
はじめに
ここ数年、Transformerは人工知能分野で大きなブレイクスルーをもたらし、その後に続くBERTやGPT-3をはじめとする言語モデルの主要なアーキテクチャとなっています。しかしながら、Transformerはその計算方法から計算コストが高く、近年のモデルのパラメータ数も増加の一途をたどっています。そこで、この記事ではTransformerに代わる新たなモデルアーキテクチャとして注目されているMLP-Mixerについて解説します。
概要

MLP-Mixerは2021年5月にGoogleの研究チームが発表しました。MLP-Mixerは多層パーセプトロンのみを用いるというシンプルな構造でありながら、画像分類ベンチマークにおいてCNNやTransformerに引けを取らない結果を示しました。CNNやTransformerでは高精度をマークするためには、その計算方法から計算コストが膨大になっていましたが、MLP-Mixerは計算量を抑えつつCNNやTransformerと同等の性能であるということが示されています。
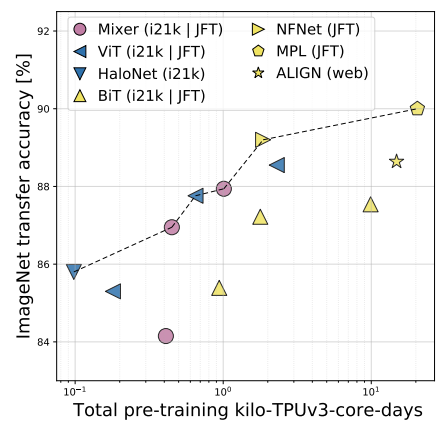
上図は、MLP-Mixerと最先端モデルを比較したものです。縦軸が精度で横軸が計算量を示しています。これを見るとMLP-Mixerは最先端モデルに比べ精度は劣りますが、計算量を抑えられていることが分かります。その他の結果についても原著論文から確認することができます。
アーキテクチャ
