
概要
今回はTransformerがどのように学習し、機械翻訳を実現しているのかについて解説します。
Transformerとは
Transformerは2017年にGoogleが発表しました。内部にAttentionというメカニズムを持ち、機械翻訳タスクにおいて、公開当時最先端であったSeq2seqなどよりも高いスコアをマークしました。また、その後登場するBERTやGPT-2といったモデルのベースとなる技術です。
アーキテクチャ
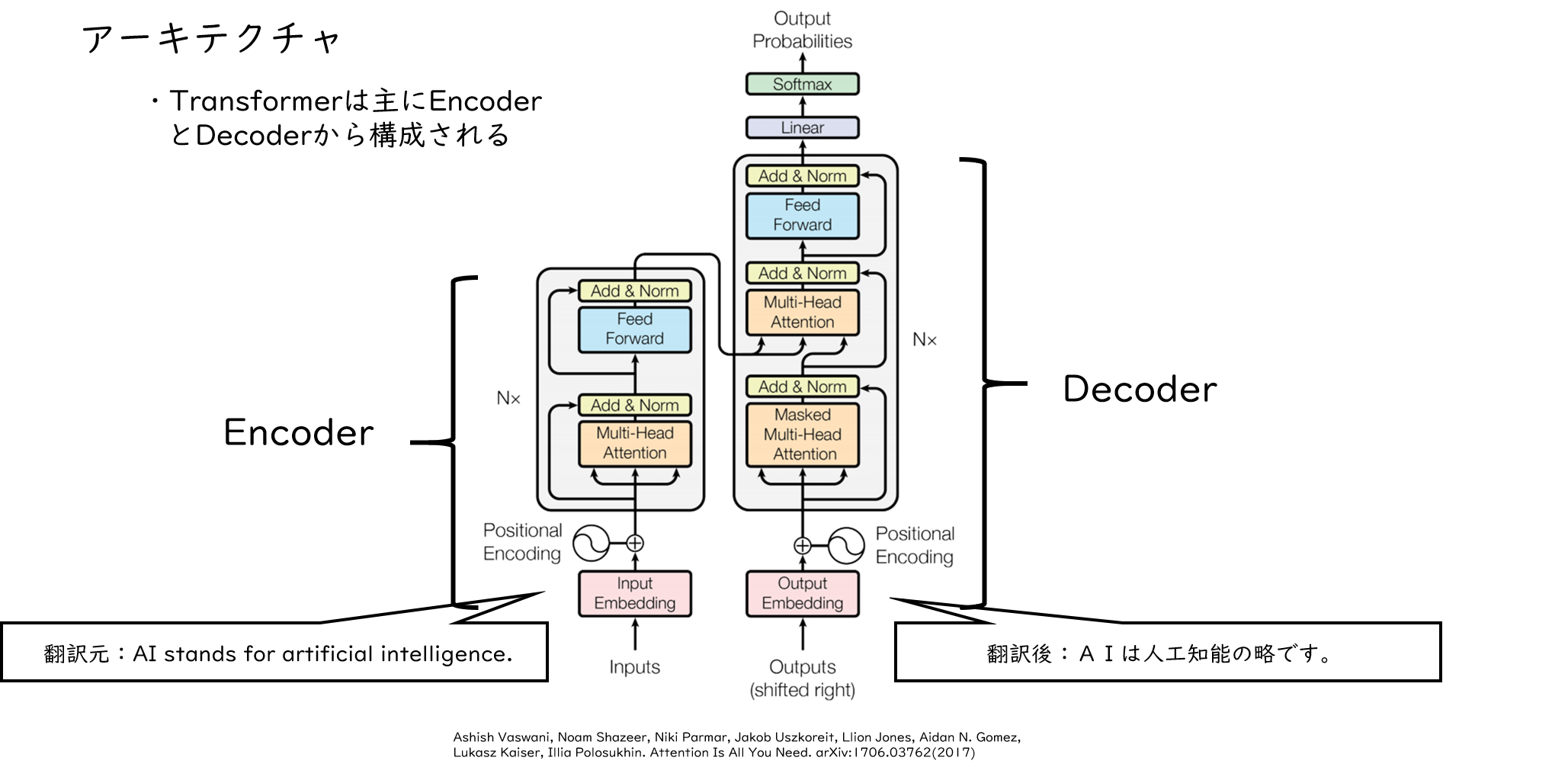
次にTransformerのアーキテクチャについて説明します。Transformerは主にEncoderとDecoderから構成されており、Encoderは翻訳元の文の特徴を抽出し、DecoderはEncoderから得られた翻訳元の文の特徴から翻訳後の文を生成する役割を持っています。学習する際は、図のようにEncoderに翻訳元の文、Decoderに翻訳後の文を入力しますが、原文のまま入力するのではなく、前処理を施した後に入力されます。
