
先日、JuliaCon2021のセッションがYouTube上に一部公開されていました。
KaggleでPythonを用いたデータ分析の経験があるので、統計に関するセッションが興味深いと感じました。そこで今回は、Pythonを使用している側から見た、Julia言語についての考察と視聴したセッションについて報告していきます。
まずは、JuliaConについて説明します。
JuliaConについて
Julia言語のコミュニティとして、開催されたオンラインカンファレンスがJuliaConです。
Julia言語とは、2009年に4人の研究者が開発を始めたプログラミング言語で、2012年にはオープンソースソフトウェアとして公開が始まりました。数値解析などの複雑な数式をシンプルに記述できることに加えて、C言語に劣らない高速性を売りにしており、Pythonに次ぐデータサイエンティスト向けの言語としてシェアを徐々に伸ばしています。
- JuliaCon2021:https://juliacon.org/2021/
セッションスケジュールについて
JuliaCon2021の開催期間は、7/20~30でした。
セッションの開始時間などはUTCを基準としているため、日本時間で実際に参加した人は、生活リズムの調整が難しかったように思えます。
そのため、YouTubeにてJuliaCon2021のセッションを視聴しました。
- セッションスケジュール:https://pretalx.com/juliacon2021/talk/
- JuliaCon2021(YouTube):https://www.youtube.com/c/TheJuliaLanguage/videos
次に、自分が興味深いと感じたセッションについて説明します。
興味深かったセッション
- 分野:統計、機械学習
- 概要:このセッションでは、Julia言語を使用したことの無い人に向けて、いくつかのJuliaの基本から始まり、基本的な確率と統計の例、データフレームの使用法、基本的な統計的推論、機械学習手法の順に進みます。
セッション内容詳細
セッション内容として、以下の資料URLのトピック順に解説していました。そのため、この記事でもトピックの順に紹介していきます。
はじめに、GitHubのディレクトリをダウンロードする必要があるので、以下のURL(GitHub)からダウンロードを行ってください。
- 資料URL:https://nbviewer.jupyter.org/github/yoninazarathy/JuliaCon2021-StatisticsWithJuliaFromTheGroundUp/blob/master/Workshop-with-output.ipynb#home
- GitHub:https://github.com/yoninazarathy/JuliaCon2021-StatisticsWithJuliaFromTheGroundUp
Before we start
最初のトピックは、前置きです。呼び出すディレクトリと、使用するパッケージの紹介を行っていました。
以下の表のように、PythonとJulliaでパッケージのインストールや読み込みの表記が異なります。また、JuliaからPythonを使用する際、パッケージの読み込み方法は、import パッケージ名ではなく、pyimport(“パッケージ名”)になるので、注意してください。
| Python | Julia | |
| パッケージのインストール | pip install パッケージ名 | using Pkg;Pkg.add(“パッケージ名”) |
| パッケージの呼び出し | import パッケージ名 | using パッケージ名 |
Why Julia?
ここでは、Juliaの概要について説明しています。
Juliaは、Python言語のように簡単に記述することができ、C言語のように処理速度が速いという特徴があることを説明しています。
その他、具体的な特徴が知りたい人は、公式サイトで紹介されているので参考にしてください。
Juliaでは、簡単にPythonやC、Javaなど色々な言語を呼び出せることに驚きました。また、Pythonと比較して、処理速度が3倍以上になったというケースも多く見られました。Juliaは機械学習分野を得意とするため、Pythonではなく、Juliaを使用するユーザーも増えてくるのではないでしょうか。
What do you mean?
