
先日、言語処理学会第27回年次大会に参加してきましたので、会議の様子や興味深かった研究について報告します。
言語処理学会について

言語処理学会は下記のように紹介されています。
言語処理学会(The Association for Natural Language Processing)は,わが国の言語処理の研究成果発表の場として,また国際的な研究交流の場として,1994年4月1日に設立されました.原則年4回の会誌「自然言語処理」の発行,年1回の言語処学会年次大会の開催を通じて,この分野の学問の発展,応用技術の発展と普及,国際的なレベルでの研究者・技術者・ユーザ相互間のコミュニケーションと人材の育成をはかる機関とすべく活動しています.
言語処理学会HP(https://www.anlp.jp/)より
また、活動の対象範囲は下記の通りとなっています。
- 音韻論, 形態論, 構文論, 意味論, 語用論, 記号論, 計量言語学, 計算言語学,心理言語学, 対照言語学, 認知言語学, 社会言語学
- 計算辞書学, ターミノロジー, 電子化辞書, テキストデータベース, ドクメンテーション
- 言語処理アルゴリズム, 言語処理用ハードウェア・ソフトウェア, 解析・生成システム, 言語理解, 対話理解, 音声理解, 談話理解, 音声言語処理
- ワードプロセッサ, 機械翻訳, 情報検索, 対話システム, 自然言語インターフェース, ハイパーテキストなど
会議概要
- 開催形式:現地とオンライン
- 会場:北九州国際会議場
- 日程:2021年 3月15日(月)- 3月19日(金)
- 採択論文数:361件
- スポンサー数:59
- 参加者数:1,508人(過去最高)
コロナ禍のため、昨年に続きオンラインでの開催となりましたが、オープニングやクロージングイベントでは、現地の会場から行うなど今年はハイブリッドでの開催となりました。
開催イベント
- 招待講演:2件
- オーラルセッション:164件
- ポスターセッション:185件
- テーマセッション:12件
- チュートリアル:4件
- ワークショップ:4セッション
- スポンサーイブニング
今年は、オーラルセッションとポスターセッションが同時に開催されたり、ワークショップが復活したりと新しい取り組みがありました。また、表彰関係では優秀賞、若手奨励賞、言語資源賞に加えて、委員特別賞やスポンサー賞も導入されました。
プログラム
- 3月15日(月) チュートリアル,スポンサーイブニング
- 3月16日(火) 本会議 第1日
- 3月17日(水) 本会議 第2日,オンライン懇親会
- 3月18日(木) 本会議 第3日
- 3月19日(金) ワークショップ
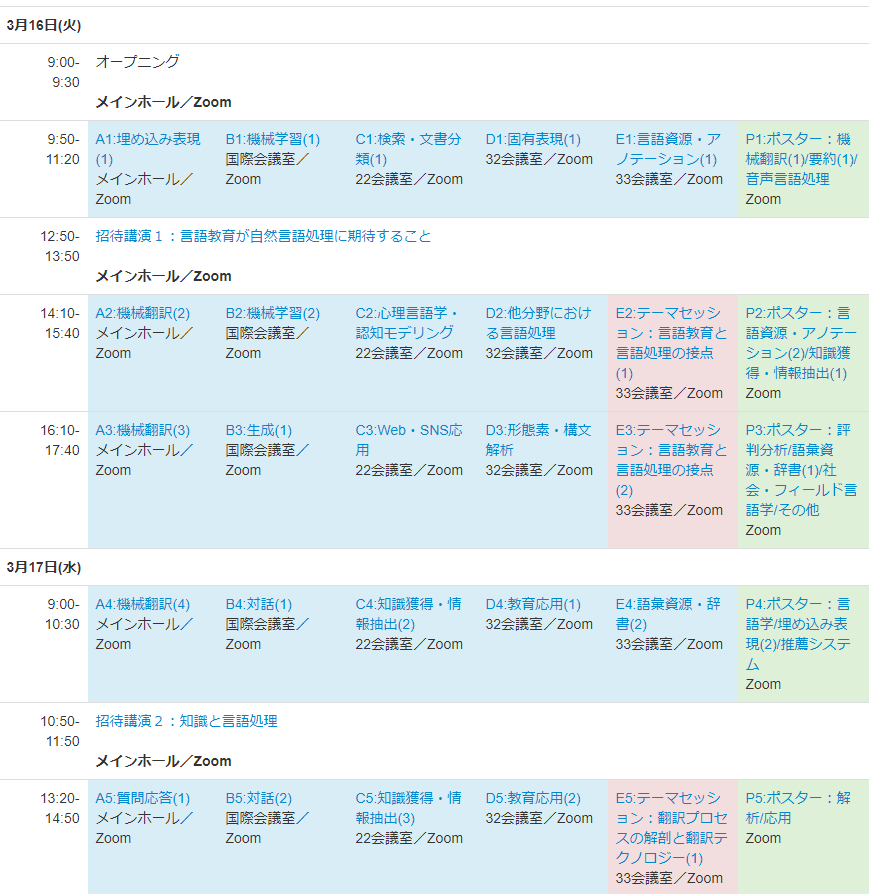
本会議は1セッション90分で4つの発表が行われ、1発表につき発表時間15分、 質疑時間5分という形式になっていました。オーラルセッションとポスターセッションは同時に行われますが、オーラルセッションを聴講した人でも、10分間時間が余るので、その時間でポスターセッションも聴講することができました。セッションとセッションの間は十分に時間がとられていて、次のセッションが始まるまで質問可能なので、オンラインでも研究者同士のコミュニケーションは取りやすくなっていたと思います。