前処理
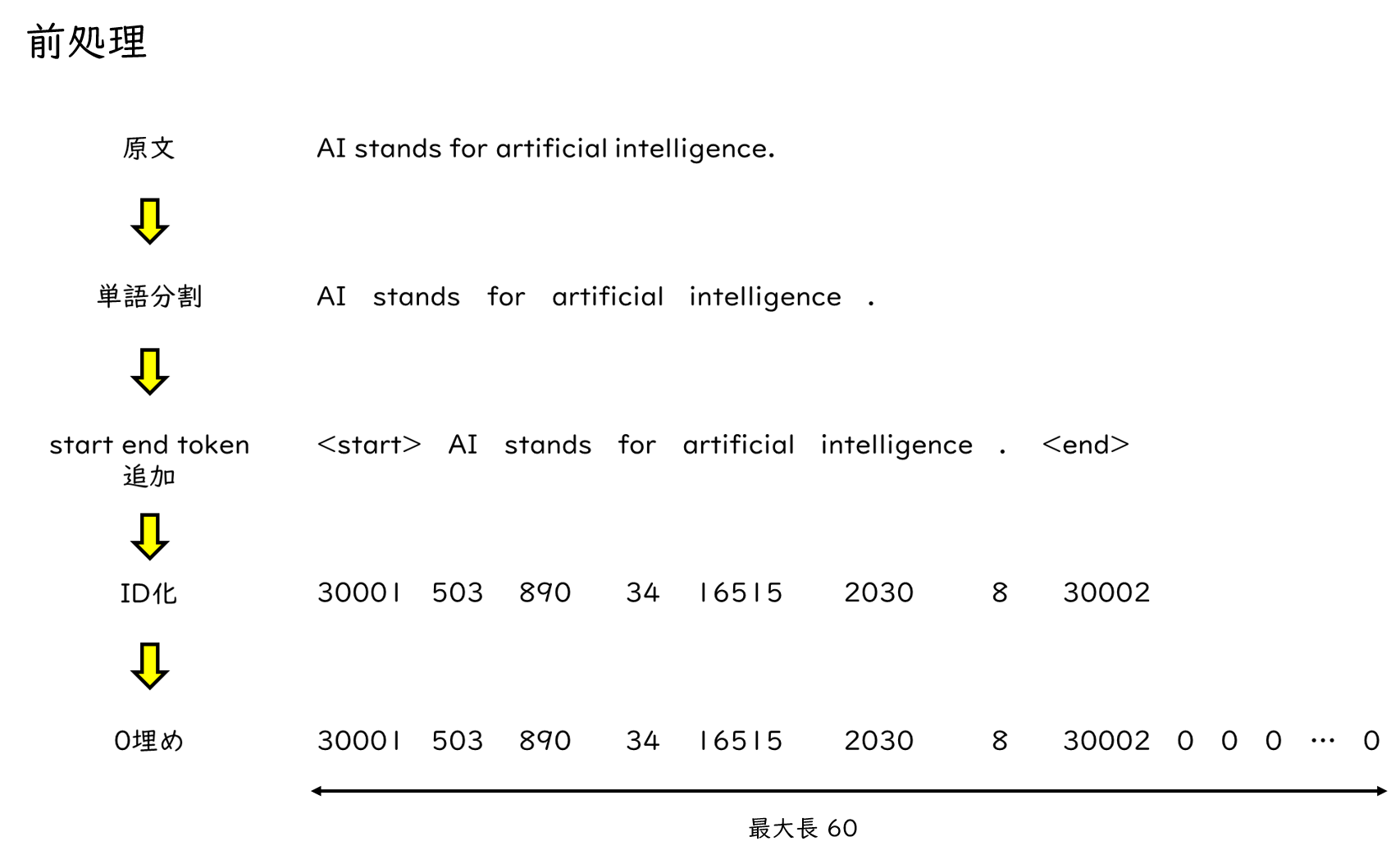
では、どのような前処理を行うかというと、図のようになります。まず原文を単語分割します。続いて、文章の開始と終了を表すstartとendトークンを付与します。ここまでできたら今度は単語をIDに置き換えます。各単語に一つずつユニークなIDが割り当てられ、この例ではAIなら503といったIDが割り当てられています。最後に0埋めを行うことで、文章の長さを揃えます。文によって単語の数がバラバラだとTransformerで処理することが難しいため、あらかじめ最大長を定めておきます。以上のような前処理を経て、Transformerに入力するシーケンスが作成されます。
Input Embedding
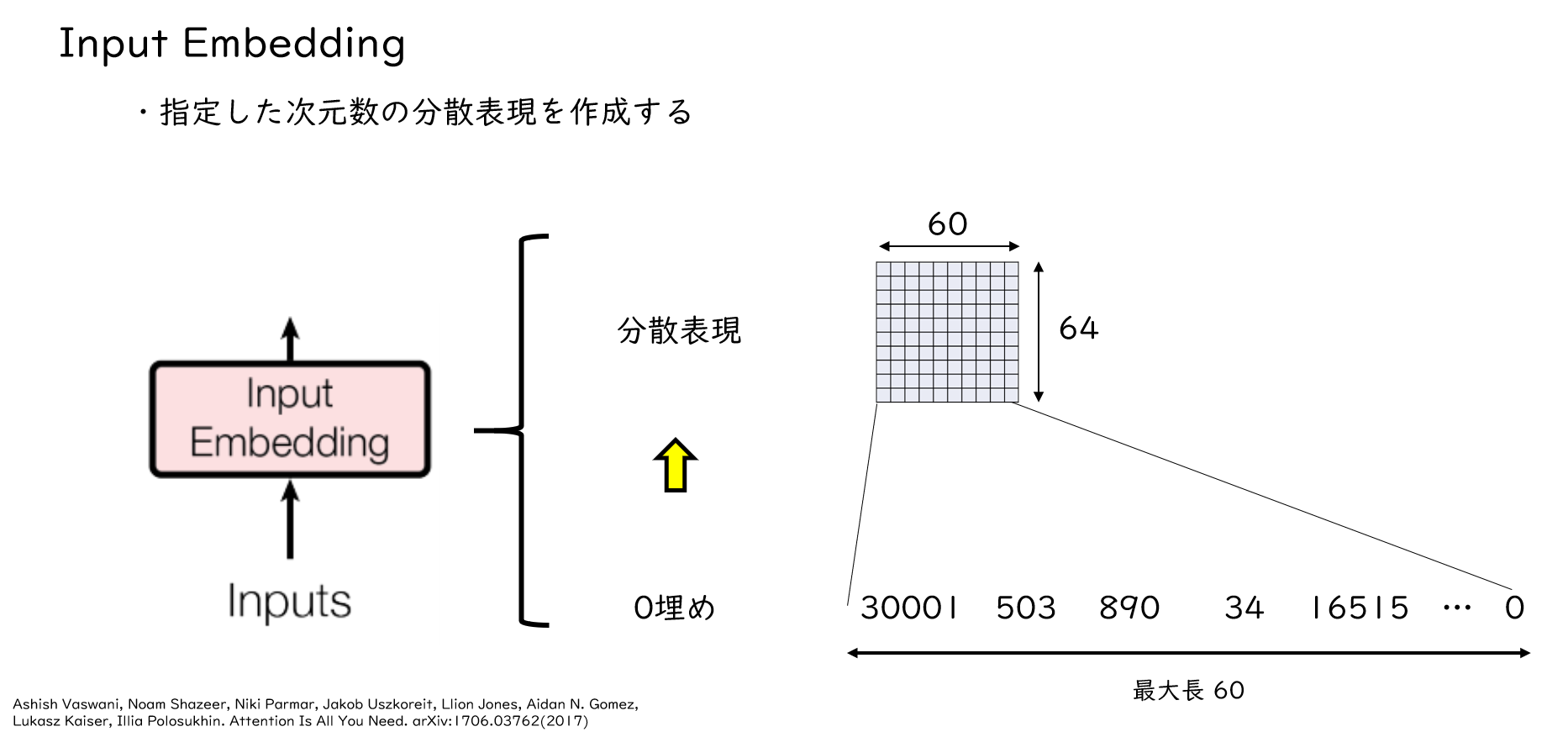