はじめに、配列を作成し、平均値を求めるといった簡単な計算方法を紹介しています。次に、ネストされた配列の計算と行列の計算方法が紹介し、dictやtupleといったオブジェクトでの簡単な計算方法も紹介しています。また、DataFrameの簡単な操作方法の紹介、最後には記述統計に関する色々な関数の紹介もありました。
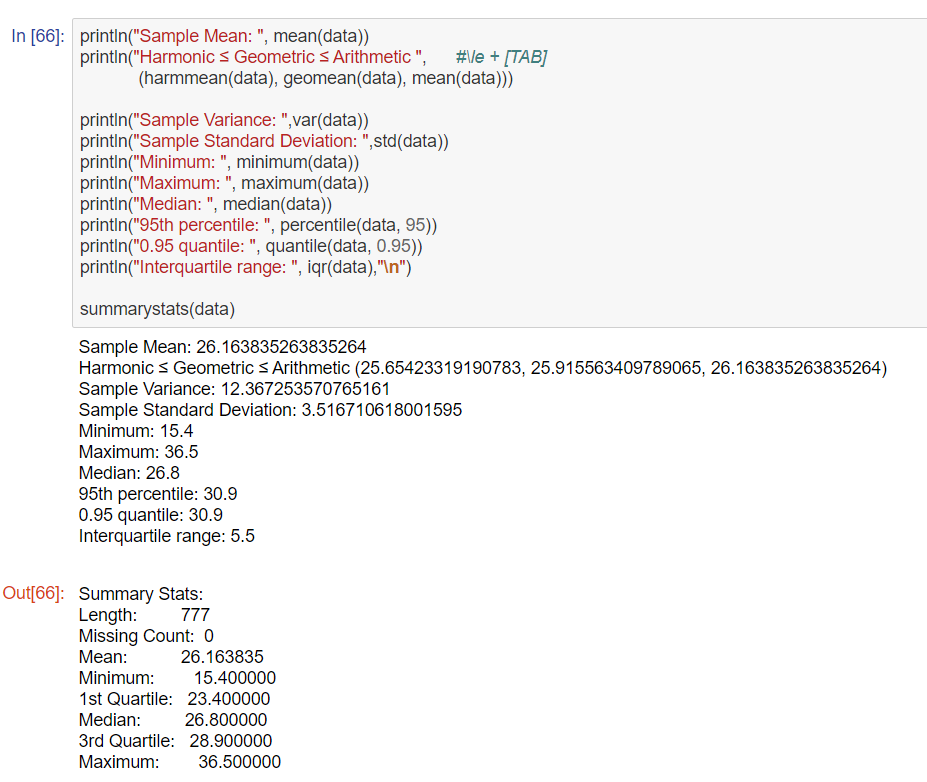
ここで、型について紹介していますが、list型(Pythonでいうところの)が紹介されていなかったので、疑問を持ちましたが、Juliaでは以下の画像の通り、listではなくvector型になっています。Juliaでは、リストはなく、配列に統一されているそうです。
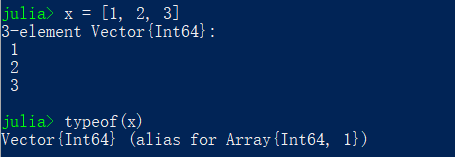
Something rand.
ここでは、色々な乱数の紹介をしています。まずは、モンティホール問題を解き、理論と一致することを確認します。次に、CRNとRNGを使用して乱数を作成し、可視化を行っていました。
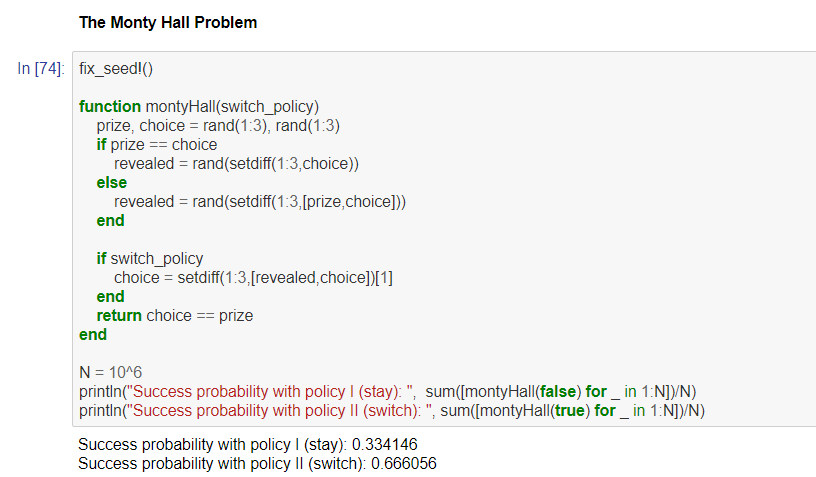
上の画像では、関数の定義を行っています。ここで注目してほしい点は、Pythonとは異なり、function 関数名()で関数の定義が始まり、最後に:(コロン)がない点と、endによって、関数の定義が終了している点です。Pythonに比べて、関数定義には文字数が増えています。
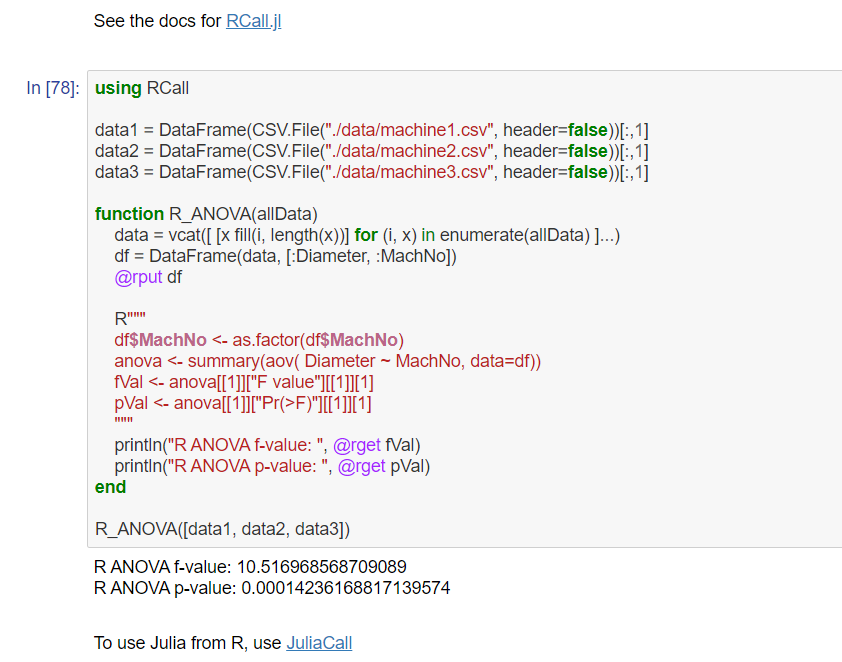
Do you still miss R? So Just RCall.