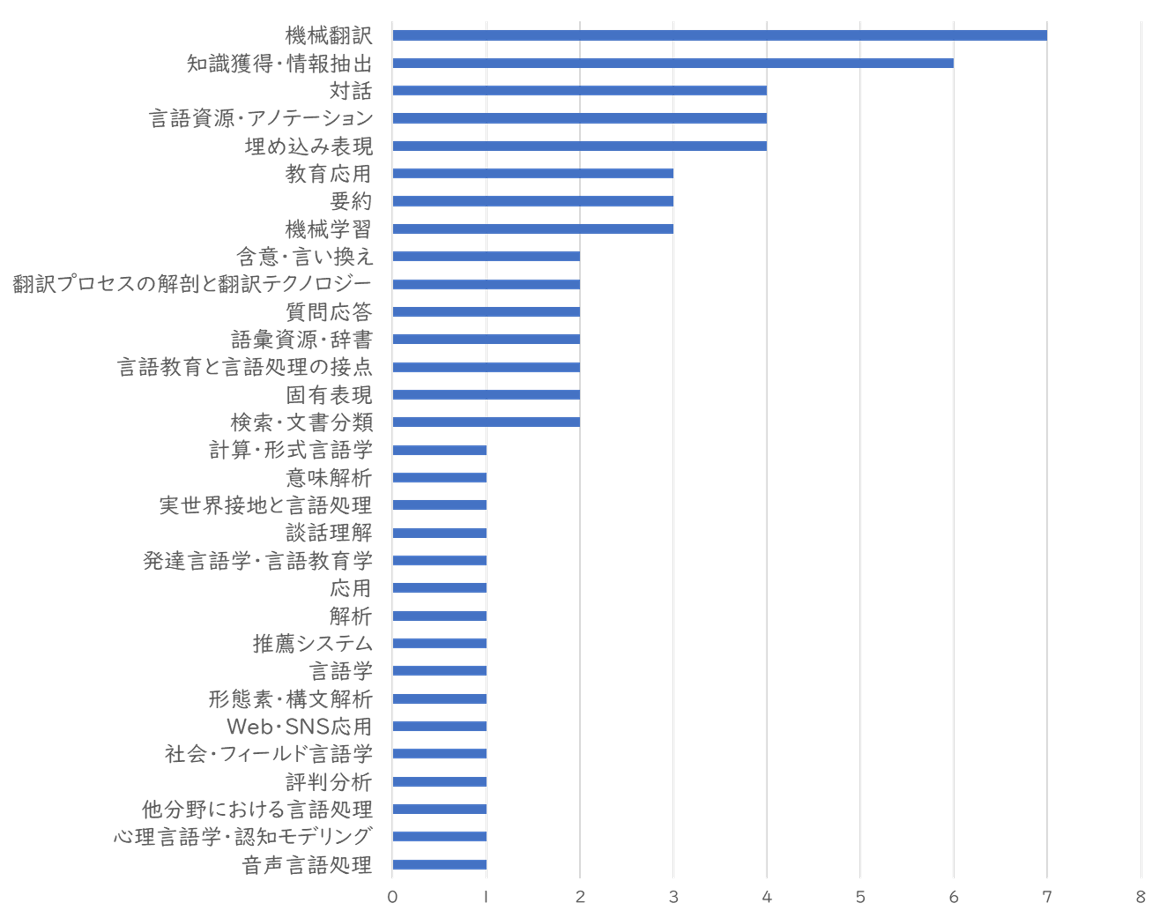
本会議のセッションを研究テーマ別に集計したものになります。機械翻訳、情報抽出など比較的ポピュラーなNLPタスクに関するセッションが多いですが、その他にも、心理言語学・認知モデリングなどのセッションもあり、テーマの裾野は広い印象です。
興味深かった発表
聴講したチュートリアル、ワークショップ、本会議の中で興味深かった発表について紹介します。発表内容はクローズドな情報なので、私がとったメモをベースとしてまとめていることを予めご了承ください。
- 発表内容はスペイン語の文献をNLPを用いて分析するというもの
- こうしたデジタル人文学はスペイン語圏で盛んに行われており、下記の例が紹介された
- 著者推定
- ドン・キホーテの贋作の著者推定
- 同時期の散文作品の作者が書いた文章を含めてクラスタリングを行い、真の作者を推定するというもの
- 文章の内容によって推定するのではなく、文体や言い回しなどの微妙な特徴から推定するため、品詞n-gramに注目して分類を行ったとのこと
- 年代・地点推定
- ある文献がいつどこでかかれたのか、そしてそれが本物なのかを推定するタスク
- 文献内の単語を分散表現で表し、単語から年代や地点を予測する
- 回帰よりも分類が一般的で、年代ごとに区切ったり、地点はgridで区切ってどのクラスに当てはまるかを推定する
- 著者推定
- 登壇者の専門が文献学ということもあって、文献学的な知見からモデル化したり分析している点は、ほかの研究にはない発想で非常に興味深かった
- 登壇者は研究の他に、コーパスを利用した教材開発やツールの開発を行っており、言語教育における自然言語処理の活用事例が紹介された
- 言語教育におけるコーパスの直接利用
- 応用言語学では、corpusを利用した研究が近年増加している
- また、言語学習においてもデータ駆動型学習(学習者がコンコーダンス・ラインを利用して学習を行う)など、コーパスの利用が増えてきている
- 自然な英語をより多く目にすることが可能で、学習者の自律的な語学学習につながると言われている
- 自然言語処理を利用した言語教育研究
- NLPタスクを言語学習に活用した例が紹介された
- ICALL(Intelligent language tutor):
- ユーザーのライティングを分析し、リーディングマテリアルを提供するなど個人のレベルに合わせて学習できるようになっている
- Automated Writing Evaluation:
- 大規模テストでのエッセイの自動評価が起点とし、ライティングのエラー修正などに利用されている
- Machine Translation:機械翻訳による学習
- 母語で書いたエッセイを学習者が翻訳したものと、MTで翻訳したものを比較することで、言語習得に役立てる
- 近年、自然言語処理で幅広く利用されているTransformerの成功要因や性質を注意機構に焦点を当てて分析している
- 注意機構では、単語の特徴を周囲の単語情報から重みづけする「混ぜる作用」と、単語の特量をそのまま残している「残す作用」あるが、それぞれがどのくらいの割合で作用しているのかを調査
- 全体の傾向としては、混ぜる作用が11%~24%で残す作用のほうが支配的であることが分かった
