
先日、オンラインで開催されたIJCAI-PRICAI2020に参加してきましたので、会議の様子や興味深かった研究について報告します。
IJCAI-PRICAI2020について

IJCAI-PRICAI2020は第29回IJCAIと第17回PRICAIの合同で行われました。それぞれ歴史のある会議です。
- IJCAIは、人工知能の様々な分野の研究者が集まる人工知能学会分野でトップの学術会議で、AAAIと並び人工知能関連の学会の中でも最難関とされています。
- PRICAIは、環太平洋諸国における社会的および経済的に重要な分野でのAI理論、技術、およびそれらの応用に焦点を当てた隔年の国際イベントです。
会議概要
- 開催形式:オンライン
- 日時:1/7,8(チュートリアル、ワークショップ)
1/11~15(メインカンファレンス) - 参加者数:1,972人
- 総論文数:769本
会議の基本情報は上記の通りになります。今回、私は国際会議に参加するのが初めてだったので、1/7,8はチュートリアルに参加し、1/11~15はメインカンファレンスに参加しました。合計7日間ということもあって非常にボリュームがありました。
- メイントラック:591件
- 招待講演:8件
- Award トーク:3件
- パネル:5件
- ワークショップ:35件
- チュートリアル:47件
- コンペティション:3件
- スポンサーセッション
- その他:Japanese Cultural Event
開催されたイベントは上記の通りで、メイントラックの他に招待講演やパネルがありました。招待講演は世界各地の大学の先生がそれぞれの専門分野に関する発表、パネルはフィンテックやcovid-19など一つのテーマに対して専門の研究者たちが集まって討論をする内容でした。