ここでは、JuliaからR言語を使用し、F値とP値求める方法を紹介しています。
まずは、GitHubにあるcsvファイルをDataFrameとして読み込みます。次に、R言語を使用し、F値とP値をもとめます。
RCallとは、R言語を呼び出すためのパッケージです。
JuliaからPython言語を呼び出すには、PyCallパッケージを使用します。 ここで分かるように、Juliaは簡単に色々な言語を読み込むとができる点も魅力の一つです。
ちなみに、上記で述べたことを応用すると、Pythonを使用する際は、using Pkg;Pkg.add(“PyCall”)によって、PyCallパッケージをインストールして、using PyCallによって、パッケージを読み込んで使用します。
Some Plots.
ここでは、ヒストグラムや折れ線グラフ、箱ひげ図などといった、データをplotするためのメソッドを紹介をしています。ここで、説明があったいくつかのグラフを紹介します。
最初の例は、波長ごとの周波数の変化をヒストグラムを用いてplotしています。
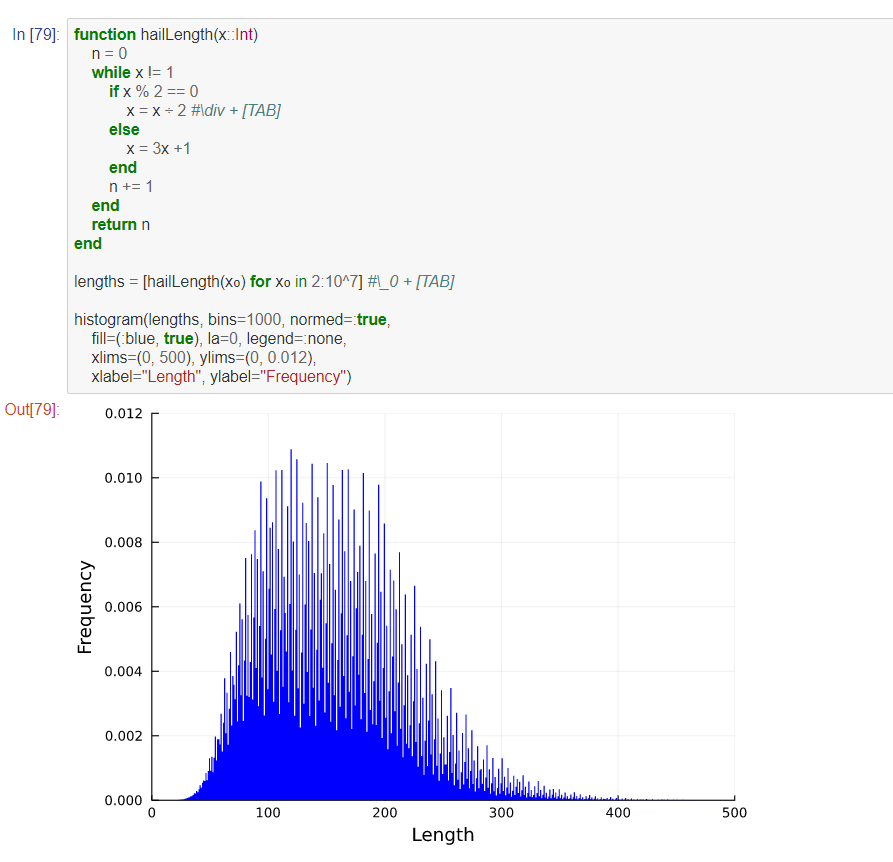
