
この記事では、言語処理100本ノックの解説を行っていきます。
言語処理100本ノックとは
言語処理100本ノックをご存じでしょうか?言語処理100本ノックとは、プログラミング、データ分析、研究のスキルを楽しく習得することを目指した問題集です。言語処理100本ノックの問題を自分なりのコードで解きましたので、ポイントと処理の流れを踏まえて、解説していきます。
問題と解説
文字列の逆順
文字列”stressed”の文字を逆に(末尾から先頭に向かって)並べた文字列を得よ.
【コード】
|
1 2 |
text1 = "stressed" print(text1[::-1]) |
【出力結果】

【処理の流れ】
- text1[::-1]を指定して、与えられた文字列を逆から取得する。
【ポイント】
- スライス操作:スライス操作ではインデックスを[start : stop : step]のようにして指定する。また、要素の最後のインデックスは-1。
「パタトクカシーー」
「パタトクカシーー」という文字列の1,3,5,7文字目を取り出して連結した文字列を得よ.
【コード】
|
1 2 |
text1 = "パタトクカシーー" print(text1[1::2]) |
【出力結果】

【処理の流れ】
- 奇数のインデックスを指定して、要素を抽出する。
【ポイント】
- 奇数のインデックスを抽出する。
「パトカー」+「タクシー」=「パタトクカシーー」
問)
「パトカー」+「タクシー」の文字を先頭から交互に連結して文字列「パタトクカシーー」を得よ.
「パトカー」+「タクシー」の文字を先頭から交互に連結して文字列「パタトクカシーー」を得よ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 |
text1 = "パトカー" text2 = "タクシー" lis = [] for x, y in zip(text1, text2): lis.append(x) lis.append(y) lis_j = "".join(lis) print(lis_j) |
【出力結果】

【処理の流れ】
- zip()を使用して、それぞれの文字列の要素をまとめる。
- まとめた要素をアンパックし、それぞれの要素をリストに追加する。
- join()でリストの要素を連結し、出力する。
【ポイント】
- zip()関数(組み込み):複数のイテラブルオブジェクトを引数に、それぞれの要素をひとまとめにする。(主にfor文と併用されることが多い印象)
- str.join()メソッド:イテラブルオブジェクトを引数に、指定した文字列でイテラブルオブジェクトのすべての要素を連結する。戻り値はstr型。
円周率
“Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics.”という文を単語に分解し,各単語の(アルファベットの)文字数を先頭から出現順に並べたリストを作成せよ.
【コード】
|
1 2 3 4 5 6 7 8 9 |
text1 = "Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics." text1_r = text1.replace(",", "") lis = [] for x in text1_r.split(): lis.append(x) len_l = [len(y) for y in lis] print(len_l) |
【出力結果】
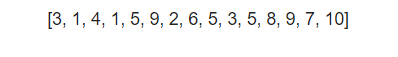
元素記号
“Hi He Lied Because Boron Could Not Oxidize Fluorine. New Nations Might Also Sign Peace Security Clause. Arthur King Can.”という文を単語に分解し,1, 5, 6, 7, 8, 9, 15, 16, 19番目の単語は先頭の1文字,それ以外の単語は先頭の2文字を取り出し,取り出した文字列から単語の位置(先頭から何番目の単語か)への連想配列(辞書型もしくはマップ型)を作成せよ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
text1 = "Hi He Lied Because Boron Could Not Oxidize Fluorine. New Nations Might Also Sign Peace Security Clause. Arthur King Can." num = [1, 5, 6, 7, 8, 9, 15, 16, 19] dic = {} text1_r = text1.replace(".", "") text1_lis = text1_r.split() for i, v in enumerate(text1_lis): if i + 1 in num: dic[v[0]] = i + 1 else: dic[v[:2]] = i + 1 print(dic) |
【出力結果】
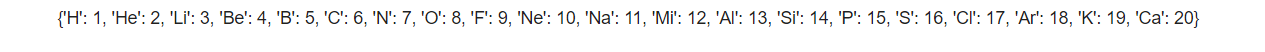
【処理の流れ】
- 問題で指定された番号をリストとして、変数に保存する。
- 空の辞書を作成する。
- replace()で不要な文字を削除し、split()で空白文字ごとに文字列を区切る。
- enumerate()で各文字列のインデックスと要素を取得する。
- 保存してある番号と各文字列のインデックス+1を比較して、同じであれば文字列を1文字に、それ以外は2文字に変換し、インデックス+1を要素にして、辞書に追加していく。
【ポイント】
- enumerate()関数(組み込み):イテラブルオブジェクトを引数にし、インデックスと要素の順に値を返す。
n-gram
与えられたシーケンス(文字列やリストなど)からn-gramを作る関数を作成せよ.この関数を用い,”I am an NLPer”という文から単語bi-gram,文字bi-gramを得よ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 |
text1 = "I am an NLPer" def ngram(n, word): lis = [] for i in range(len(word) - n + 1): lis.append(word[i:i+n]) return lis print(f"単語bi-gram:{ngram(2, text1.split())}") print(f"文字bi-gram:{ngram(2, text1)}") |
【出力結果】