チュートリアルは、学生向けの入門的な講座という位置づけですが、世界各地の大学の先生や研究者が解説してくれて、専門性も高かったです。チュートリアルで扱われた内容やその詳細は下記のURLで見ることができます。当日のビデオが公開されているものもあるので、興味がある方はご覧ください。また、ワークショップについてもビデオが公開されているのもがあるので、そちらも合わせてご覧ください。
- Tutorial Details:https://ijcai20.org/tutorials/
- Workshops:https://ijcai20.org/workshops/

また、もともと日本で開催する予定だったので、日本の文化を紹介するなど国際学会ならではのイベントも行われました。
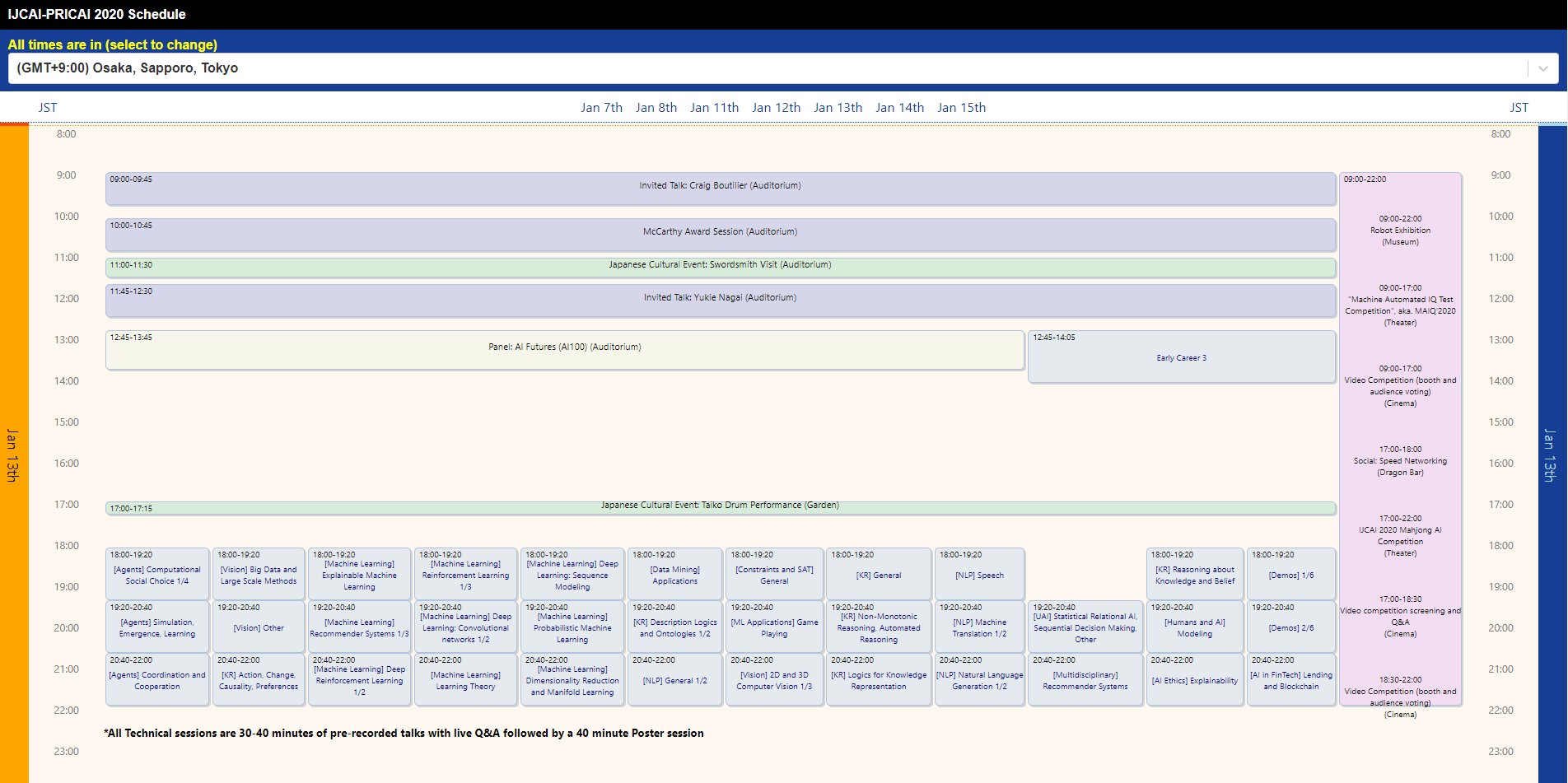
今回はオンライン開催ということで、プログラムスケジュールも変則的になっていました。日本の場合は、もともと日本開催予定だったこともあり、プログラムの開始が朝9時スタートでしたが、14時から18時くらいまでは空白の時間があります。おそらく、全世界の人が同時に発表を見るため、発表時間が深夜などに偏ってしまうことを防ぐためだと思います。そういうこともあって、毎日プログラムが終わるのが22時、23時頃になっていたので、後半は体力的につらかったです。
- IJCAI-PRICAI 2020 Schedule:https://static.ijcai.org/ijcai-pricai-2020-schedule/
論文投稿数
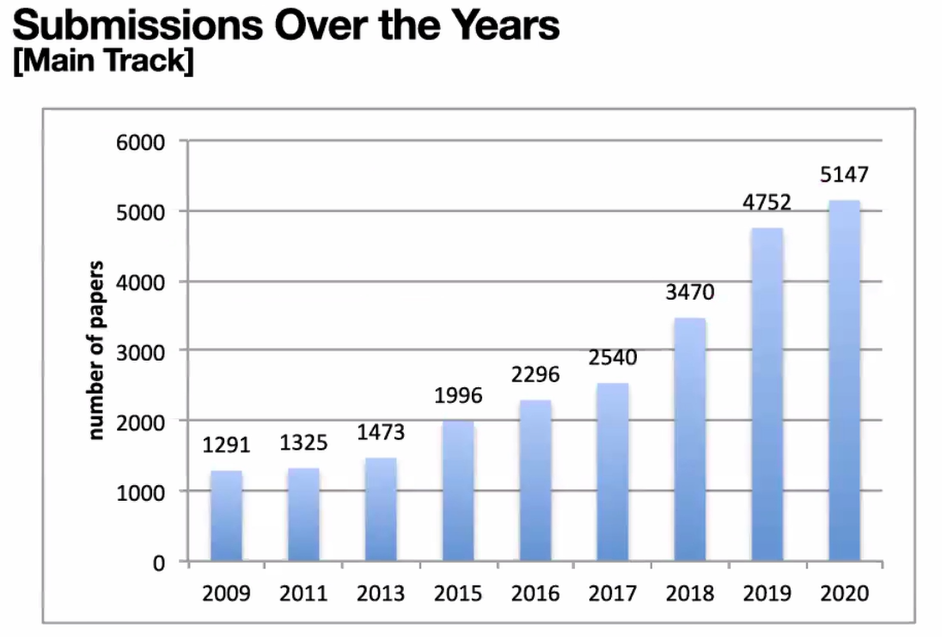
毎年の論文応募者数ですが、増加傾向にあり、今年は5,147件となりました。そのうち採択された論文数は591件であり、採択率11.5%ときわめて低い採択率となりました。
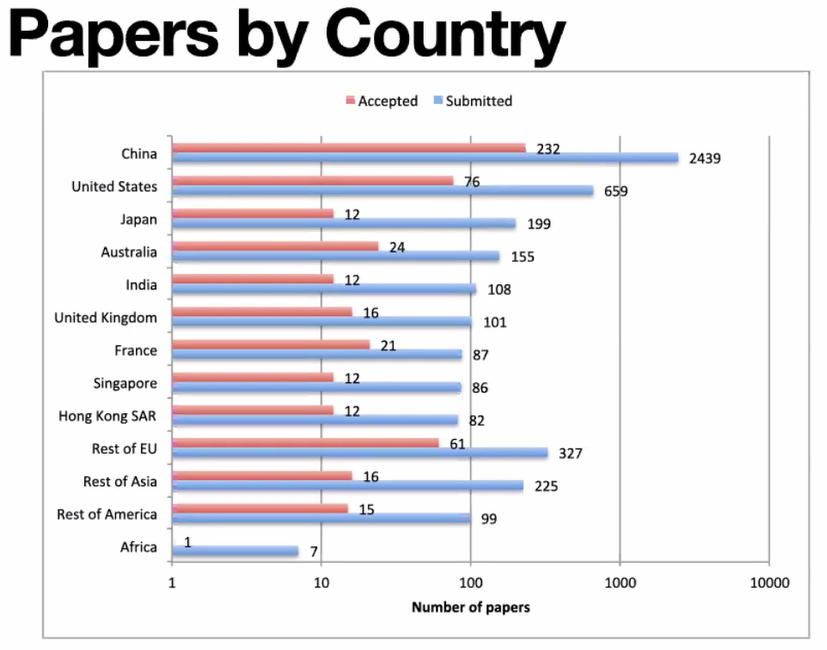