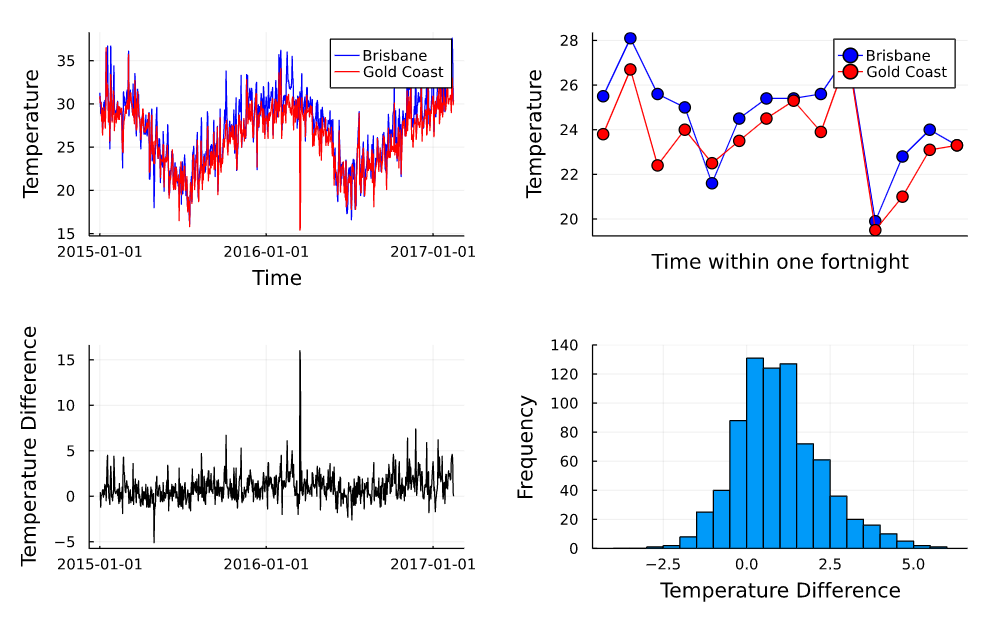
以下の例では、オーストラリアの都市ごとの気温の変化を折れ線グラフやヒストグラムを用いて、グラフ化しています。
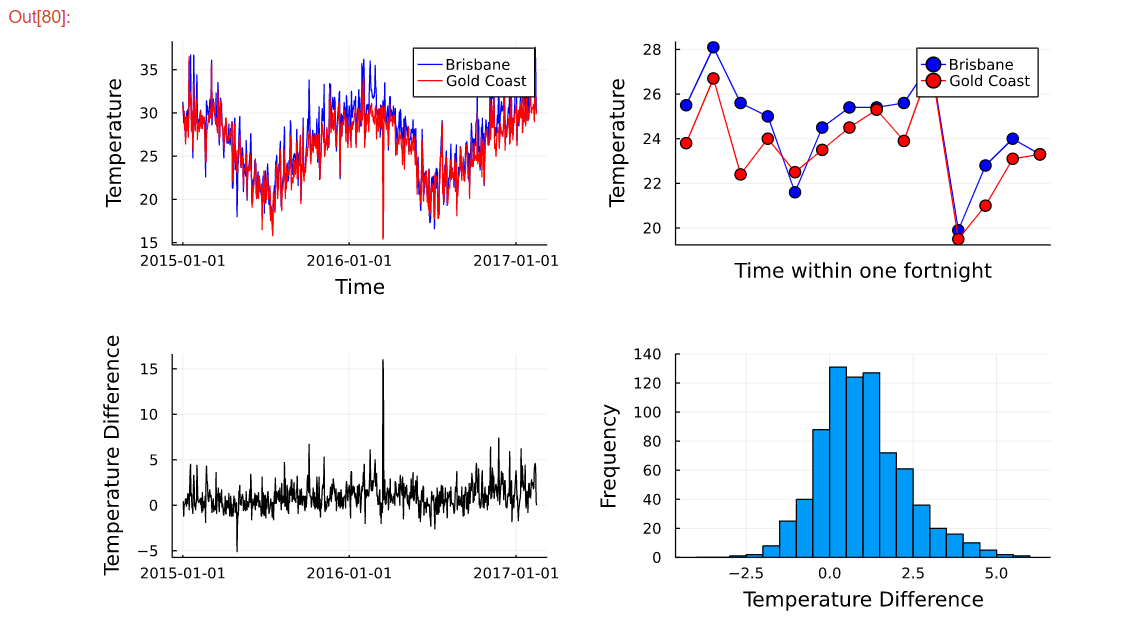
その他にも、ggplotや箱ひげ図など色々なグラフを紹介していました。
これらからわかることは、Juliaでは多くのグラフを表示できるため、データの可視化を簡単に行うことができます。つまり、機械学習分野だけでなく、データ分析においても期待できます。
また、このトピックの最初の画像のコードを見る限り、メソッドを使用する際、パッケージ名.メソッド名のような表記ではなく、メソッド名だけ(画像では、histogram())で使用していたので、どのパッケージのメソッドなのかがわからなくなりそうでした。つまり、パッケージの名前空間を表示していないということです。
※名前空間の表記については、usingとimportによって、表記の仕方が異なる場合もあるそうです。詳しくはこちらで紹介されています。
Your favorite Distribution.
