
この記事では、言語処理100本ノック第3章の解説に引き続き、言語処理100本ノック第4章の解説を行っていきます。 第4章では、夏目漱石の小説『吾輩は猫である』の文章をMeCabを使って形態素解析を行い、その結果を用いて処理を行っていきます。 それでは、 第4章の問題を解きましたので、処理の流れとポイントを踏まえて、解説していきます。
問題と解説
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をMeCabを使って形態素解析し,その結果をneko.txt.mecabというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.なお,問題37, 38, 39はmatplotlibもしくはGnuplotを用いるとよい.
- MeCabをインストールする。
- neko.txtをインストールする。
- neko.txtを形態素解析し、neko.txt.mecabに保存する。
|
1 2 3 4 5 6 7 8 9 |
#MeCabをインストール !apt install mecab libmecab-dev mecab-ipadic-utf8 !pip install unidic-lite #neko.txtをインストール !wget https://nlp100.github.io/data/neko.txt #形態素解析 !mecab ./neko.txt -o ./neko.txt.mecab |
形態素解析結果の読み込み
形態素解析結果(neko.txt.mecab)を読み込むプログラムを実装せよ.ただし,各形態素は表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をキーとするマッピング型に格納し,1文を形態素(マッピング型)のリストとして表現せよ.第4章の残りの問題では,ここで作ったプログラムを活用せよ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
result = [] sentence = [] with open("neko.txt.mecab") as f: for line in f: l1 = line.split("\t") if len(l1) == 2: l2 = l1[1].split(",") sentence.append({"surface": l1[0], "base": l2[6], "pos": l2[0], "pos1": l2[1]}) if l2[1] == "句点": result.append(sentence) sentence = [] result |
【出力結果】

【処理の流れ】
- 空のlistを2つ作成する。
- 形態素解析済みのファイルを開き、1行ずつ読み込む。
- 1行をタブでsplit()する(要素が2つのlistが返ってくる)。
- l1の要素が2つであれば、l1[1]の要素をカンマで分割する。
- 問題の通り、4つのキーを指定して、dictを作成し、sentenceに追加していく。
- 句点(。)が来たときに、sentence内のdictをresultに追加する。
【ポイント】
- mecabの出力フォーマット:形態素の情報が、タブやカンマで区切られているので注意。
- 句点で句切り、1文を形態素のリストとして表現する。
動詞
動詞の表層形をすべて抽出せよ.
【コード】
|
1 2 3 4 5 6 7 8 |
se = set() for lis in result: for dic in lis: if dic["pos"] == "動詞": se.add(dic["surface"]) print(se) |
【出力結果】
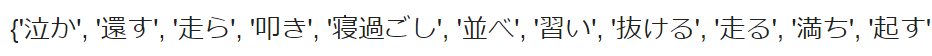
【処理の流れ】
- 空のsetを作成する。
- 問30で作成したresultを反復処理させる。
- 品詞が動詞ならば、表層形をsetに格納していく。
【ポイント】
- set():動詞の”surface”をsetオブジェクトに格納していくことで、重複をなくす。
動詞の基本形
動詞の基本形をすべて抽出せよ.
【コード】
|
1 2 3 4 5 6 7 8 |
se = set() for lis in result: for dic in lis: if dic["pos"] == "動詞": se.add(dic["base"]) print(se) |
【出力結果】
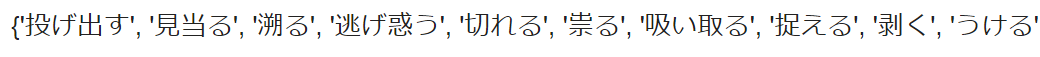
【処理の流れ】
- 問31の6行目のコードをse.add(dic[“base”])に変更した。
【ポイント】
- 問31と同じなので省略する。
「AのB」
2つの名詞が「の」で連結されている名詞句を抽出せよ.