国別の論文応募数と採択数ですが、中国からの論文数が圧倒的に多かったです。応募数の桁が一つとびぬけていて、その他の国の応募数を合計しても中国にかなわないくらいの数でした。日本は199本と応募数はそれなりにありますが、採択数が12と他国に比べて採択率が低いと思われます。
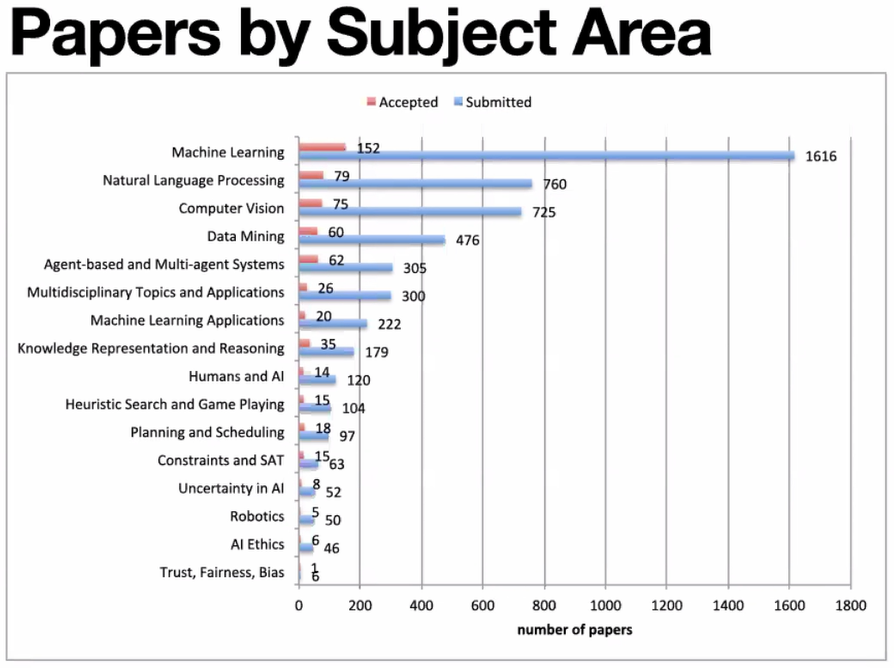
各分野における論文応募数と採択数ですが、機械学習、自然言語処理、コンピュータービジョンの順に論文数が多いです。大体、各分野10%を採択しており、応募数に応じた結果となっているように思えます。
Virtual Chair
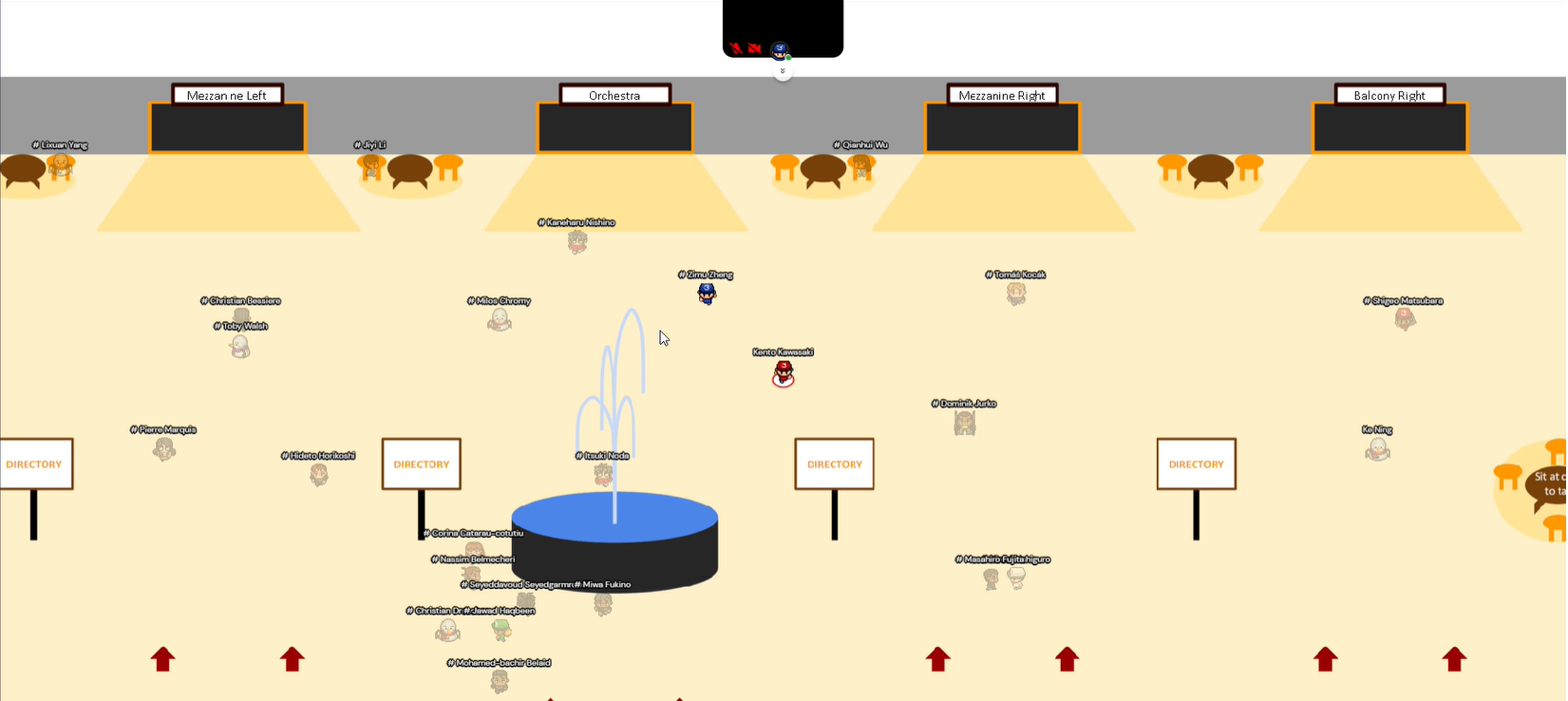
元々は横浜で開催の予定でしたが、コロナ禍ということもあり、Virtual Chairという仮想会場で学会が行われました。これはwebからアクセスできて、アバターで会場を回りながら発表を見たり、参加者と交流したりなどすることができます。

これはメインホールの様子です。もともとは横浜で開催予定だったので、東京、横浜、京都など日本の街並みを模した会場になっていました。

画面の中央に新幹線がありますが、これは会場内をすばやく移動するためのショートカットになっていました。新幹線の上下にいくつか並んでいるのは、ポスターセッションです。
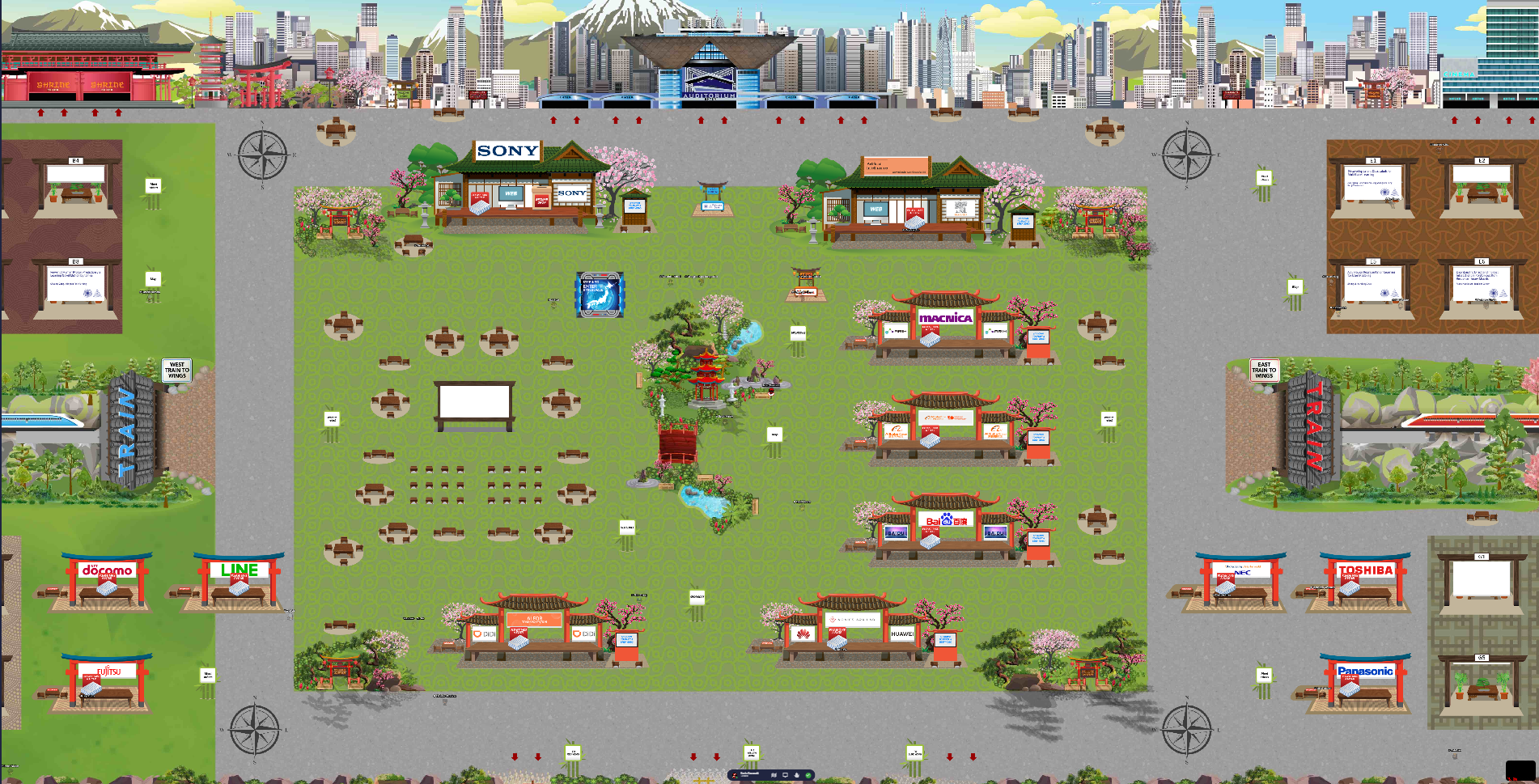
こちらもメインホールで、背景に東京の街並みが見えます。そして中央に並んでいる和風の建物のが、スポンサーブースになります。SONYが一番わかりやすく見えますが、他はHUAWEIやBaiduなど中国の企業が並んでいました。そして、画面右下左下にある鳥居みたいなものもスポンサーブースで、日本企業が並んでいました。中央に中国企業、その周りにこじんまりと日本企業があるといった感じで、中国の勢いを感じました。

奥に見えるビックサイト的な建物は講堂になっていて、そこでオープニングセレモニーや招待講演など、大きなイベントが開催されていました。