【処理の流れ】
- 関数を定義し、空のリストを定義する。
- len(word) – n + 1回、文字列を1文字ずつずらしながらリストに追加していく。 単語n-gramは、関数の引数に、split()させた値を渡すことで、もとめることができる。
【ポイント】
- n-gramの理解
集合Permalink
“paraparaparadise”と”paragraph”に含まれる文字bi-gramの集合を,それぞれ, XとYとして求め,XとYの和集合,積集合,差集合を求めよ.さらに,’se’というbi-gramがXおよびYに含まれるかどうかを調べよ.
【コード1】
|
1 2 3 4 5 6 7 8 9 10 11 |
text1 = "paraparaparadise" text2 = "paragraph" X = set(ngram(2, text1)) Y = set(ngram(2, text2)) print(f"X:{X}") print(f"Y:{Y}") print(f"和集合:{X | Y}") print(f"積集合:{X & Y}") print(f"差集合:{X - Y}") |
【出力結果1】

【コード2】
|
1 2 3 4 5 6 |
#"se"がXに含まれるか判定 if "se" in X: print("Xに存在します") else: print("Xに存在しません") |
【出力結果2】

【コード3】
|
1 2 3 4 5 6 |
#"se"がYに含まれるか判定 if "se" in Y: print("Yに存在します") else: print("Y在しません") |
【出力結果3】

【処理の流れ】
- 2つの文字列それぞれでbi-gramをもとめ、set()を使用して、集合に変換する。
- set()の演算子を使用する。
- in演算子を用いて、要素の判定を行う。
【ポイント】
- set()関数(組み込み):集合オブジェクトに変換する。また、集合オブジェクトに変換されることで、集合演算子を使用することができる。
テンプレートによる文生成
引数x, y, zを受け取り「x時のyはz」という文字列を返す関数を実装せよ.さらに,x=12, y=”気温”, z=22.4として,実行結果を確認せよ.
【コード】
|
1 2 3 4 |
def fun(x, y, z): print(f"{x}時の{y}は{z}") fun(12, "気温", 22.4) |
【出力結果】

【処理の流れ】
- 問題通り、3つの引数を持った関数を定義する。
- fstringsを使用して、色々な型をstr型にフォーマットし、出力する。
【ポイント】
- fstrings:{}内に値を指定して、文字列にフォーマットする。
暗号文
与えられた文字列の各文字を,以下の仕様で変換する関数cipherを実装せよ.英小文字ならば(219 – 文字コード)の文字に置換 その他の文字はそのまま出力 この関数を用い,英語のメッセージを暗号化・復号化せよ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
text1 = "Hello World" def cipher(w): lis = [] for i in w: if i.islower(): i = chr(219 - ord(i)) lis.append(i) return "".join(lis) enc = cipher(text1) print(f"暗号化:{enc}") print(f"復号化:{cipher(enc)}") |
【出力結果】

【処理の流れ】
- 空のリストを定義する。
- 空のリストを作成し、islower()で小文字の判定を行う。
- 条件式がTrueの場合、ord()を使用して、小文字を文字コードに変換し、219で引く。219で引いた文字コードをchr()を使って、文字列に変換する。
- 文字列をリストに追加していく。
- join()を使って、リストの要素を結合する。
- 復号化を出力するときは、再び関数をコールする必要があるので、注意が必要だ。
【ポイント】
- ord()関数(組み込み):文字列を文字コードに変換する。
- chr()関数(組み込み):文字コードを文字列に変換する。
- str.islower()メソッド:小文字判定を行う。つまり、文字列が全て小文字であれば、Trueを返す。
- 文字コードを219で引いて、文字列に変換すると、元の小文字(英字)からアルファベット順が逆の小文字(英字)が出力される。
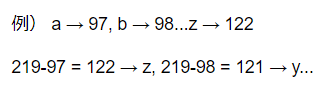
- if文ブロックの処理が正常に実行されたら、if文ブロックを抜けて、次の処理に移る。
Typoglycemia
スペースで区切られた単語列に対して,各単語の先頭と末尾の文字は残し,それ以外の文字の順序をランダムに並び替えるプログラムを作成せよ.ただし,長さが4以下の単語は並び替えないこととする.適当な英語の文(例えば”I couldn’t believe that I could actually understand what I was reading : the phenomenal power of the human mind .”)を与え,その実行結果を確認せよ.
【コード】
|
1 2 3 4 5 6 7 8 9 10 11 |
import random text1 = "I couldn’t believe that I could actually understand what I was reading : the phenomenal power of the human mind ." lis = [] for i in text1.split(): if len(i) > 4: i = i[0] + "".join(random.sample(i[1:-1], len(i) - 2)) + i[-1] lis.append(i) print(" ".join(lis)) |
【出力結果】

【処理の流れ】
- randomモジュールをimportする。
- 空のリストを定義し、文字列をsplit()で区切る。
- 単語の長さを判定し、4文字よりも多ければ、先頭と末尾の文字を残し、それ以外の文字をsample()を使用して、ランダムに並び替える。
- sample()の戻り値はlistなので、join()を使って要素を結合する。
- 単語をリストに追加していく。
- 出力する際は、join()で要素を結合することを忘れてはいけない。
【ポイント】
おわりに
以上が、言語処理100本ノック第1章の解説になります。個人的には、n-gramを知らなかったので苦戦しました。実装方法は、一通りではないので、自分なりのコードで挑戦してみてはいかかでしょうか。次は、言語処理100本ノック第2章の解説を行っていきます。
K.Y