次にMLP-Mixerのアーキテクチャを紹介します。
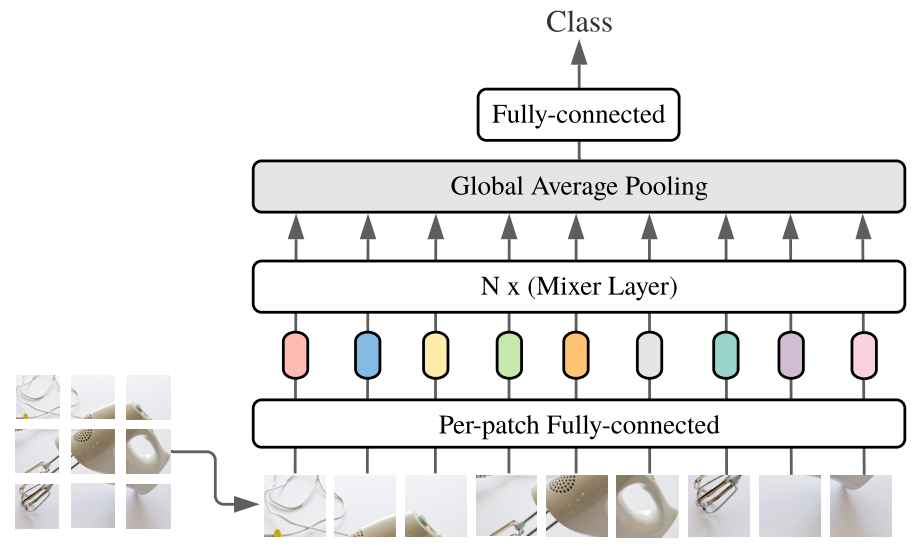
全体像は上図に示す通りです。MLP-Mixerはパッチごとの埋め込み表現を獲得する全結合層、Mixer Layer、Global Average Pooling層、全結合層で構成されています。画像データは上図に示すようにパッチに分割して入力します。N x (Mixer Layer)は次に示すMixer Layerを複数積み重ねたものになります。

Mixer LayerはChannel-mixing MLP(MLP2)とToken-mixing MLP(MLP1)で構成されています。データは左から右に処理されます。パッチごとに処理されたデータが入力されると転置し、チャネルごとにToken-mixing MLP(MLP1)に入力します。Token-mixing MLP(MLP1)は空間位置が異なるパッチの特徴量をミックスする役割を持っています。また、Channel-mixing MLP(MLP2)ではパッチごとにデータを処理し、異なるチャネル間での特徴量をミックスしています。
MLP-Mixerでは、パッチごとの処理とチャネルごとの処理を明確に分け、どちらも行っています。
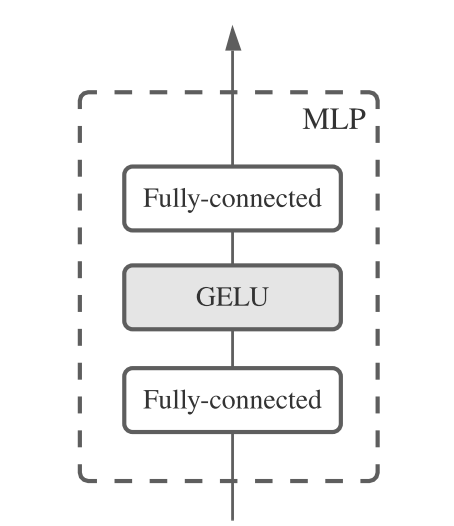
Channel-mixing MLP(MLP2)とToken-mixing MLP(MLP1)があることを紹介しましたが、MLP自体は上に示すように、全結合層とGELUからなるシンプルな構造になっています。