大きな会場だけあって、座席もたくさん並んでいました。
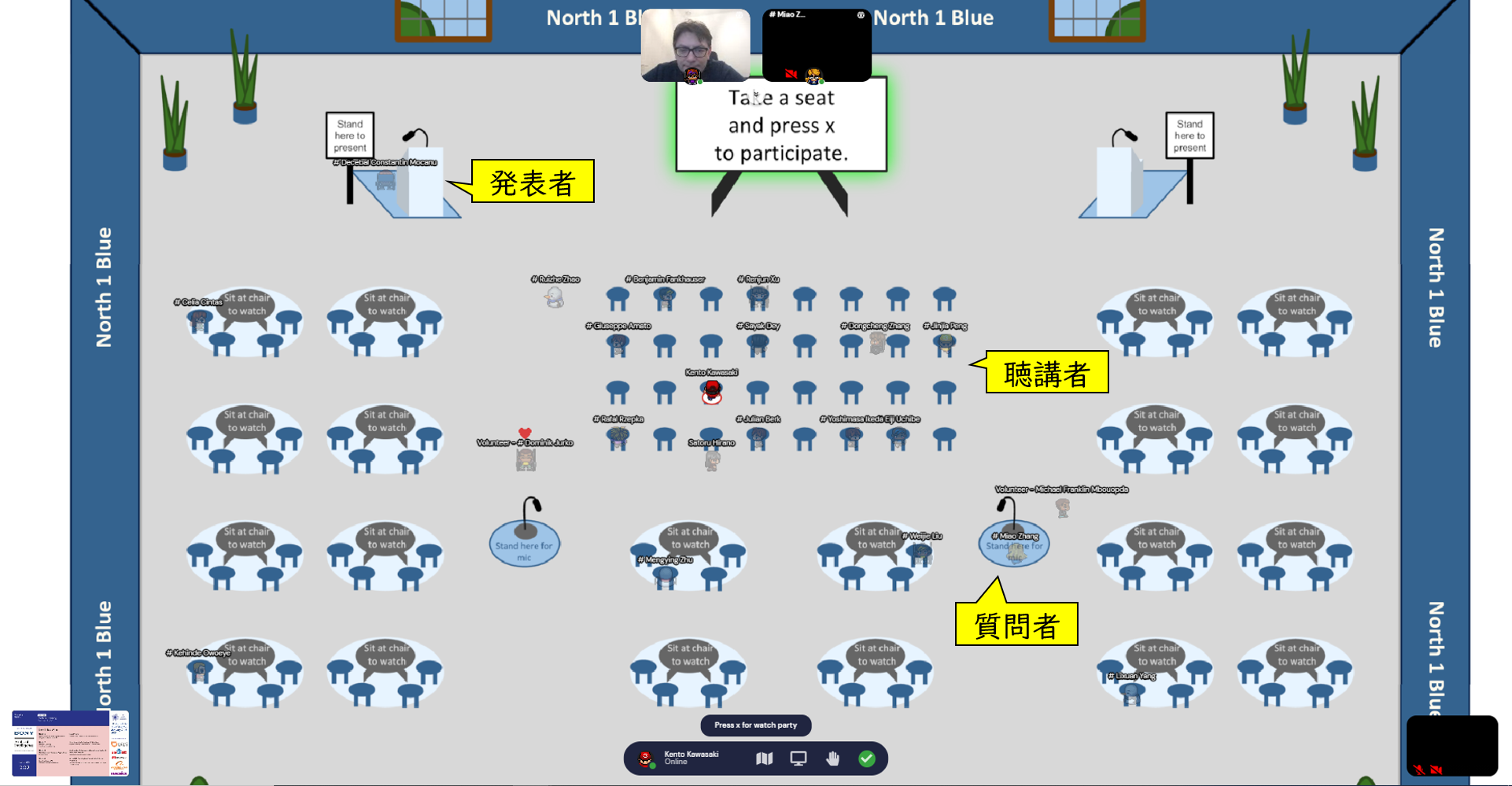
これはメイントラック会場の様子です。画面の上部に発表者用のマイクがあり、発表者はそこで発表します。聴講者は会場内にいくつかある座席に座って発表を聴きます。
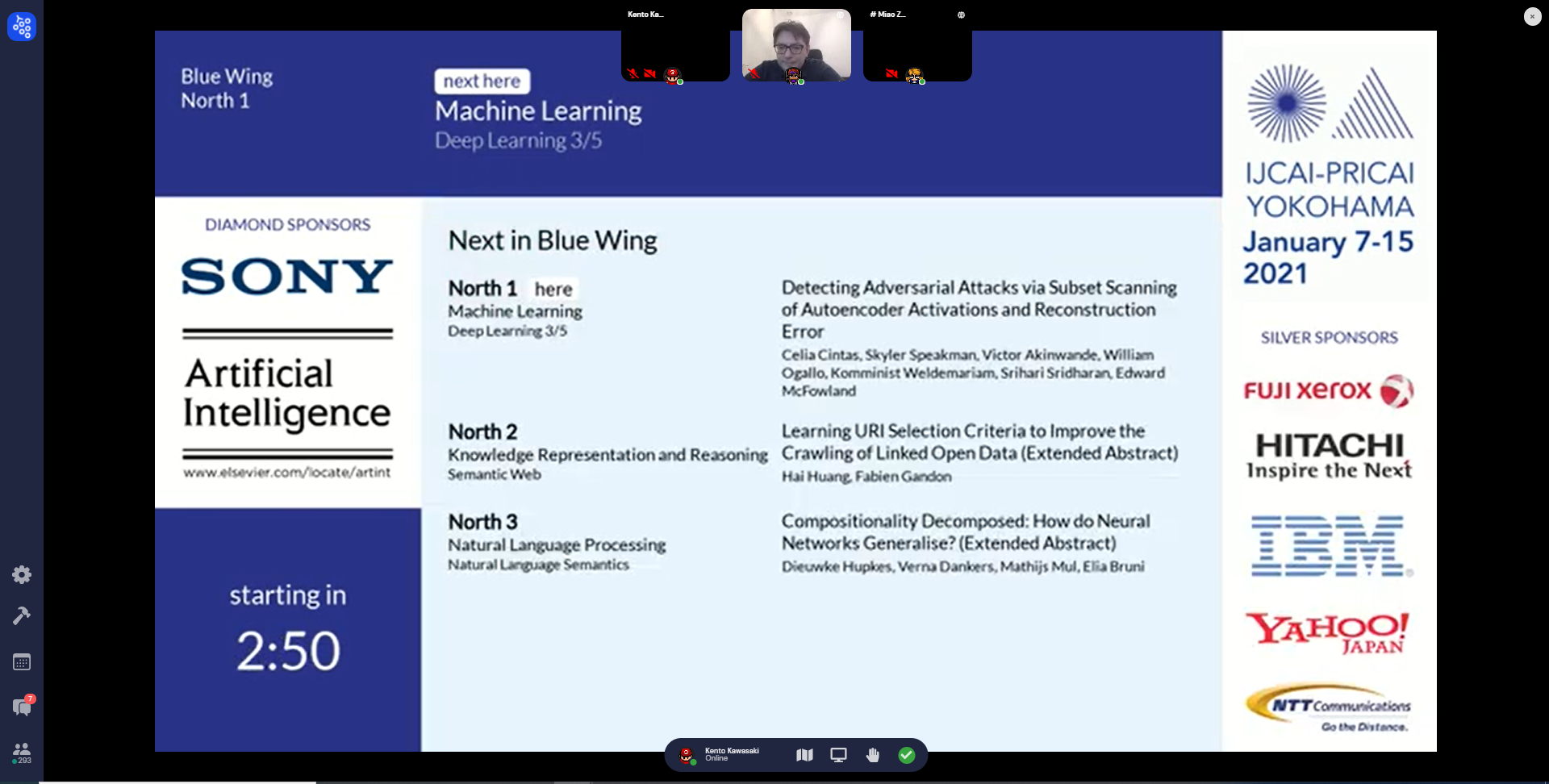
座席まで行き、Xキーを押すと発表者のプレゼン資料を見ることができます。発表が終わると質疑応答があるので、そこで質問がある人は質問者用のマイクで質問をします。1つの発表当たり発表時間は5分、質問時間は3分です。

発表が一通り終わるとポスターセッションがメインホールで開催され、より詳しく質問をしたい人はポスター会場に行って質問するという感じでした。
今回、初めてVirtual Chairを使用しましたが、使い方に慣れるまで苦戦したので、知っていると役立つ情報を紹介します。
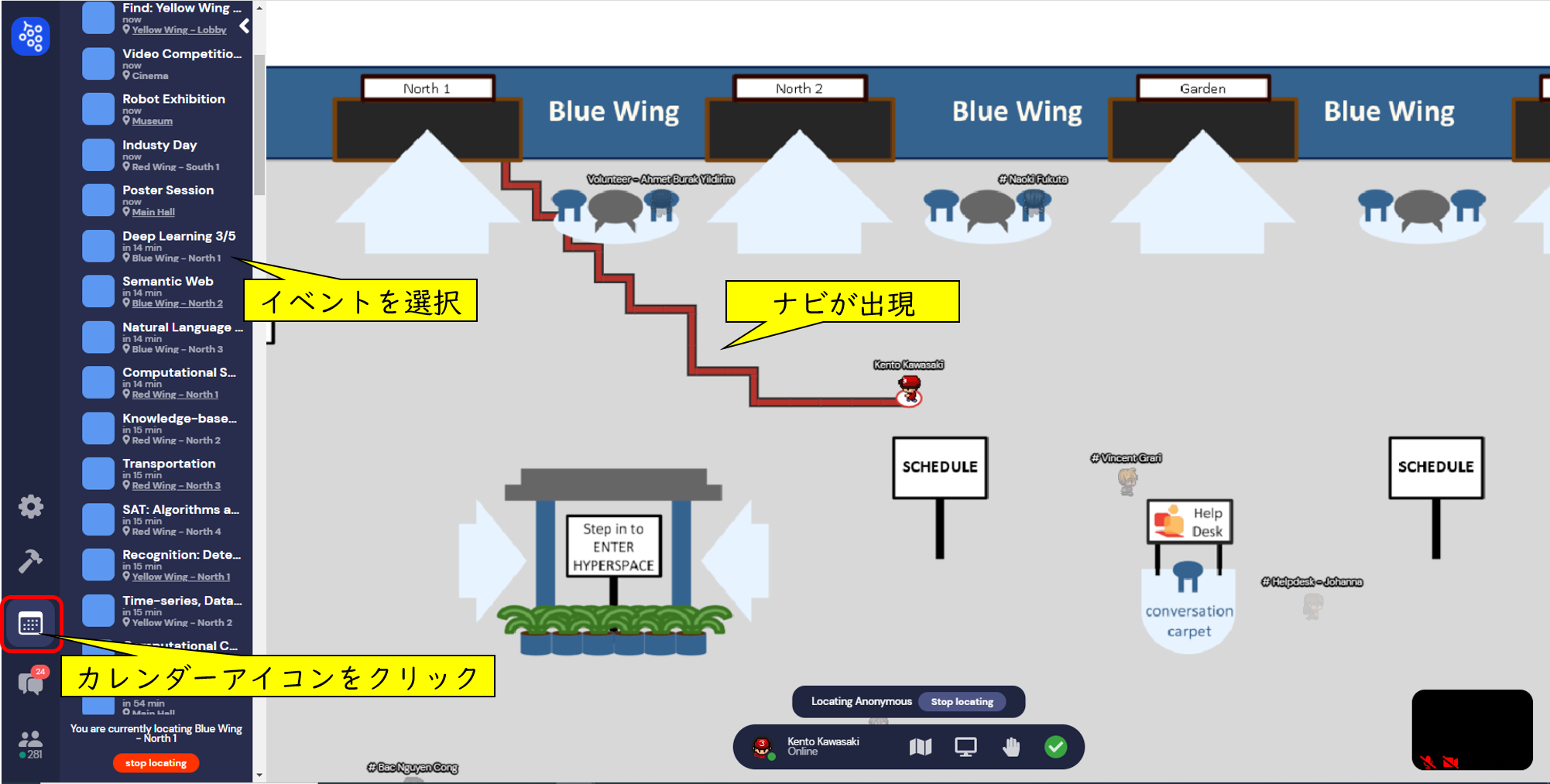
Virtual Chairで最初に困ったことは、イベント会場がどこかわからないことです。特に案内がなかったので、開始時間直前まで迷ってしまいました。しかし、よく探すとメニューのところにカレンダーのアイコンがあり、そこでこれから開催されるイベントを確認することができます。お目当てのイベント見つけたら、それを選択することでナビが出現します。のちに気づくことになるのですが、会場内にInformationのコーナーがあり、そこで使い方が紹介されていました。なので、迷ったらInformationを探してみるのもいいかもしれません。
興味深かった研究
ここからは興味深かった研究について、いくつか紹介します。著者の趣味嗜好に偏っているので、あらかじめご了承ください。
- 分野:文章生成
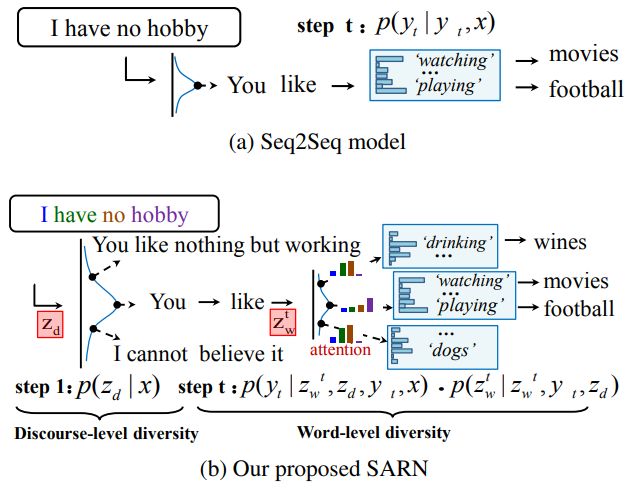