Distrbutions.jlパッケージの関数について紹介していました。
標準化を行う関数や平均を行う関数、乱数配列を作成する関数や確率分布の紹介がありました。
また、Distrbutions.jlパッケージのドキュメントも紹介していました。
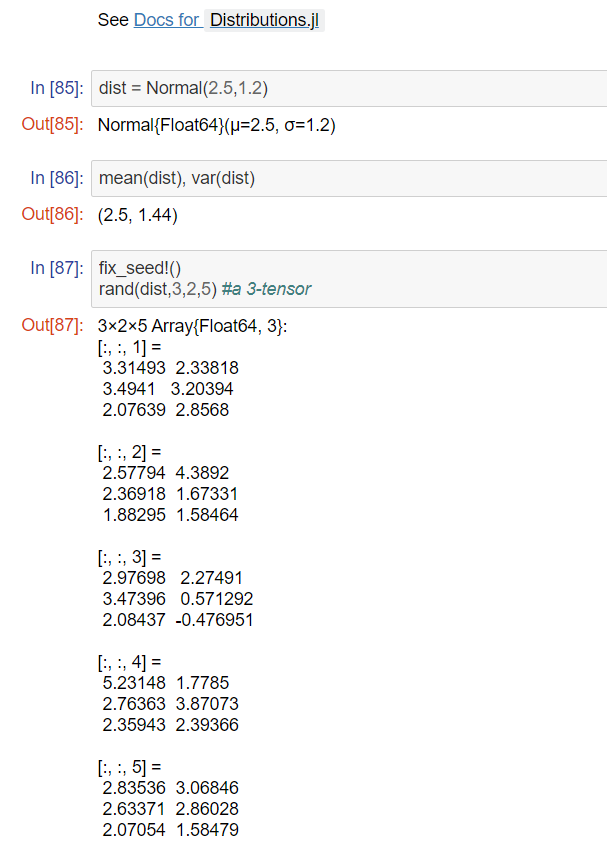
関数を見た感じだと、PythonのNumpyパッケージの関数に近い印象です。また、 Distrbutions.jlパッケージは、配列などの計算を効率よく行い、簡単に確率分布を作成可能にするパッケージだといえます。
また、ここの資料で見られるif文も関数と同様、if文の終わりには、endを表記するところがPythonと異なります。さらに、Juliaのインデントは、見やすさのためだけに行うため、ここも異なる点だといえます。
We love DataFrames.
ここでは、DataFrameの簡単な操作方法を紹介しています。
また、DataFrameのドキュメントとチュートリアルの紹介もしていました。
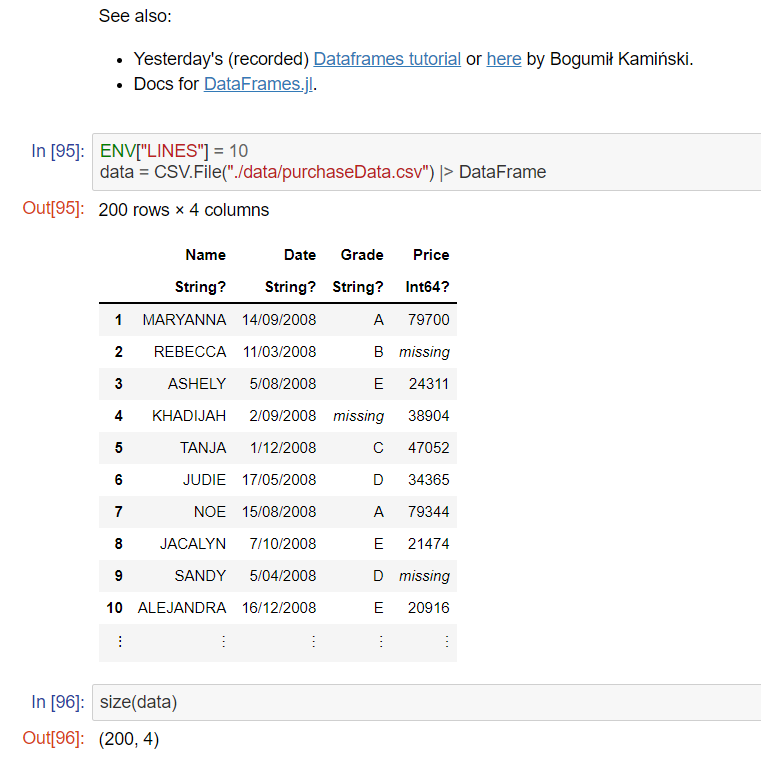
Pythonとは違って、少し面倒だと感じたところは、csvファイルを操作するためのパッケージとDataFrameを操作するためのパッケージ、2つをインストールして読み込む必要がある点です。Pythonでは、pandasだけでこの2つの操作が行えるので、少し手間がかかるように感じました。
Gotta have some basic inference.