では、Transformerに前処理を施したシーケンスを入力していきましょう。まずシーケンスはInput Embeddingに入力され、単語の分散表現を作成します。今回扱う例では各単語を64次元の分散表現で表します。右図にあるように、「30001」とか「503」とかありますが、これら各単語に対して64次元のベクトルに変換します。このようにすることで、各単語の特徴をベクトルで表すことができます。
Positional Encoding
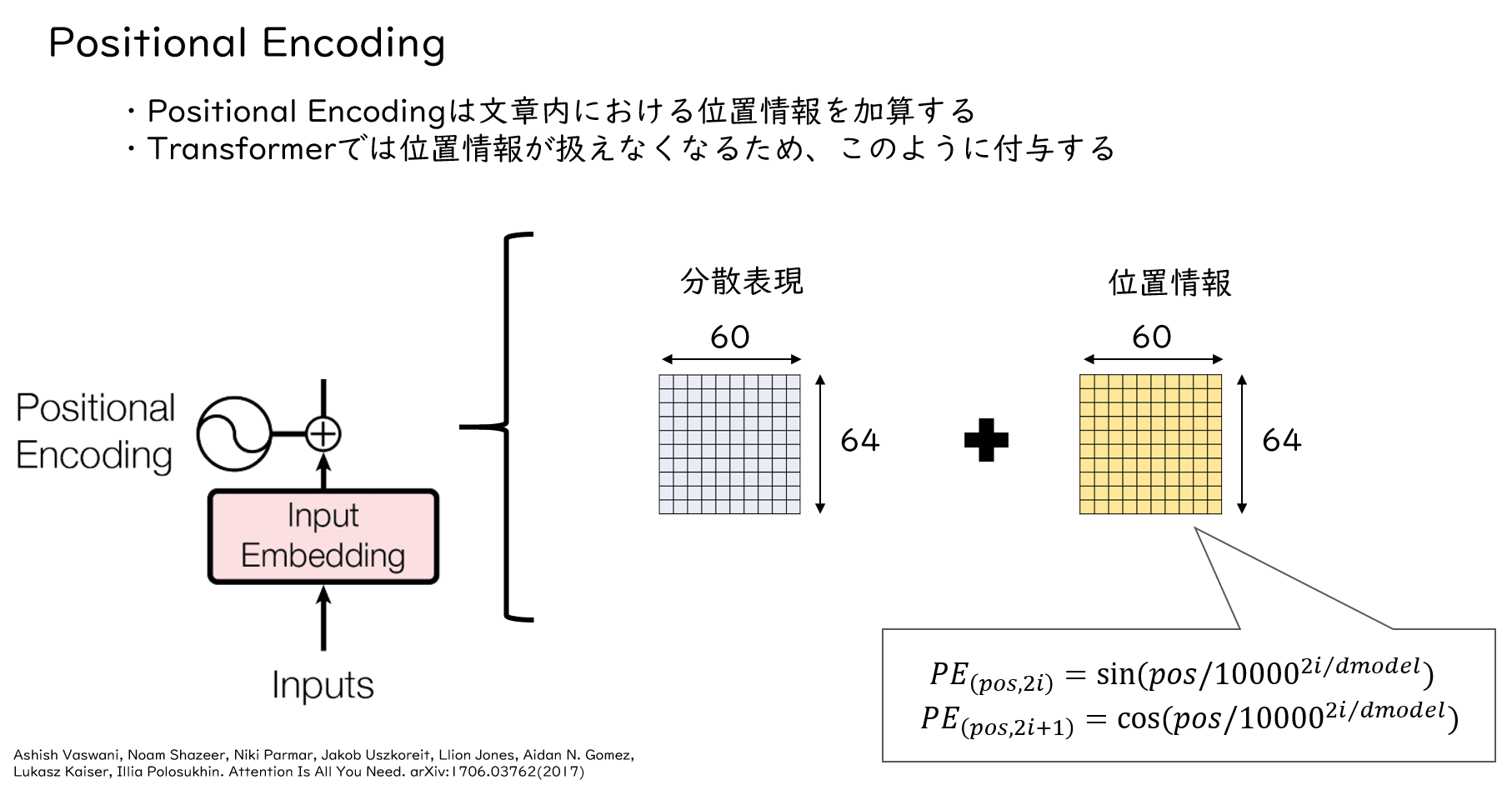
Input Embeddingで分散表現を作成した後は、Positional Encodingで単語の位置情報を付与します。
TransformerはRNNのような再帰やCNNのような畳み込みがないため、文にける単語の相対的な位置が含まれません。そのため、positional encodingで文中における単語の相対位置を付与します。