(b)談話レベルと単語レベルの確率的変動を捉えるために、確率的注意を払って潜在変数zdとzwを導入する。
SARNは、p(yt|z ≤t w , zd, y<t, x)の分布を推定するため、潜在変数の異なる割り当てを条件に、多様なコメントが生成される。
- 内容:近年、ソーシャルアプリケーションのためのリアルなコメントの生成は多くの注目を集めており、Seq2Seqなどのモデルが文章生成に利用されてきた。しかしながら、従来のSeq2Seqモデルは入力と出力の間の尤度の最大化を図るため、無難で非実用的なコメントを生成する傾向があり、多様性を欠いている。そこで、この研究では、談話レベルの特徴と単語レベルの特徴を階層的に扱うことができるリカレントネットワーク(structured latent variable Recurrent Network with Stochastic Attention)を提案し、多様性のあるコメント生成を実現した。具体的には、コメントの階層構造を構築するために、談話レベル変数と単語レベルの潜在変数を導入した。談話レベル変数は、スタイル、トピック、意図などの高次の特性を捉え、単語レベルの変数はStochastic Attentionで、入力された投稿に含まれる興味のあるキーワードのバリエーションを推測するために使用される。Stochastic Attentionは単語選択において複雑な変動をモデル化している。オープンドメインのWeiboデータセットを用いた実験では、ブラインド評価を行い、提案手法が他の手法と比較して、談話レベルと単語レベルの両方において、より多様なコメントが得られることが示された。
- URL:https://www.ijcai.org/Proceedings/2020/0548.pdf
- 分野:ポートフォリオ選択、時系列、Transformer
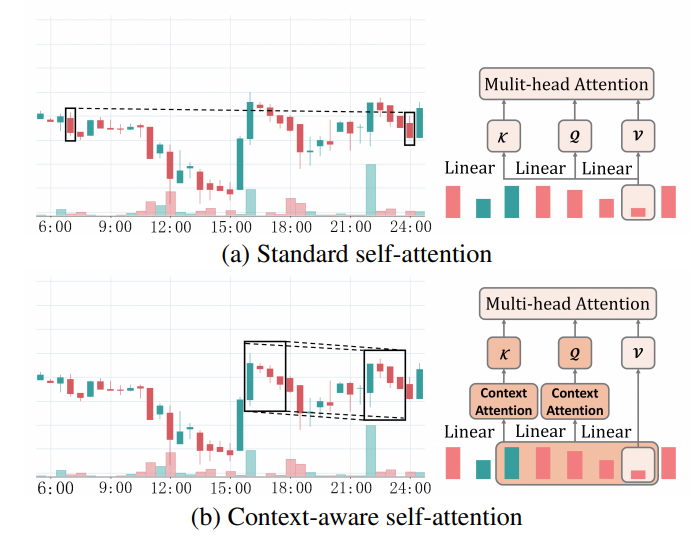