- また、[CLS]の場合は最終層で混ぜる作用の割合が高く、NSP(Next Sentence Prediction)を解くために情報を集めているなど、特殊トークンごとに違う傾向が得られていた
- TransformerだけではなくBERTのメカニズムも分析している点で、意義深い研究であると感じた
- 近年の高性能な言語モデルの文処理メカニズムは人間の文処理と近いのか?という切り口の研究
- この研究では、人らしさを測る指標としてサプライザル(人間が先行文脈から予期しない単語が出てくると読みづらさを感じる理論)を導入し、perplexityとの2軸で言語モデルを分析をしている
- 英語と日本語における実験で、英語では言語モデルと人間の文処理が近いことを示した一方で、日本語では言語モデルと人間の文処理が乖離していることを示した
- これはSOV言語(日本語)とSVO言語(英語)の違いによるものだと考察している
- さらに、近年の言語モデルは言語横断的な検証の必要性があると強調している
- 自然言語は階層構造を持つが、近年の自然言語処理では、語順のみを扱う言語モデルが成功を納めている
- この研究では、階層構造を明示的に考慮することは言語モデルに必要ないのか?という問いに対して、階層構造モデルが語順のみを扱うモデルよりも認知的に妥当であることを示している
- RNNG(Recurrent Neural Network Grammars)とLSTMをperplexityとサプライザルで評価したところ、LSTMは言語モデルの性能が高いが、認知的妥当性の面ではRNNGに劣る結果となった
- また、RNNGにおいては、parsing strategy(どんな組み立て方で階層構造を組み立てるのが良いか?)についても検証しており、left-cornerが認知的妥当性に優れていることが分かった
- GANにTransformerのEncoderを組み込んだTransGANに関する研究発表
- GANでは一般的にCNNが用いられるが、TransformerはAttentionメカニズムで大局的な特徴をとらえることができるという点で優れている
- 一方でTransformerはメモリを大量に消費するという課題があるが、それに対してはTransformer EncoderとUpScaling層を交互にし、徐々に画像を大きくしていくことで解決している
- Attentionも最初からすべてのピクセルに関して計算するのではなく、局所から大局に徐々に範囲を大きくする工夫がなされている
- 自然言語処理とはまた違った工夫がなされていて、Transformerも使いようによってはまだまだ進化していくと感じた
おわりに
今回の言語処理学会では、TransformerやBERTに関する研究発表が多く、改善手法の提案や応用に関する研究も見られました。その中でも言語学的な視点から言語モデルを分析するという研究が非常に興味深く、言語学的視点からは、言語モデルは人間の認知能力と比較してどうなのかという問いが投げかけられました。確かに、近年の言語モデル、特にTransformerベースのモデルは日々スコアボードを更新するなど結果を見れば、言語処理能力に優れたモデルばかりですが、その処理の過程は人間の認知能力を再現しているとは言えないかもしれません。こうした観点から、言語モデルにおける課題や人間の認知能力を探っていくことで、自然言語処理も新しい方向へ発展していくのではないかと感じました。
(K.K)

