
先日、オンラインで開催された2021年度 人工知能学会全国大会(第35回)に参加してきましたので、会議の様子や興味深かった研究について報告します。
人工知能学会全国大会について

人工知能学会全国大会は人工知能に関連する国内の研究者が一堂に集い、研究成果を発表する場として開催している年次大会です。
人工知能に関連する最新の技術動向、新しい研究成果やアイデアなどの発表を通して意見交換・交流を行っており、研究成果発表に加え、著名な講師をお招きした基調・招待講演やチュートリアル、魅力的なテーマを取り上げた各種セッションやパネル討論、スポンサーの皆様によるオンライン展示など、多彩なイベントを企画・開催しています。
人工知能学会全国大会 概要
- 開催形式:オンライン(zoom)
- 日時:6/8~6/11
- 参加者数:2320
- 論文発表件数:529
- スポンサー申込数:51

セッションの種類ごとに色分けされています。
タイムテーブルでは、セッションをクリックするとzoomで参加できます。
また、マイスケージュールにあらかじめ参加したいセッションを追加できる機能があったため、曜日ごとにセッションをまとめることができて、とても便利でした。
参加者数
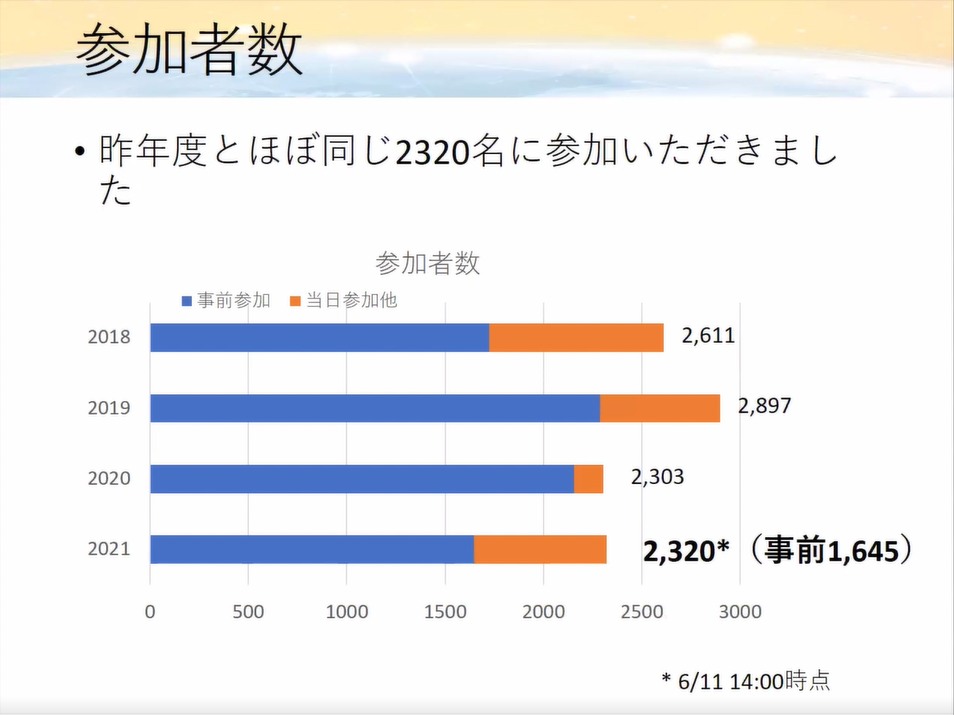
参加者数は、昨年度と変化がありません。
オンラインでの開催だったので、コロナの影響を受けていないように思えます。
論文発表件数
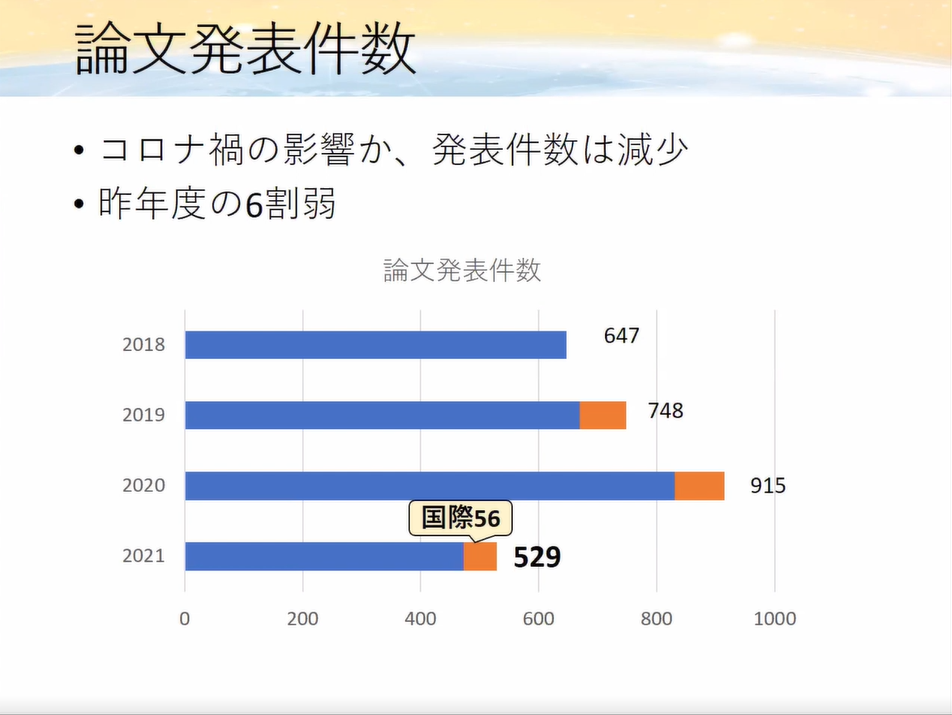