ここでは、推計統計学の3つの手法、点推定、区間推定、仮説検定を紹介しています。
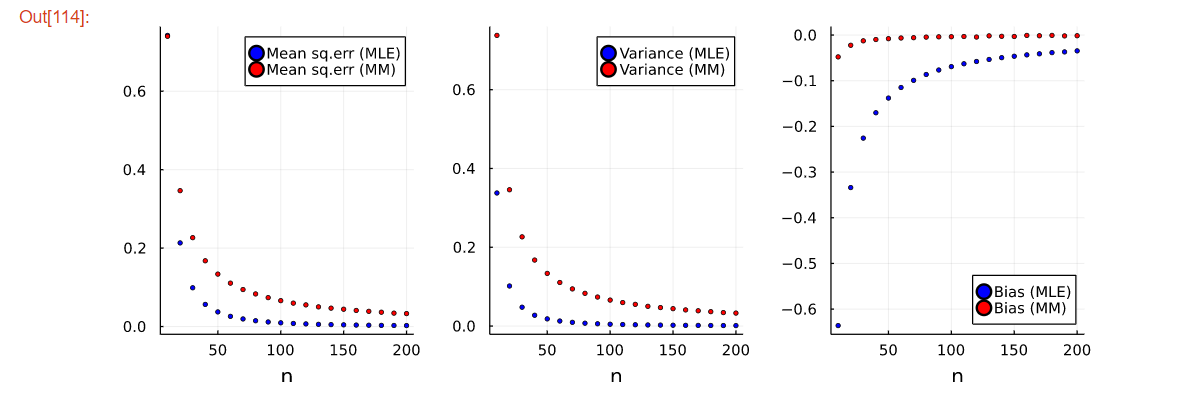
まずは、点推定の紹介です。2点の推定結果を用いて、平均二乗誤差、分散、バイアスで比較したものをplotしています。
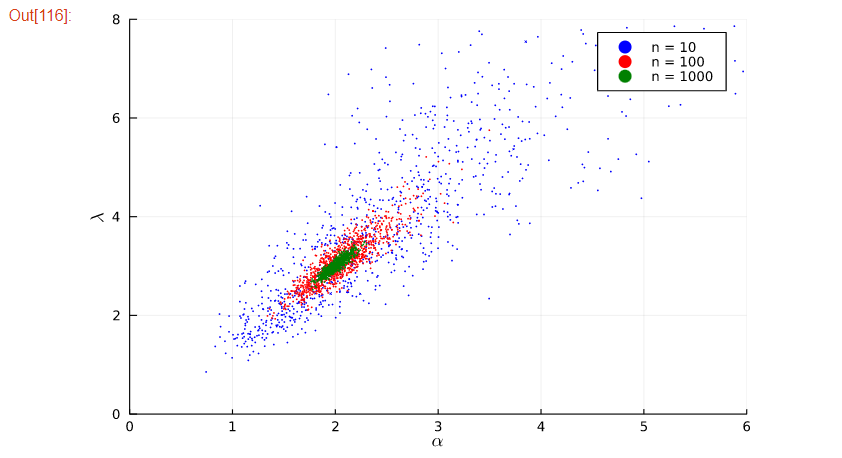
次に、scatter()メソッドを使用して、散布図でガンマ分布をplotさせていました。
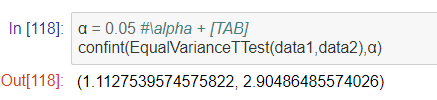
次に、簡単に信頼区間を設定できる関数の説明を行っていました。
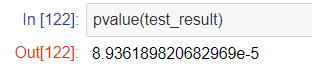
最後の仮説検定のところでは、pvalue()関数を使用するとこで、簡単にP値が求まることを確認できました。 どちらの関数も、1行で答えを求めることができています。
これらのことから、Juliaには、データ分析には欠かせない、統計に関する幅広いパッケージが用意されていることがわかりました。
また、ここで気が付いたことととして、スライスのステップ指定がPythonと異なる点です。以下の表のように、それぞれで異なります。ステップを指定しない場合は、どちらもstart:endなので心配はいりません。
| Julia | Python |
| start:step:end | start:end:step |
Linear models at our core.