【コード】
|
1 2 3 4 5 6 7 8 |
se = set() for line in result: for i in range(len(line)): if line[i]["pos"] == "名詞" and line[i + 1]["surface"] == "の" and line[i + 2]["pos"] == "名詞": se.add(line[i]["surface"] + line[i + 1]["surface"] + line[i + 2]["surface"]) print(se) |
【出力結果】

名詞の連接
名詞の連接(連続して出現する名詞)を最長一致で抽出せよ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 |
text_d = {} text = "" for line in result: for dic in line: if dic["pos"] == "名詞": text += dic["surface"] else: text_d[text] = len(text) text = "" print([k for k, v in text_d.items() if v == max(text_d.values())]) |
【出力結果】
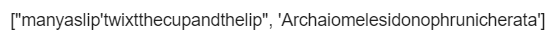
【処理の流れ】
- 空のdictと空のstrを作成する。
- 形態素が名詞であれば、表層形をtext変数に保存しておく。
- 名詞以外の品詞が渡された時、textに保存しておいた表層形をキーにし、表層形の長さを値にしてtext_dに格納する。
- text_dの要素の値が最大になるキーを全て出力する。
【ポイント】
- 最長一致:ここでは、最も連続する名詞を指す。
単語の出現頻度
文章中に出現する単語とその出現頻度を求め,出現頻度の高い順に並べよ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
from collections import Counter result = [] sentence = [] with open("neko.txt.mecab") as f: for line in f: l1 = line.split("\t") if len(l1) == 2: l2 = l1[1].split(",") sentence.append({"surface": l1[0], "base": l2[6], "pos": l2[0], "pos1": l2[1]}) if l2[1] == "句点": result.append(sentence) sentence = [] text_l = [] for lis in result: for dic in lis: if dic["surface"] != "": text_l.append(dic["surface"]) c35 = Counter(text_l) print(c35.most_common()) |
【出力結果】
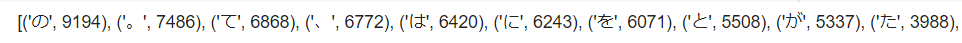
【処理の流れ】
- Counterをimportする。
- 前半の流れは、問30と同じなので説明を省略する。
- 空のlistを定義する。
- 表層形が空の場合も考えられるので、条件式で、定義しておく。
- Counterオブジェクトにtext_lを渡す。
- Counter.most_common()を使用して、単語の出力数が多い順に並べる。
【ポイント】
- Counterオブジェクト:引数にリストやタプルを受け取る。Counterオブジェクトは、dictのサブクラスで、キーに要素、値に出現回数という形のデータを持つ。戻り値は、Counterオブジェクト。
- Counter.most_common()メソッド:要素の出現回数を降順に並べ替えて出力する。
頻度上位10語
出現頻度が高い10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
!pip install japanize-matplotlib import matplotlib.pyplot as plt import japanize_matplotlib #count c36 = Counter(text_l) word, count = zip(*c36.most_common(10)) #plot fig, ax = plt.subplots() ax.bar(word, count) plt.show() |
【出力結果】
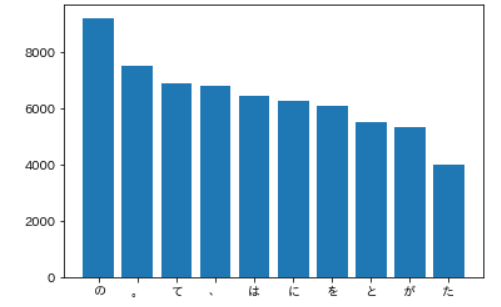
【処理の流れ】
- japanize-matplotlibをインストールする。