論文発表件数は上昇傾向にありましたが、昨年度の6割弱まで減少。
コロナの影響もあってか、あまり研究が進まなかったのではないかと予測できます。
スポンサー申込数
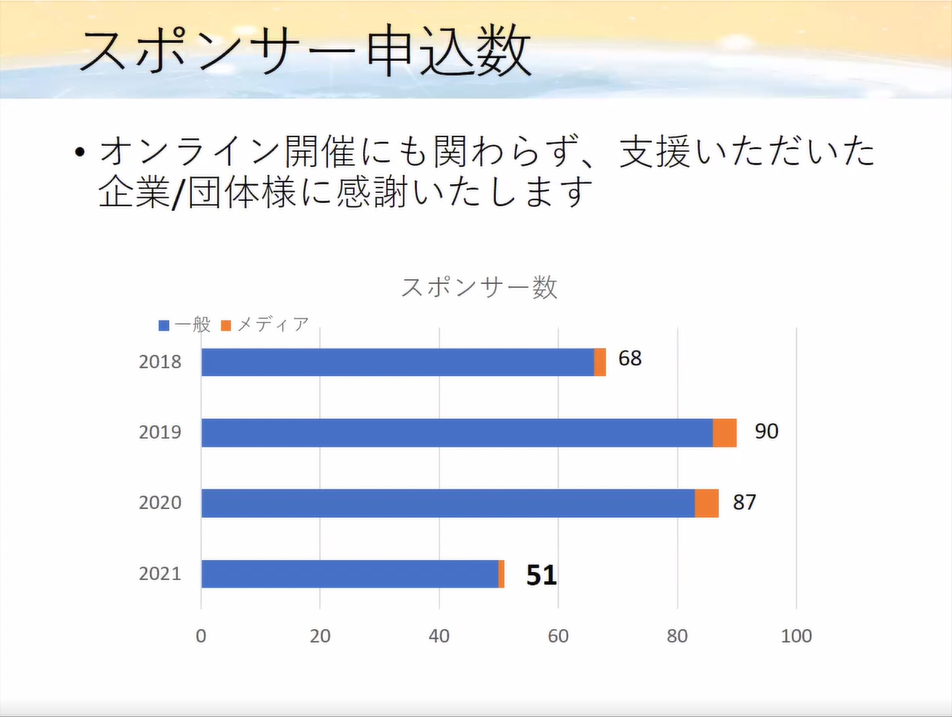
スポンサー申込件数も論文発表件数と同じく、昨年度にくらべ減少しています。
興味深かった研究
人工知能学会全国大会に参加して、興味深かったセッションをいくつか紹介します。
- 分野:回帰、自然言語処理
背景として、リスク回避のため様々な情報をもとに企業を評価して、株の売買の意思決定することが重要であり、インターネット上の情報のリアルタイムな分析が強く求められていると考えている。
そこで、自然言語処理を用いたニュースの評価と企業の評価を組み合わせた合計評価値を導入することを提案し、重回帰モデルとニューラルネットワークに提案法を適用させ、予測誤差の比較を行っていた。
実験の条件として、業種の異なる個別企業銘柄を5社選定し、各企業それぞれの4本値と合計評価値を入力変数として、翌日の始値を予測する。また、2020年1月6 日~2020年12月28日までのニュースデータ、株価データを用いていた。
以下が、実験の流れである。
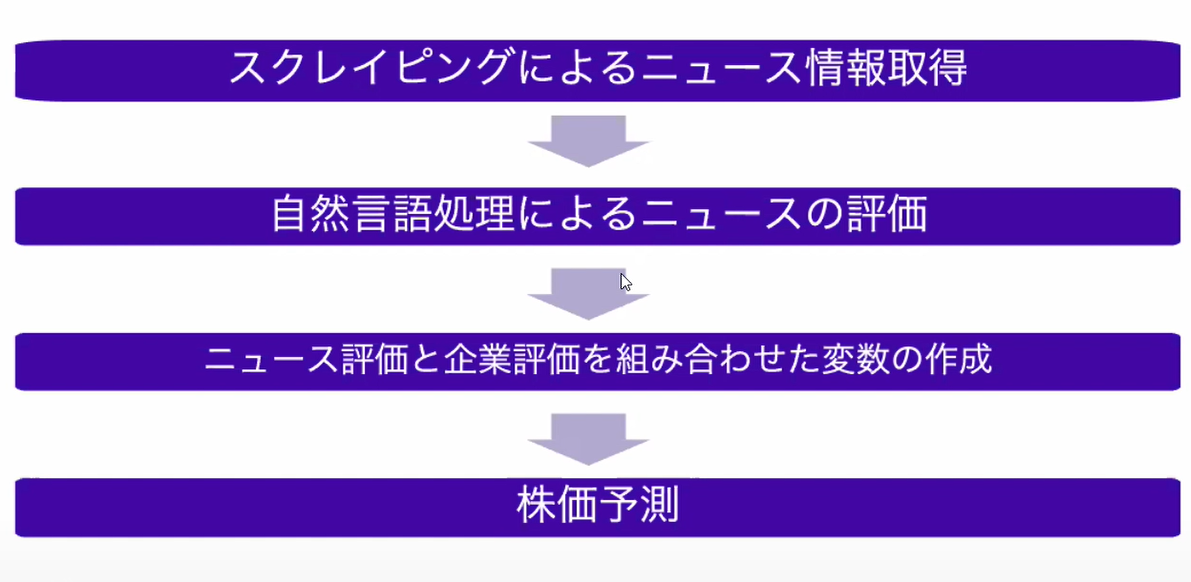
自然言語処理によるニュースの評価は、以下の手順で行っていた。
1.形態素解析を行い名詞のみ取得
2.ポジティブワードが出るたびに+1、ネガティブワードが出るたびに-1してその合計を評価値とする
3.1日にニュースが複数ある場合、それぞれの記事の評価値を合計したものをその日の評価値とする