ここでは、人の身長と体重のデータを用いて、線形回帰モデルの紹介を行っていました。
まずは、lm()メソッドで、線形モデルに適合させて学習し、glm()メソッドで、一般線形モデルに適合させて学習します。そして、pred()メソッドを使用して学習済みモデル(ここでは線形モデル)で数値データを予測しています。
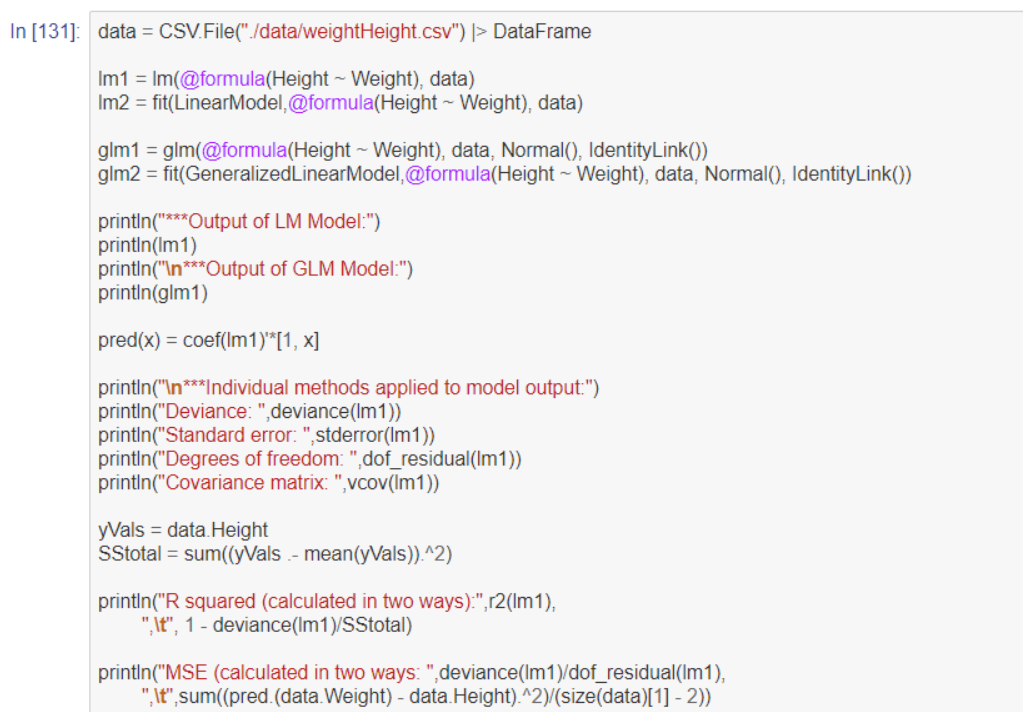
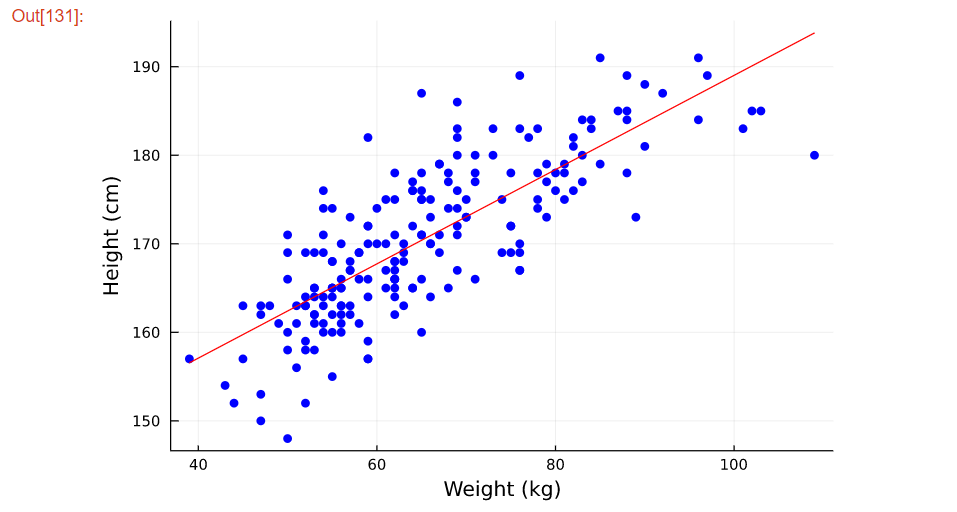
最後は、scatter()とplot!()メソッドを使用し、データの散布図とモデル(ここでは線形モデル)の予測結果をplotしています。

以下の画像が、線形回帰モデルのグラフです。青色の点が、データです。赤色の線が、学習した線形モデルを用いてデータを予測した結果になります。線形モデルの予測によって、データの傾向が見える化され、データの特徴を知ることができました。
また、説明はなかったもののカテゴリ変数ごとの線形回帰やLASSO回帰の紹介もありました。
ここでは、線形回帰だけを行うパッケージを紹介していますが、scikit-learnをモデルにしたパッケージも用意されているため、Pythonとほとんど同じ操作で、簡単に機械学習を実装できることがわかりました。詳しくは、こちらで紹介されています。
Basic Machine learning.