図のように、分散表現と同形状の位置情報ベクトルが加算されます。Positional encodingの式は右下のとおりです、シーケンスの偶数要素にはsin関数を適用し、奇数要素にはcos関数を適用することで単語の相対的な位置情報を付与しています。
Encoder
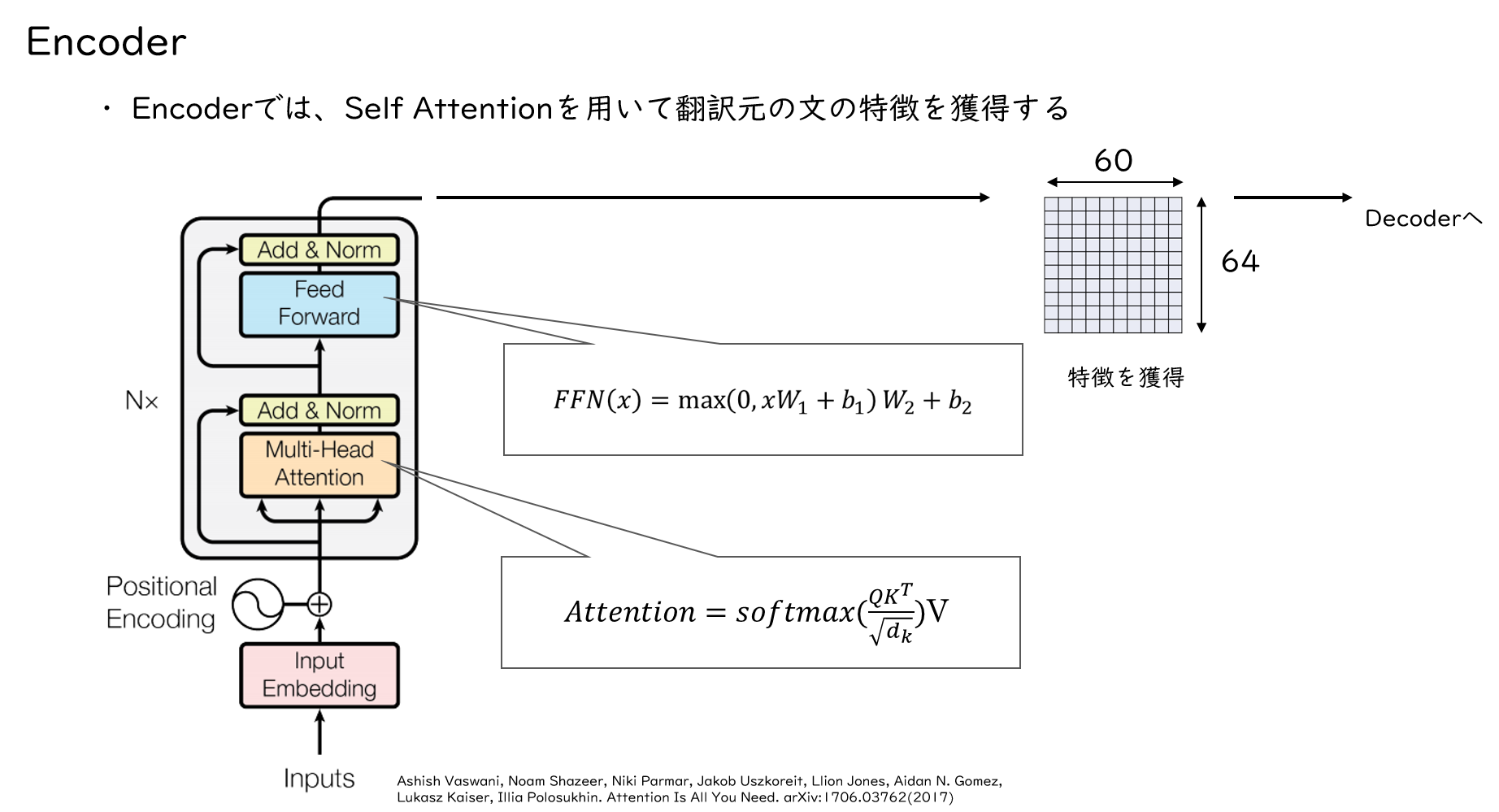
続いて、入力シーケンスはEncoderに入力されます。EncoderにはMulti-Head AttentionとPoint-wise Feed-Forward Networkがあります。Multi-Head Attentionでは、文章における単語間の関係性を学習します。実際には、これらの機構を持つEncoderがいくつも積み重なっています。
Self Attention
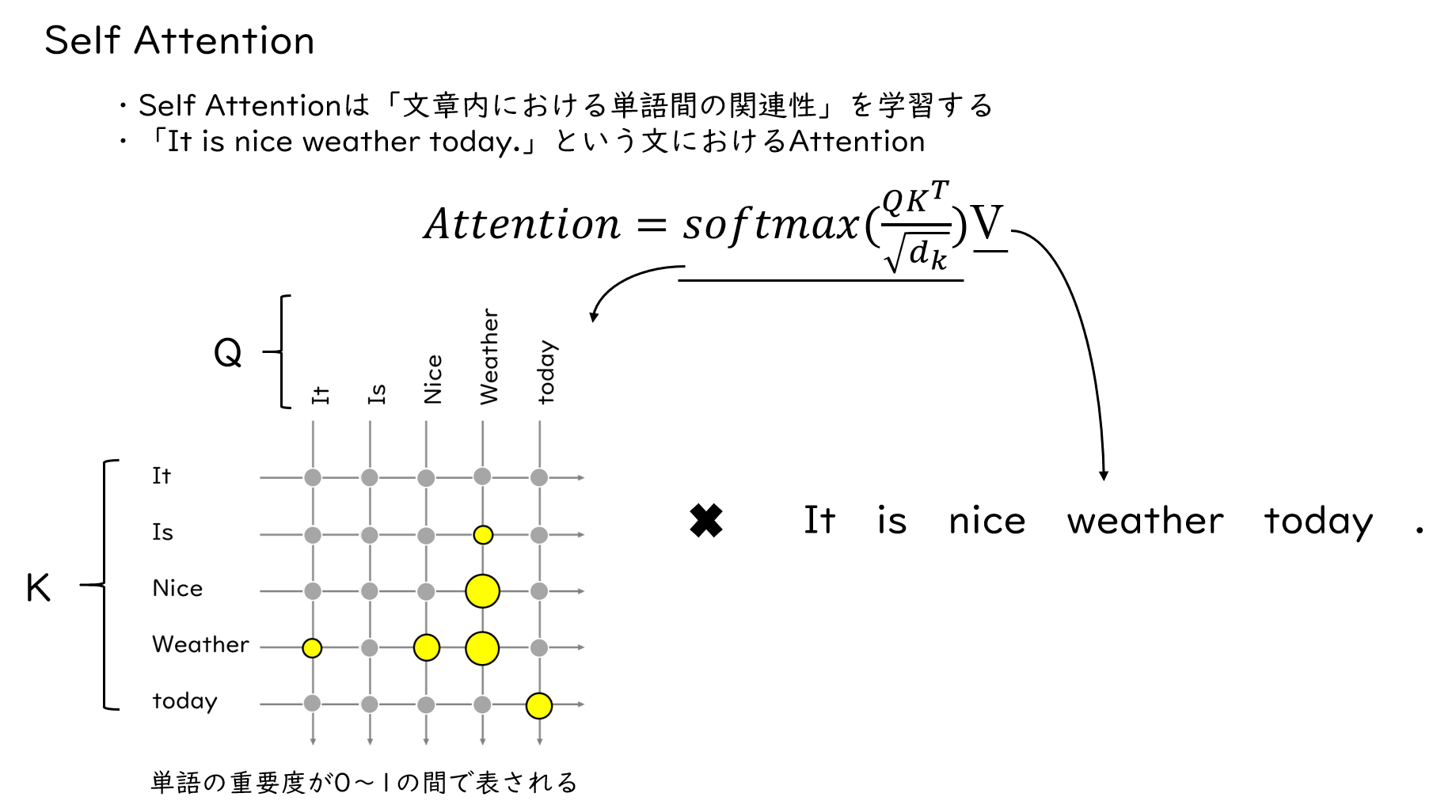