多層パーセプトロンとは
ここまでMLP-Mixerのアーキテクチャを掘り下げて解説してきましたが、ここでMLP-Mixerの基礎となっている多層パーセプトロン(MLP)について解説したいと思います。
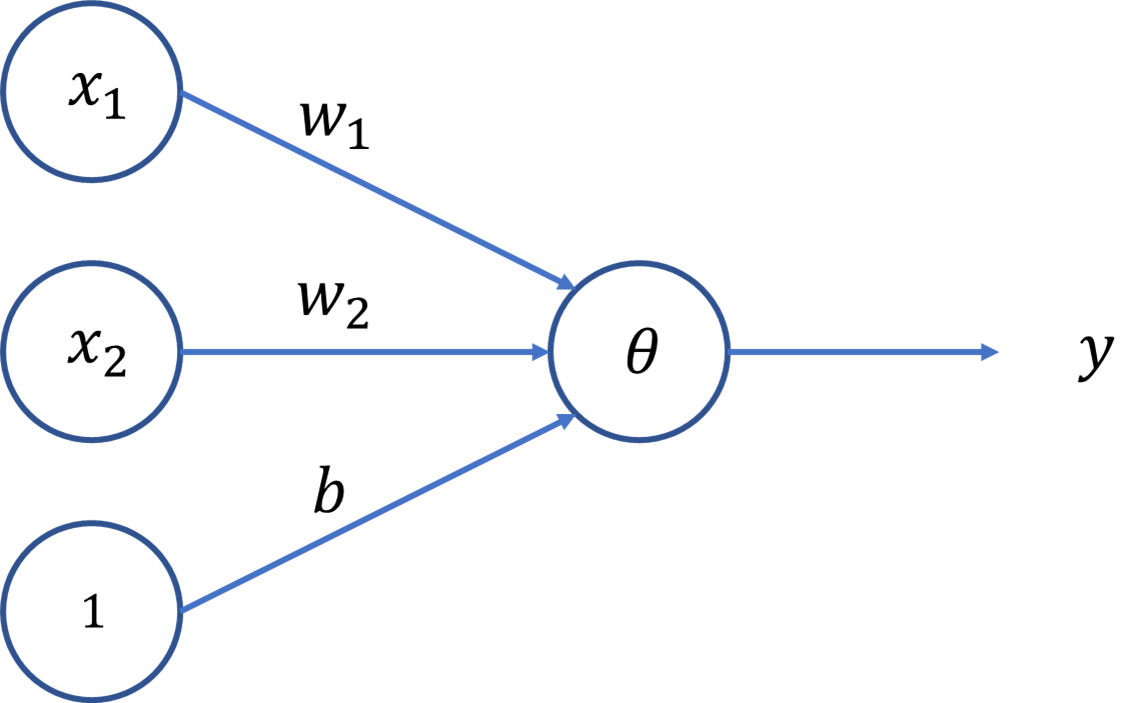
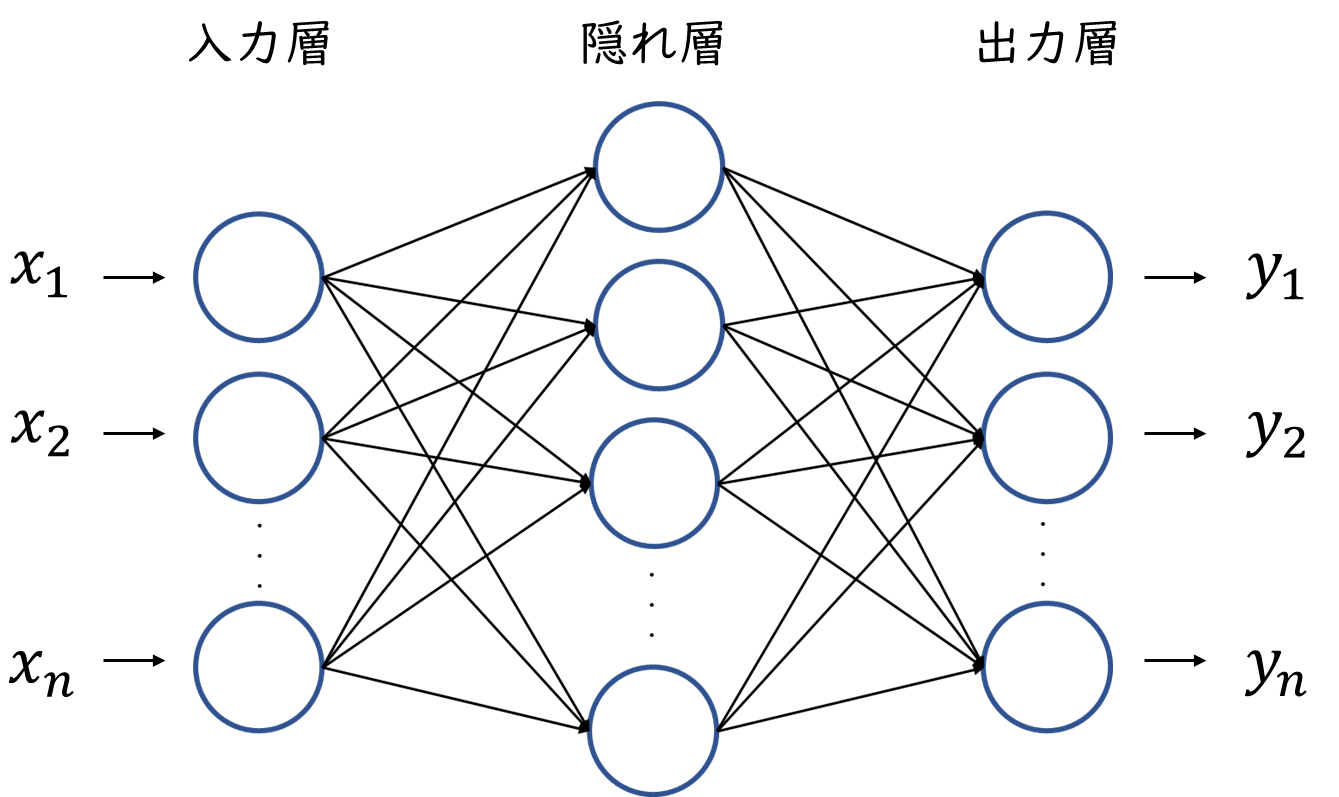
多層パーセプトロンとは複数のパーセプトロンを重ねたものですが、パーセプトロンとは以下の図に示すようになっています。このパーセプトロンでは、入力データxと重みwからyを出力し、その値がある閾値を超えた場合に1を、超えなかった場合に0を返します。
これを式で示すと次のようになります。
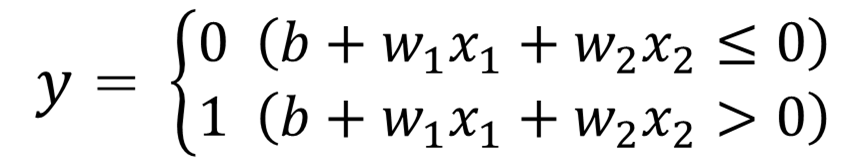
この式に様々な値を入れてもらえばわかりますが、単純パーセプトロンでは分割できないパターン(線形非分離な問題)が存在します。例えば、以下のようなケースです。
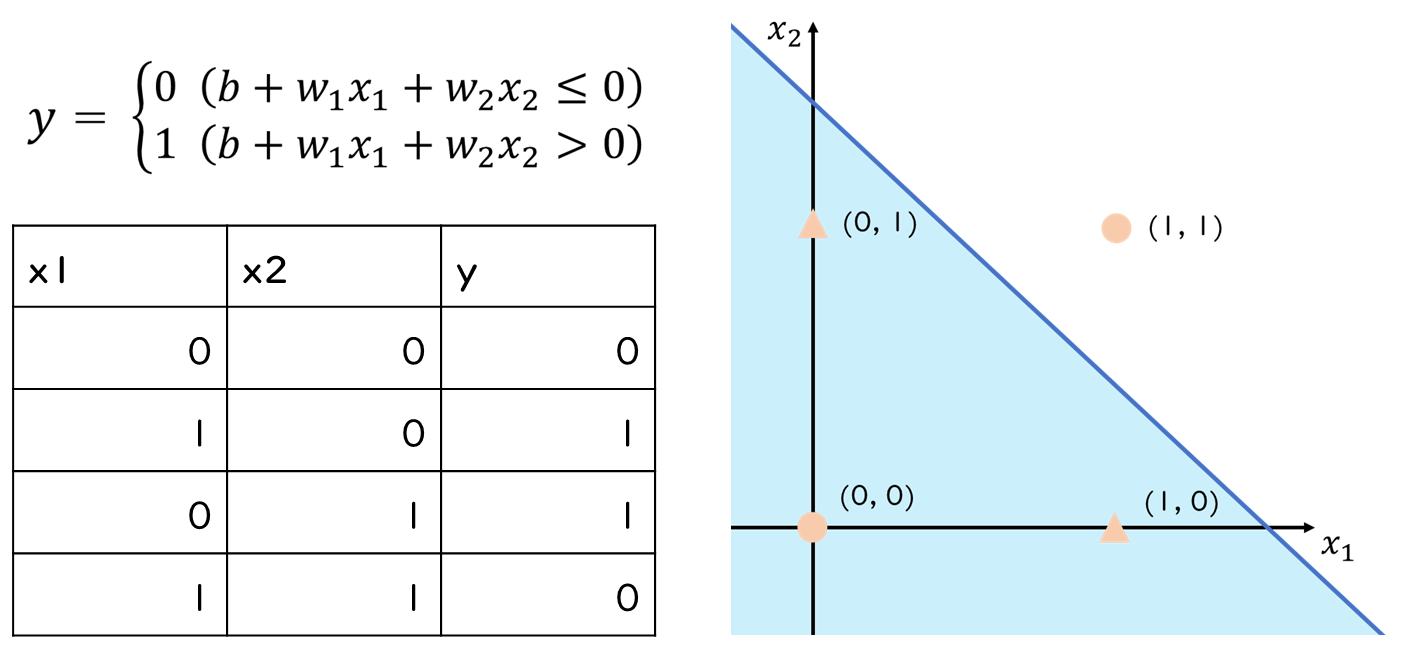
そこで多層パーセプトロンを利用します。多層パーセプトロンとは複数のパーセプトロンを重ね、なおかつ活性化関数を導入したものです。
単純パーセプトロンでは非線形問題を解くことができませんが、パーセプトロンを重ね活性化関数を導入することで非線形問題を解くことができます。MLP-Mixerでは、この多層パーセプトロンをいくつも重ねたものになります。