4.休業日の評価値は前日の評価値と合計する
企業評価については、以下の表をもとに求めていた。
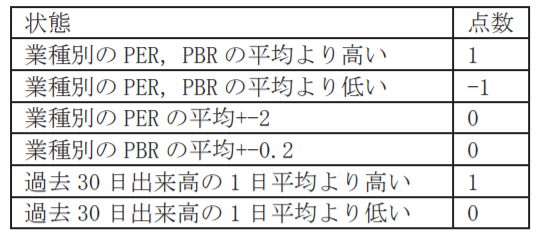
企業評価値とネガティブ・ポジティブの評価値の合計で新たな説明変数を作成していた。
(この説明変数のことを合計評価値と言っていた)
以下の表では、重回帰モデル、ニューラルネットワークモデルにおいて4本値のみの場合と、提案手法を適用した場合の検証結果を示している。
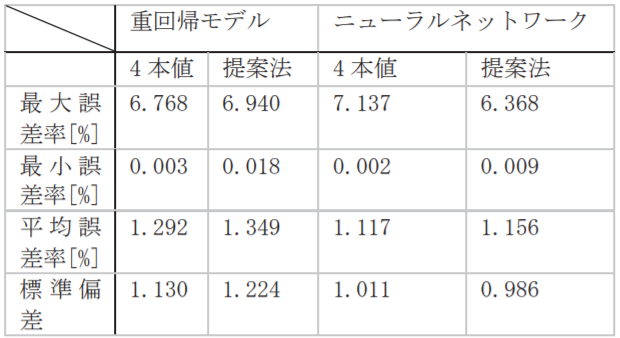
検証結果として、ニューラルネットワークに提案手法を適用した場合の有効性を確認したとのこと。
今後の課題として、データ数を増やして検証すること、ニュースの評価方法の検証という2つを上げていた。
- 分野:テキスト分類
背景として、法学部の授業内でWebシステム上で学生が弁護士役となり、架空の⺠事事件の解決にあたるという設定の教育プログラム(訴訟ロールプレイ)を、法学部授業の中で運用している。このロールプレイは、学生が書き込むクローズド・エンド型の質問文に対して、証人役の者が回答することによって進行するが、クローズド型の質問文を作成できない学生に対するスタッフの添削指導の負担が考えられていた。
そこで、クローズドでない質問文を自動検出して、学生に注意を促したり、回答作業前に自動的に除去したりすることを目的とし、複数の機械学習アルゴリズムを用いて、クローズド・エンド型質問文であるか否かを判定させることを検証した。