ここでAttentionというものが登場しましたが、これについて解説します。Attentionは、その名の通り文章中のどの単語に注意を向けるかを学習する機構です。そして、EncoderにはSelf Attentionというものがあります。翻訳すると”自己注意”と訳したりもできますが、これは自己に対するAttentionを算出しています。Attentionの式にあるQ,K,Vは同じ文から作られた文ベクトルですが、ここは説明上、文で表しています。例えば「It is nice weather today.」のself Attentionは、図のようなイメージで、単語間の関連性を計算します。そこから得られた関連性はsoftmaxで0~1の間の数値で表されます。この0~1の数値は、文章内においてどの単語が重要かを示す重みだと考えてください。最終的に、この重みと文ベクトルを掛け合わせることで、翻訳元の文の特徴を得ます。
Multi Head Attention
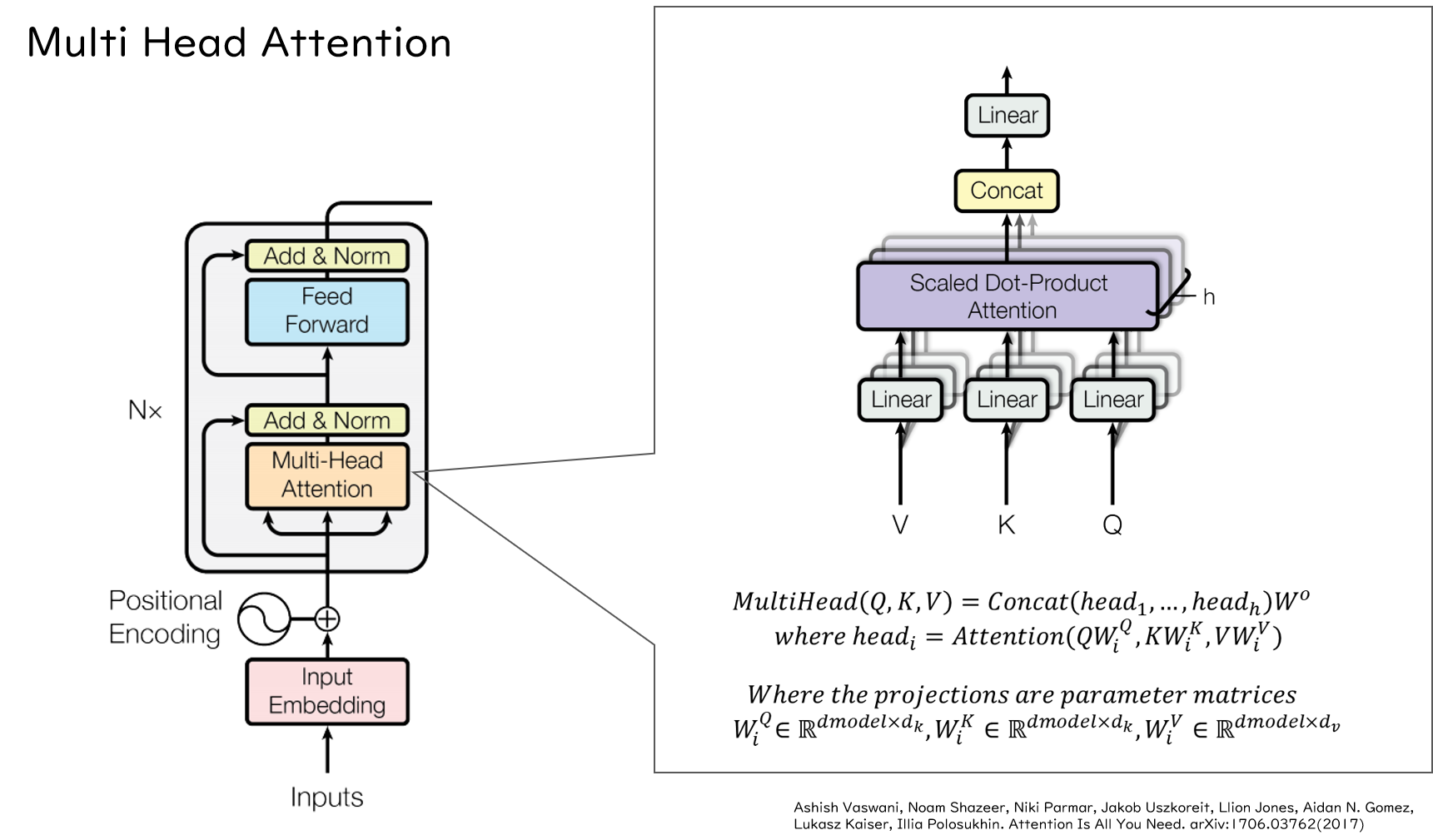