その代わりに、(b)コンテキストを意識した自己アテンションは、コンテキストアテンションを使用してローカル価格のコンテキストをクエリ/キーに変換するため、ローカル価格のノイズに対してよりロバストである。
- 内容:ポートフォリオの選択は、フィンテックAIにおいて重要でありながらも挑戦的な課題である。ポートフォリオの決定に重要な課題の一つは、ポートフォリオ内の資産の非定常な価格系列をどのように表現するかである。しかし、既存の手法では、資産価格系列の複雑な連続パターンや複数の資産間の価格相関関係を捉えるには不十分である。そこで、この研究では、ポートフォリオ選択のポリシーネットワークにRelation-aware Transformer (RAT)を提案している。このポリシーネットワークの目的は、資産価格の情報的特徴を抽出し、これらの特徴に基づいてポートフォリオの決定を行うことである。Encoderに資産価格の逐次パターンを捉えるためのsequential attention layerと、資産相関を捉えるためのrelation attention layerを考案した。また、Decoderには、出された特徴、ローカル価格の文脈、前回の決定を総合的に考慮してポートフォリオを選択するdecision-making layerが設けられている。実世界のデータセットを用いた広範な実験により、オンライン学習や強化学習ベースの手法を含むPSの最先端の手法と比較して、この手法の優位性が確認された。
- URL:https://www.ijcai.org/Proceedings/2020/0641.pdf
- 分野:教師なし学習, Siamese Network
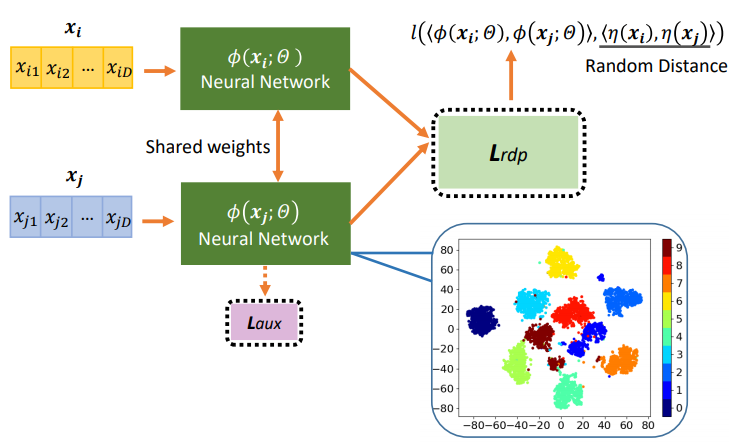