この研究では、仮説の立て方がとても勉強になった。
英語は日本語に比べ、疑問文では助動詞やWh-疑問文詞が文の先頭に現れる。という事から、日本語より英語を学習に用いた方がクローズド・エンド型の質問を判定しやすいのではないかと仮説を立てていた。

研究内容としては、
1.日本語と英語それぞれを入力データとして扱う
2.特徴量の作成方法として、Paragraph VectorとTF-IDFを用いた
3.最後に作成した特徴量に対して3種類のアルゴリズムを用いて分類精度を比較
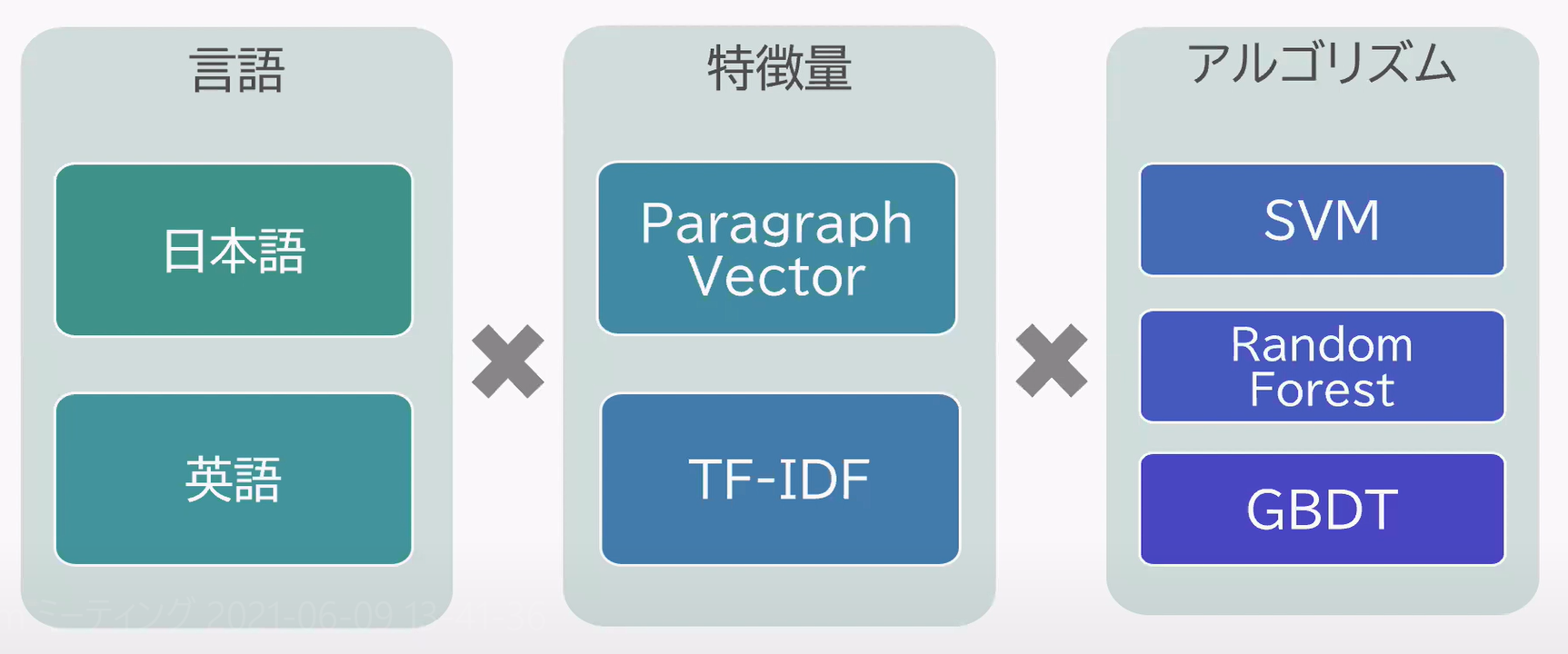
検証結果として、日本語文のままの方が高い精度の場合が多く、仮説は立証されなかった。
また、このような結果になった理由については十分な検討を行えていないとのことだが、今後の教育システムの改良に期待したい。
- 分野:分類、決定木
背景として、決定木は解釈性が高い識別器であるが、過学習を起こしやすく、十分なデータ数がない場合予測精度が悪化する恐れがある。一方、アンサンブル識別器は過学習を防ぎ、高い予測精度を示すが複数の決定木を合成しているため、解釈性が失われてしまうことが考えられてきた。
そこで研究目的として、アンサンブル識別器に近い予測性能を持つ単一の決定木を学習できれば、予測性能と解釈性を備えた有益なモデルになると提案した。
近年では、その代表的な手法にBorn Again Treesがあるが、データ生成の際に膨大な計算量が必要となる上に、対象データの分布から外れたデータも多数生成してしまうため学習した決定木が複雑になり解釈性が低下する恐れがある。