実際には、AttentionはMulti Head Attentionという複数のAttentionからなる機構としてTransformer内に存在します。論文では図のように書かれていますが、直感的には理解しにくいかと思いますので、別の図を用いて解説します。
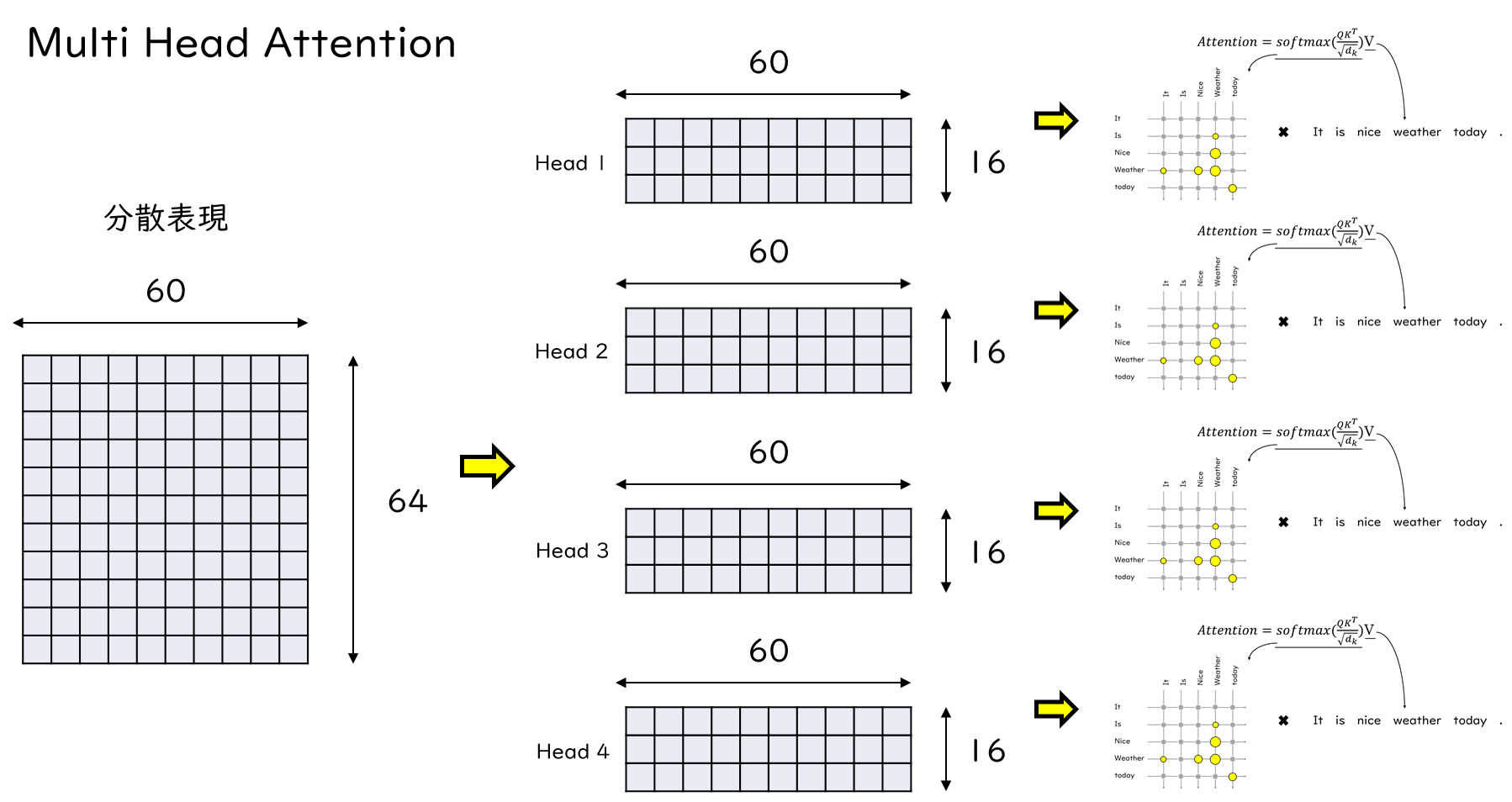
先ほど登場した分散表現ですが、横軸の60は文章の長さでした。それに対して各単語が64次元で表現されていました。Multi Head Attentionでは、それがMulti Headの数だけ分割されます。そして、各々のAttentionが計算されます。

また、Attentionを複数にすることで、各々のAttentionが異なる位置の異なる部分に注意を向け、単語間の関連性を処理することができます。赤で囲ってある部分が顕著ですが、単語間の関連性が強く出ているところとそうでないところがあるのがわかります。