コード解説
続いてMLP-Mixerのコードを解説したいと思います。google-researchのvision_transformerリポジトリに公開されているmodels_mixer.pyを参照して解説します。
MlpBlock
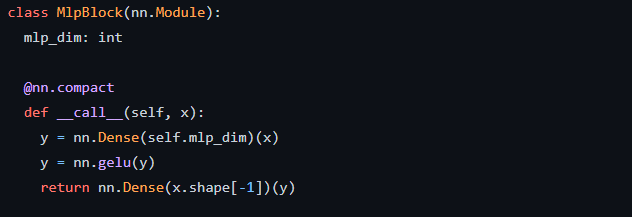
まず、MlpBlockですが、nn.Moduleを継承しクラスとして定義されています。アーキテクチャのところで解説したように全結合層(nn.Dense)とnn.gelu(GELU)が定義されており、3層になっていることが分かります。mlp_dimは最初の全結合層の出力次元数です。
MixerBlock
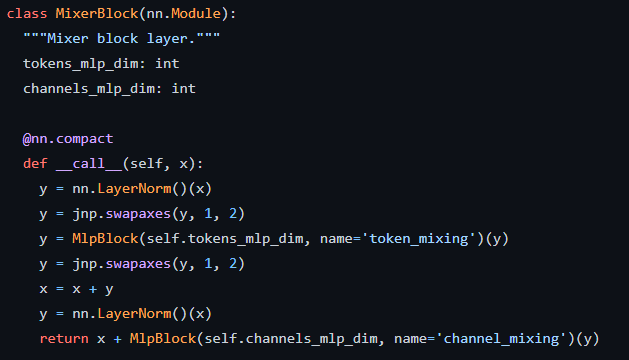
続いてMixerBlockでは、前述のとおり2種類のMlpBlockが定義されており、それぞれname=’token_mixing’とname=’channel_mixing’と名前が付けられています。
tokens_mlp_dimとchannels_mlp_dimは、それぞれのMlpBlockにおける最初の全結合層の出力次元数です。
nn.LayerNorm()(x)では入力されたデータの標準化を行っています。
jpn.swapaxes(y, 1, 2)では行列の転置を行っています。
x = x + y はMixer Layerの図で示されるSkip-connectionsにあたります。