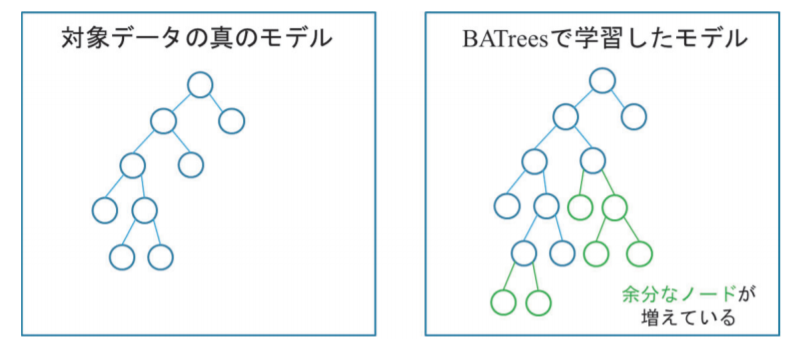
そこで本研究では、生成モデルであるAutoencoderと、オーバーサンプリング手法であるSMOTEを用いて、対象データの分布に従うデータを少ない計算量で生成し、高い予測精度を持つシンプルな決定木の学習方法を提案している。
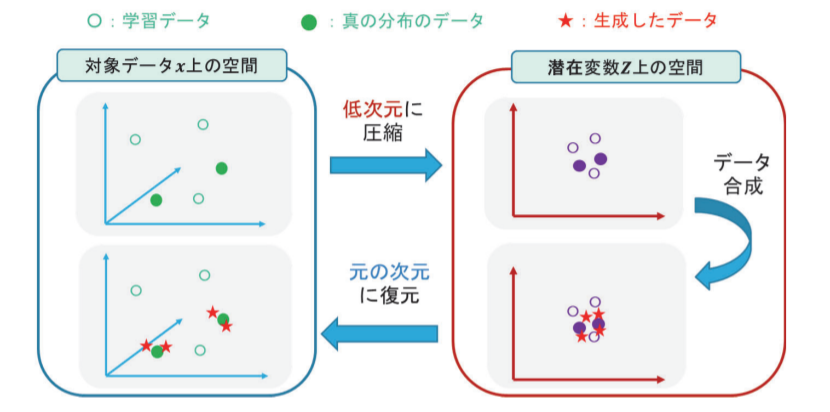
実データを用いた検証では、提案手法の活用により従来では複雑なモデルしか分析を行えなかった問題に対しても、精度を維持しつつ単純なモデルでも分析を行えることを示した。
- 分野:画像認識、深層学習
背景として、スポーツ×画像認識が盛んになっているが、一般向けには導入されていないことが挙げられる。
そこで、一般の人でも使用できるシステムを作ることを前提とし、テニスにおけるサーブの落下地点を選手の骨格情報から予測することを目的としていた。
先行研究としては、卓球におけるサーブの落下地点を予測する手法がある。
しかし、テニスの動画に移る選手は卓球に比べて小さいため、この手法をテニスに適用すると骨格検出の性能が落ちてしまい、落下地点予測に失敗するという問題が生じる。
本研究では、骨格検出を選手領域の認識と認識した領域内での骨格の検出という2段階に分けることで、検出性能を改善させることを提案していた。
使用モデルとして、
– 1段階骨格推定
– Higher HRNet
– 2段階骨格推定
– 人物検出:CenterNet hourglass