Decoder
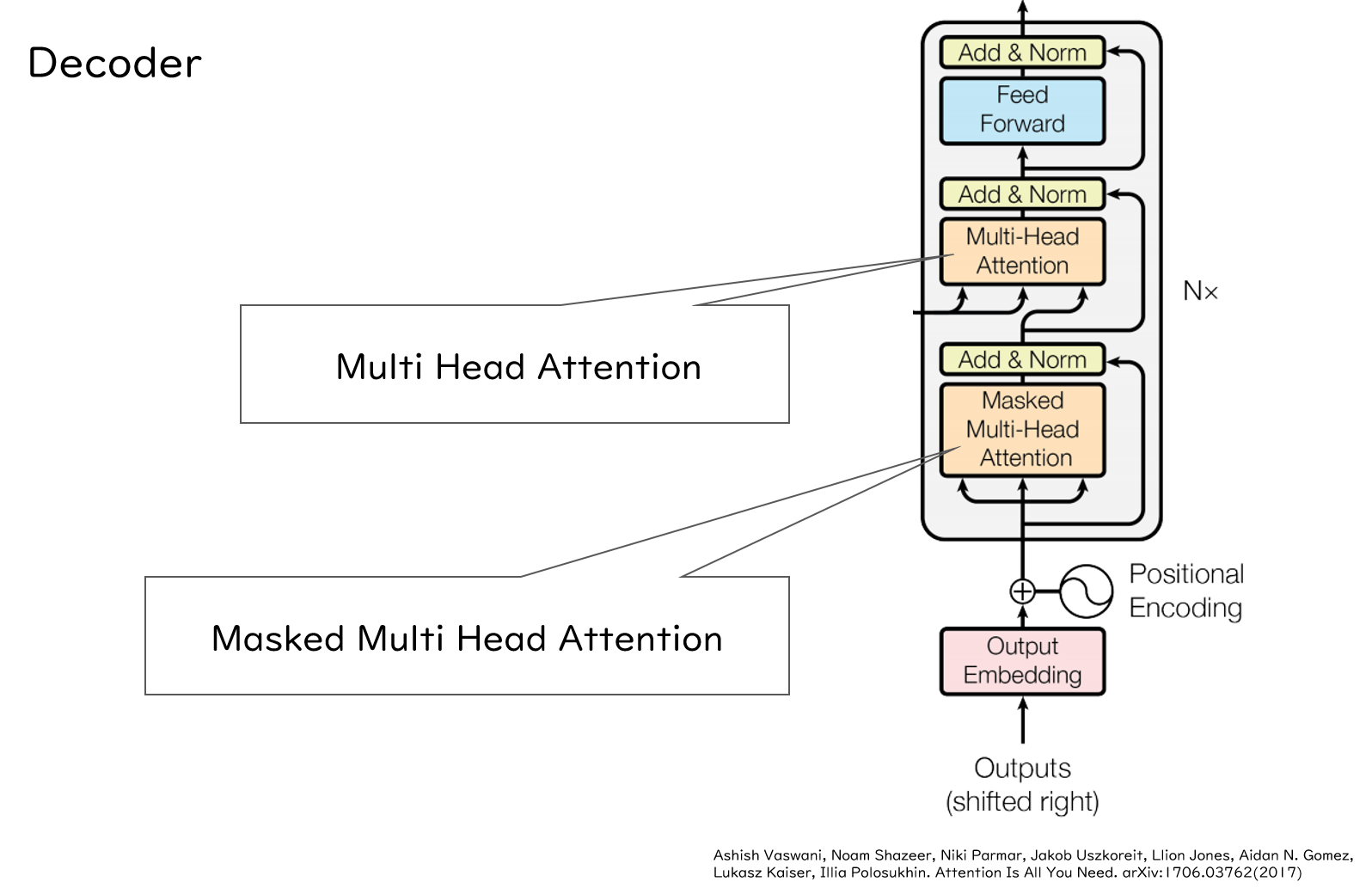
続いてDecoderですが、DecoderもEncoderとPositional Encodingまでは一緒です。Encoderと異なるのは、Multi Head Attentionが2つあることです。さらに、そのうち一つはMasked Multi Head Attentionになっています。また、もう一つのMulti Head AttentionはEncoderで獲得した翻訳元の文の特徴情報を用いて、Attentionを算出しています。
Masked AttentionとSource-Target Attention
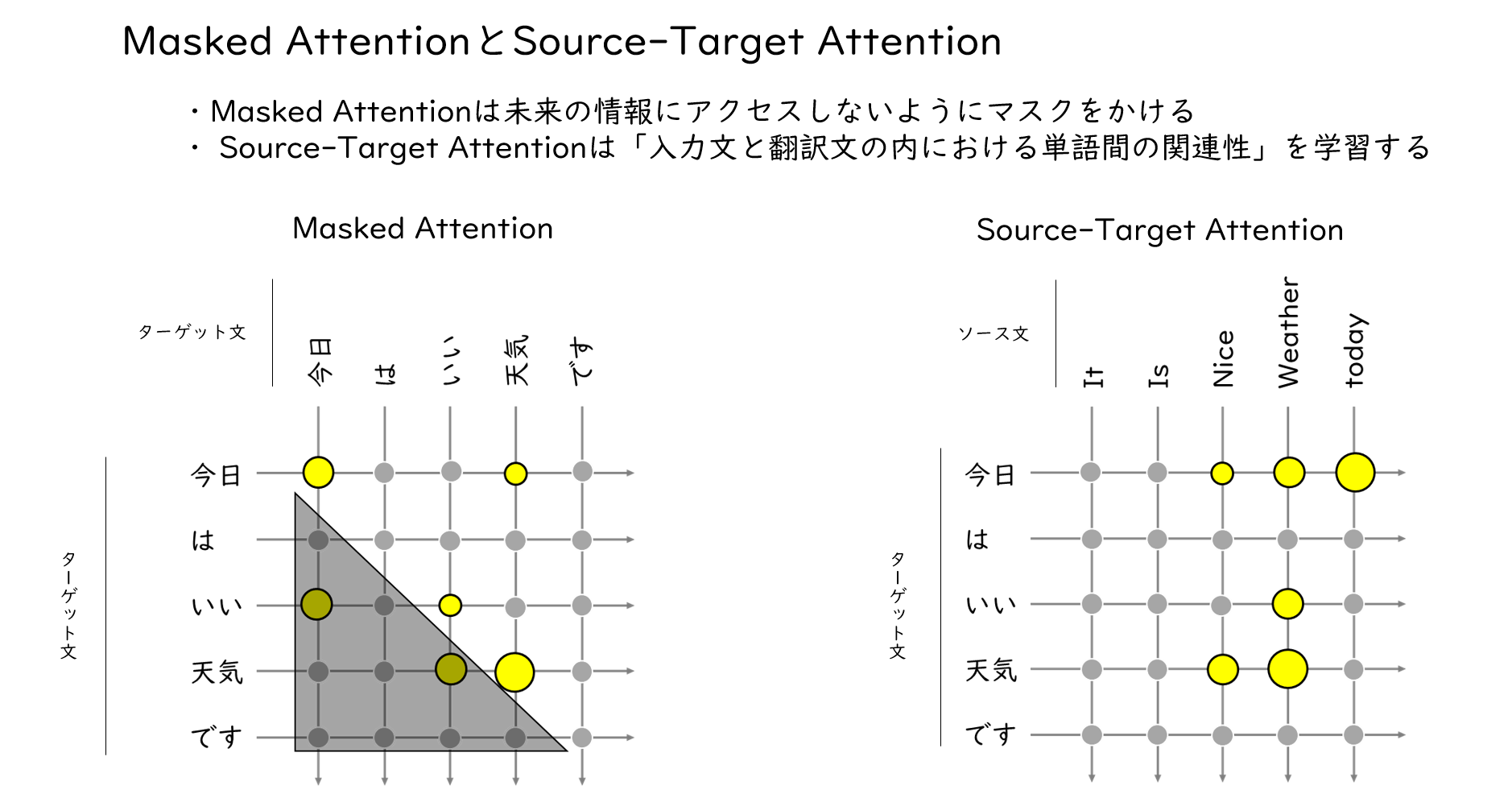
Masked Attentionでは、Decoderに入力された翻訳後の文と文のAttentionを計算しています。その時に、三角で暗転させてある部分をマスクして、Attentionを0にしてしまいます。なぜこうするかというと、翻訳文を生成するときのことを考えてみましょう。翻訳文を生成するときは、前の単語から順番に生成していくのですが、その時には当然、後に続く単語がなんであるかは分かりません。なので、今わかっている単語よりも後ろの部分のAttentionを無視するためにMasked Attentionというものを用います。続いて、Source-Target Attentionですが、これは自己のAttentionではなく、翻訳元の文と翻訳後の文のAttentionを計算しています。イメージは右図のようになりますが、実際にはソース文がEncoderからの出力になります。
おわりに
今回はTransformerがどのように学習を行っているのかについて解説しました。次回はソースコードを参照しながら、具体的にどのような処理が行われているのかを見ていきたいと思います。
(K. K)