- 内容:近年、多くの教師なし表現学習手法が導入されているが、ほとんどが問題をアノテーションフリーの前文タスクとして定式化する自己教師付きアプローチであり、時間的・空間的な教師情報が含まれていない表形式データには適用できないことが多い。また、ランダム射影やオートエンコーダーのようなアプローチは非常に効率的であるが、その根底にあるデータの仮定や弱い教師信号のために複雑なクラス構造を捕捉できないことが多いという課題がある。そこで、この研究では、Random Distance Prediction modelを提案している。この定式化は非常にシンプルでありながら、ランダム射影における距離保存を最適化する表現的特徴量を学習するための非常に効果的な教師信号を提供する。学習された特徴量は十分に汎用的であり、下流の予測タスクに対しても機能する。さらに、この定式化は学習された特徴をさらに強化するために、ランダム距離予測を補完するタスク依存の補助損失を組み込むことができる柔軟性を持っている。その結果、Random Distance Prediction modelが、異常検出とクラスタリングという2つの重要な教師なしタスクにおいて、SOTAよりも大幅に優れた性能を達成していることを示した。
- URL:https://www.ijcai.org/Proceedings/2020/0408.pdf
- 分野:教師なし学習, 異常検知, Adversarial Example
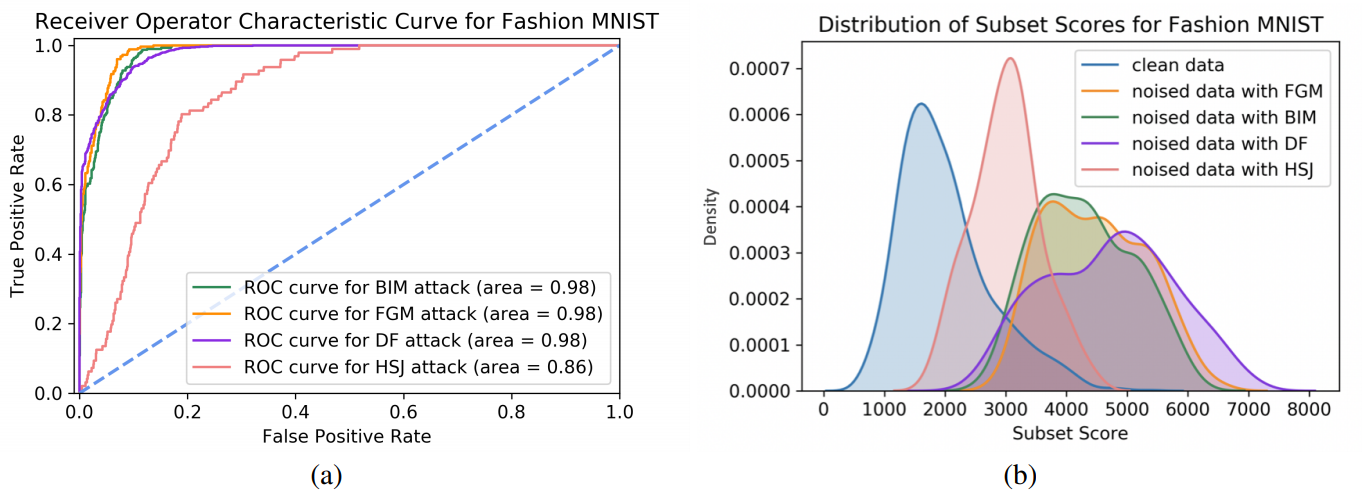
(b)Conv2d 1上の画像のテストセットのサブセットのスコアの分布。 クリーンな画像の方がノイズ化された画像よりもスコアが低い。
- 内容:ディープニューラルネットワークに対する敵対的攻撃は問題になっており、AIの社会実装において、攻撃を検知することは重要な課題の一つである。しかしながら、攻撃手法をは巧妙化しており、予想されるすべての教師データを作成し、攻撃を検知するモデルを構築することは現実的ではない。そこで、この研究では敵対的攻撃を検出する教師なし手法を提案している。