- 2つのライブラリをimportする。
- 問35のtext_lをもとに、Counterオブジェクトを作成し、most_common(10)メソッドを使用する。
- zip(*)を使用し、most_common(10)の出力結果をアンパックする
- x軸に単語、y軸に出現回数を指定して、棒グラフを表示する
【ポイント】
- japanize-matplotlib:matplotlib上で、日本語を表示させるためのモジュール。
- Counter.most_common()メソッドの引数:引数にintを指定することで、出現回数の多いn個分の要素を出力する。
- zip(*):*(アスタリスク)を引数に指定することで、要素をアンパックすることができる。
「猫」と共起頻度の高い上位10語
「猫」とよく共起する(共起頻度が高い)10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
text_l_37 = [] for lis in result: if any(d["base"] == "猫" for d in lis): for dic in lis: text_l_37.append(dic["surface"]) #count c_37 = Counter(text_l_37) word, count = zip(*c_37.most_common(10)) #plot fig, ax = plt.subplots() ax.bar(word, count) plt.show() |
【出力結果】
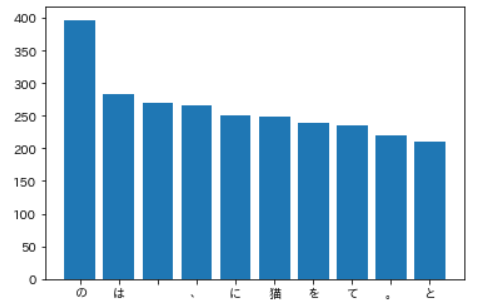
【処理の流れ】
- 問35で作成したresultを用いる。
- 1文中に”猫”が存在すれば、各形態素の表層形をtext_l_37に追加する。
- 以下の流れは、問36と同じなので説明を省略する。
【ポイント】
- 共起:文書や文において、ある文字列とある文字列が同時に出現すること。ここでは、最も”猫”と同時に出現する10単語を求め、グラフ化する。
ヒストグラム
単語の出現頻度のヒストグラムを描け.ただし,横軸は出現頻度を表し,1から単語の出現頻度の最大値までの線形目盛とする.縦軸はx軸で示される出現頻度となった単語の異なり数(種類数)である.
【コード】
|
1 2 3 4 5 6 7 8 9 10 |
#count c38 = Counter(text_l) word, count = zip(*c38.most_common()) #plot fig, ax = plt.subplots() ax.hist(count, range=(1, 10)) plt.xlabel("出現頻度") plt.ylabel("種類数") plt.show() |
【出力結果】
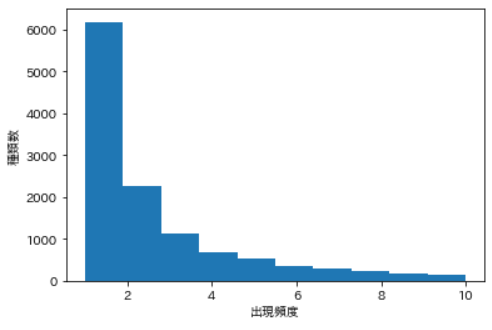
Zipfの法則
単語の出現頻度順位を横軸,その出現頻度を縦軸として,両対数グラフをプロットせよ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#count c39 = Counter(text_l) word, count = zip(*c39.most_common()) #plot x = count y = ([i + 1 for i, v in enumerate(count)]) fig, ax = plt.subplots() ax.plot(x, y) plt.xscale("log") plt.yscale("log") plt.show() |
【出力結果】
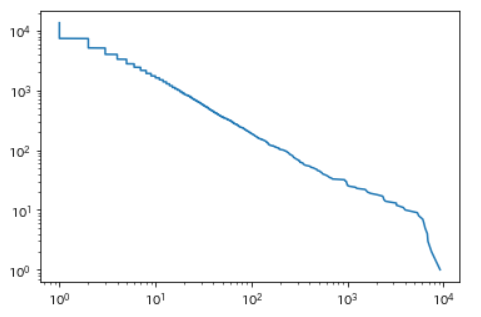
【処理の流れ】
- 前半の流れは、問36と同じなので説明を省略する。
- 単語の出現頻度順位をx軸、単語の出現頻度をy軸として、両対数グラフを表示する。
【ポイント】
- 対数グラフ:対数グラフには、「両対数グラフ」、「片対数グラフ」が存在する。ここでは、グラフの両軸が対数スケールになっている両対数グラフを表示する。
- matplotlib.pyplot.xscale()メソッド:引数に”log”を指定することで、x軸を対数スケールに変換できる。
- matplotlib.pyplot.yscale()メソッド:引数に”log”を指定することで、y軸を対数スケールに変換できる。
おわりに
以上が、言語処理100本ノック第4章の解説になります。MeCabのインストール方法については、様々なサイトで紹介されていましたがエラーが表示され、実行することができませんでした。しかし、情報収集を続けることで問題を解決することができ、第4章を解き終えることができました。実装方法は、一通りではないので、自分なりのコードで挑戦してみてはいかかでしょうか。次は、言語処理100本ノック第5章の解説を行っていきます。
K.Y