– 骨格推定:HRNet W48
– 落下地点予測モデル:LSTM
を用いていた。
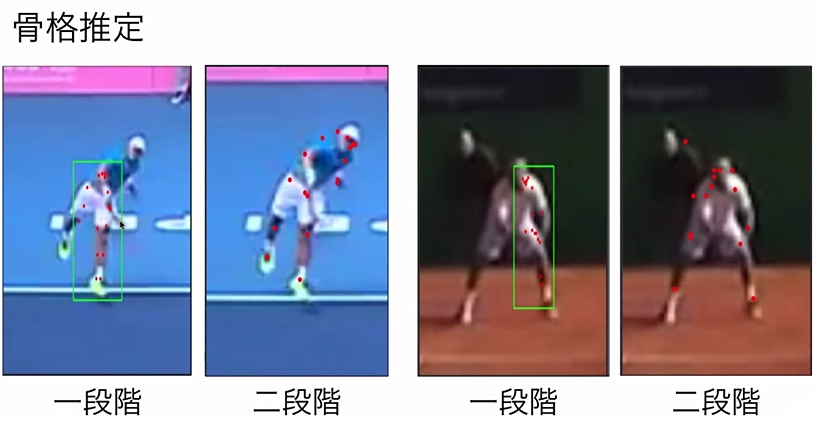
実験としては、手前の選手と奥の選手、2パターンでボールの落下地点を予測した。
検証結果では下の表からわかるように、手前の選手ではボールの落下地点をほぼ正確に予測できているのに対し、奥の選手ではボールの予測位置がボールの落下位置から横に2cmもずれていた。
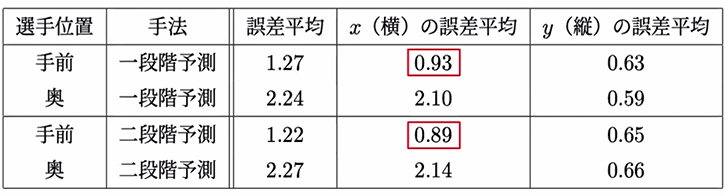
今後の課題として、奥の選手に対する落下位置の予測精度を上げていきたいと言っていたが、
手前の選手に対する落下位置の予測精度は充分に高いため、カメラを2つ用意してテニスコートの手前と奥に付ければいいのではないかと思った。
また、テニスに限らずどのスポーツにも応用できる可能性があるので、今後の研究に期待したい。
まとめ
初めて人工知能学会全国大会に参加しました。
コロナの影響でオンラインでの参加でしたが、オンラインならではの良さがあり、最後まで集中して参加することができました。
研究内容としては、理解できる発表や今の知識では理解できない発表もありましたが、
研究の流れや仮説の立て方など、とても参考になったので今後の学習に活かしていきます。
来年は、国立京都国際会館での開催予定なので、興味があれば参加してみてください。
- 国立京都国際会館へのアクセス:https://www.icckyoto.or.jp/visitor/access/getting_here/