最後、returnで返される計算もSkip-connectionsが適用されていることがわかります。
MlpMixer
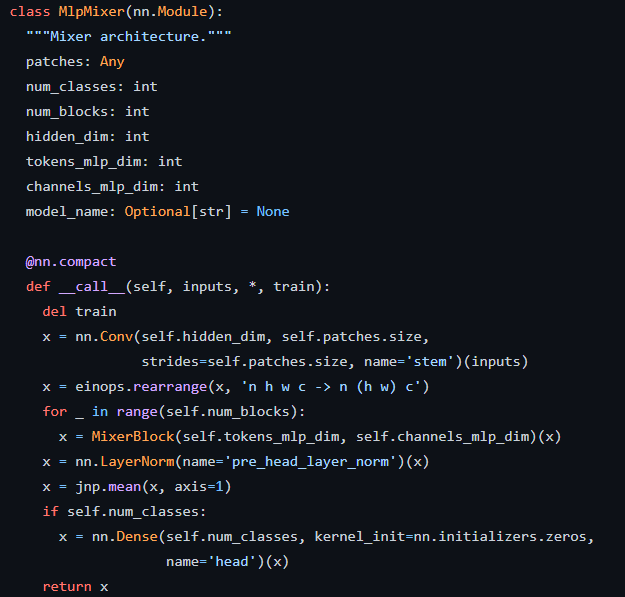
最後にMlpMixerクラスです。引数が様々ありますが以下の意味で使われていると思います。
- patches:パッチの情報、patches.sizeでパッチサイズを取得している
- num_classes:分類するクラス数
- num_blocks:MixerBlockの数
- hidden_dim:入力した画像データをパッチに分割する際の出力次元数
for文でMixerBlockを呼び出しているところは、Mixer Layerを複数積み重ねていることを意味します。
その後、以下のコードでGlobal Average Pooling処理をしています。
- x = nn.LayerNorm(name=’pre_head_layer_norm’)(x)
- x = jnp.mean(x, axis=1)
最後の全結合層(nn.Dense)でクラスの推定を行っています。
おわりに
今回はMLP-Mixerについて解説しました。単純な構造かつ単純な操作のみで、最先端と同等の精度を達成している点、またその計算量コストを低く抑えられることは驚くべき点かと思います。画像分類タスク以外にも応用が可能とのことなので、今後多方面にわたる領域での活用が期待されます。
K. K