具体的には、オートエンコーダーの内層における異常なノードのサブセットを識別することで、これを実現する。F-MNIST, MNIST, CIFARデータセットにおいて、BIM, FGSM, DF, HSJなどの敵対的攻撃手法に対する検出力を評価した。その結果、サブセットスキャニング手法は、広い範囲の摂動強度に対して、DefenseGanよりも高い検出力を示した。また、この手法は、どの画像が異常に見えるかを指摘するだけでなく、異常なノードを検出できるため、解釈可能性にも貢献すると考えられる。
- URL:https://www.ijcai.org/Proceedings/2020/0122.pdf
おわりに
国際会議への参加は今回が初めてでしたが、オンラインでも得らるものが多く、世界の人工知能研究の縮図を見ることができました。
特に中国からの研究者が多いことやスポンサーブースも中国の企業が中心にあるなど中国の勢いを感じました。一方で国際会議では日本人の参加者が少ないというのは元々聞いていましたが、その通りであったことも確認できました。
研究発表に関しては、いろいろとヒントになることが得られました。また、基調講演などでは海外の研究者の考え方を知るという点で非常にいい機会になりました。例えば、ベンチマークのスコアを上げることに躍起になっている近年の研究傾向に対する批判であったり、深層学習だけではなく古典的な手法にも、もっと目を向けるべきだという意見など、はっとさせらるようなお話を聴くことができました。
昨今はコロナ禍で研究者同士が直接交流することができずらくなっていますが、Virtual Chairというツールもあり、オンラインでも問題なくコミュニケーションをとれるようになっています。現地の会場に行くことでしか得られないこともありますが、逆にオンラインでは場所や時間に縛られず参加できるので、興味のある方は一度、国際会議に参加してみるといいと思います。

