。
- ベクトル間の類似度は、ベクトル間の角度の小さい(ベクトルが近い)方が類似度が大きいものとします。例えば次のような3つのベクトルを考えてみます。
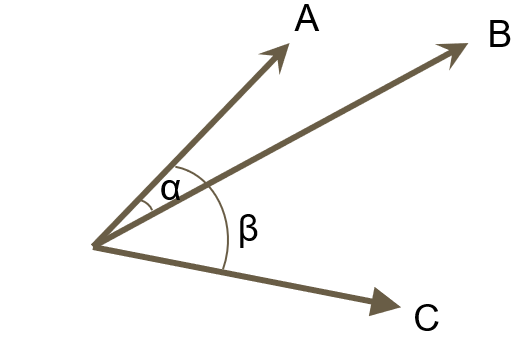
- 角度αが角度βより小さいので、文書Aに近いのは文書Bということがわかります。
- 実際には、ベクトル間の角度を計測する必要はありません。
- cos類似度(コサイン類似度)を用いて、角度が小さいほど類似度が大きな値になるように計算を行います。
計算式
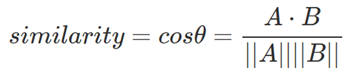
※「A・B」はベクトルAとBの内積、||A||はベクトルAの大きさ
- 検索文とすべての文書の類似度を計算し、その類似度の大きな順に検索結果とします
- (すべての文書に対して、この計算式をそのまま適用すると、検索結果を得るまでの時間が大きくなります。実際には、様々な工夫を凝らすことで、検索時の計算量を減らします。例えば、文書のベクトルの大きさは、検索文に関係なく事前に計算できるので、その値を保持しておけば、検索のたびごとに計算する必要はありません。)
リンク:検索関連
- Gensim:自然言語処理関連(TF-IDFなど)の処理を含むフリーのPythonライブラリ
- Whoosh:全文検索用ライブラリ、Python
- elastcsearch:Pythonから検索エンジンElasticsearchを操作できるようにするライブラリ
(M.H)