最後には、基本となる機械学習手法が紹介されていました。
資料で紹介されていた手法として、VGG19、K-means、主成分分析(PCA)、線形分類です。また、MNISTデータセットの紹介やニューラルネットワークの学習の紹介もありました。
Juliaでは、 Flux.jlパッケージ のChain()を使用してネットワークを構築します。ここでは、Dense()を用いて全結合層を追加しています。

model2では、全結合層だけでなく、 Conv()を用いて畳み込み層も追加していることが確認できます。

ここでは、上の画像のmodel1(Dense)とmodel2(Convolutional)の精度を比較しています。
両者モデルの学習の終盤には、model2の方が性能が良くなっています。
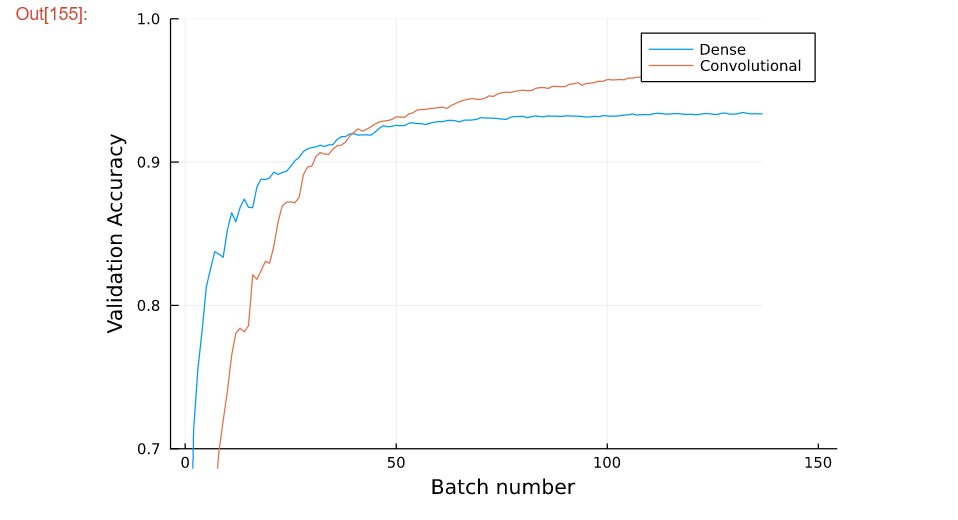
ここで使用されているFlux.jlパッケージによって、簡単にニューラルネットワークの実装や深層学習を行うことができます。Flux.jlとは、PythonでいうTensorFlowだと思ってもらえれば大丈夫です。
おわりに
今回は、JuliaConのセッション内容の報告とJuliaとPythonの比較してきました。Juliaは簡単に記述できるといわれていますが、個人的にはPythonの方が、直感的にコードを理解することができるのではないかと感じました。Juliaは、Pythonより処理速度が圧倒的に早く、今後も期待されていく言語です。しかし、コードがわかりやすいということを踏まえて、初心者はPythonからプログラミングの学習を始めてもいいのかもしれません。この記事を機に、使用している言語が自分にとってbestなのかを考えて、言語選びを考えてみてはいかがでしょうか。
Appendix
・JuliaをPythonと比較した際に異なる点:https://docs.julialang.org/en/v1/manual/noteworthy-differences/#Noteworthy-differences-from-Python
K.Y
追記:関連
Julia関連記事については、次にもまとめてあります

