
概要
- 今回は前回実行した予測プログラムPredict_on_GPU.ipynbの詳細について解説します。
ライブラリ読み込み
単語分割にMeCabを使用するので、インストールします。
また、予測結果出力に日本語を表示するためにjapanese_matplotlibもインストールしています。
|
1 2 3 4 |
!apt install aptitude !aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y !pip install mecab-python3==0.6 !pip install japanize_matplotlib |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import numpy as np import os import time import MeCab import preprocess_utils import model import weight_utils import tensorflow.keras as keras import tensorflow as tf print(tf.__version__) import matplotlib.pyplot as plt import japanize_matplotlib %matplotlib inline |
また、下記のプログラムの詳細は以下の通りです。
- preprocess_utils:前処理用のプログラム
- model:Transformer
- weight_utils:学習済みモデルの読み書き用のプログラム
日英翻訳データダウンロード
日英翻訳データをここからダウンロードし、展開しています。
jpn.txtが対象のデータになります。
|
1 2 |
!wget http://www.manythings.org/anki/jpn-eng.zip !unzip ./jpn-eng.zip |
データ読み込み
ここでは、jpn.txtからデータを読み込んで、学習データとテストデータに分割しています。
preprocess_utils.CreateDataのパラメータは以下の通りです。
- corpus_path:読み込むファイルのパス
- do_shuffle:データをシャッフルするか
- seed_value:シャッフルに使用するシード値
- split_percent:学習に使うデータのパーセンテージ
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
dataset = preprocess_utils.CreateData( corpus_path = './jpn.txt', do_shuffle=True, seed_value=123, split_percent=0.95 # 学習データの割合 ) train_source, train_target, test_source, test_target, train_licence, test_licence = dataset.split_data() print('**** Amount of data ****') print('train_source: ', len(train_source)) print('train_target: ', len(train_target)) print('test_source: ', len(test_source)) print('test_target: ', len(test_target)) print('\n') print('**** Train data example ****') print('Source Example: ', train_source[0]) print('Target Example: ', train_target[0]) print('Licence: ', train_licence[0]) print('\n') print('**** Test data example ****') print('Source Example: ', test_source[0]) print('Target Example: ', test_target[0]) print('Licence: ', test_licence[0]) |
- 実行すると、学習データ、テストデータのデータ数とデータのサンプルを出力します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
**** Amount of data **** train_source: 52857 train_target: 52857 test_source: 2782 test_target: 2782 **** Train data example **** Source Example: Look after Tom. Target Example: トムの面倒を見てて。 Licence: CC-BY 2.0 (France) Attribution: tatoeba.org #2782602 (CK) & #2125677 (bunbuku) **** Test data example **** Source Example: You should tell your mother as soon as possible. Target Example: できるだけ早く、お母さんに知らせたほうがいい。 Licence: CC-BY 2.0 (France) Attribution: tatoeba.org #3554418 (CK) & #3553337 (arnab) |
前処理
ここでは、学習データ、テストデータの前処理を行っています。
前処理の内容は以下の通りです。
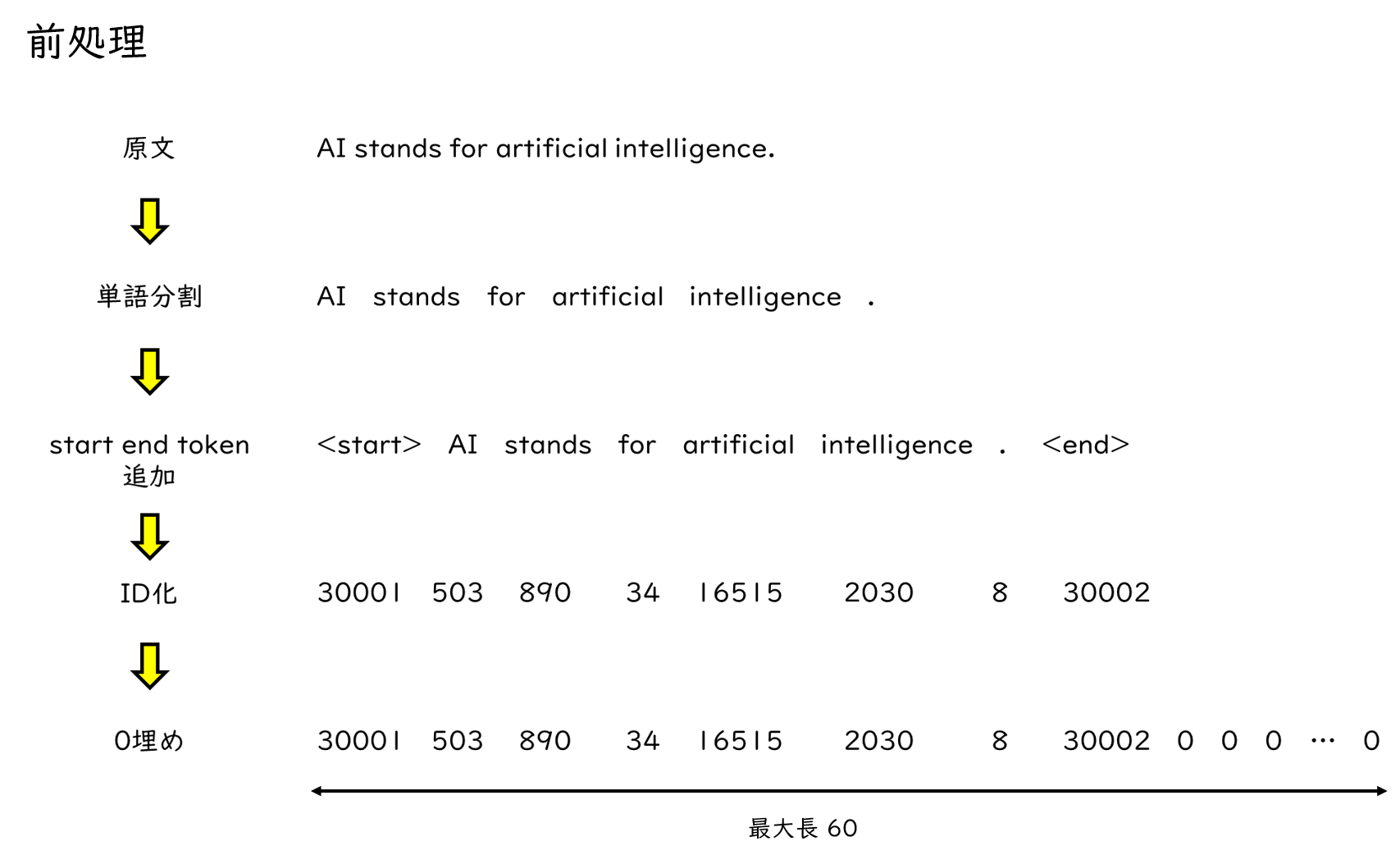
ここでは、原文がを単語分割し、文章の開始と終了を表すstartとendトークンを付与します。
次に、単語をIDに置き換えます。各単語に一つずつユニークなIDが割り当てられ、この例ではAIなら503といったIDが割り当てられています。
最後に0埋めを行うことで、文章の長さを揃えます。文によって単語の数がバラバラだとモデルで処理することが難しいため、あらかじめ最大長を定めておきます。
以上のような前処理を経て、モデルに入力するシーケンスが作成されます。
preprocess_utils.PreprocessDataのパラメータは以下の通りです。
- mecab:使用するトーカナイザーを設定
- source_data:翻訳元データ
- target_data:翻訳後データ
- max_length:シーケンスの最大長
- batch_size:バッチサイズ
- test_flag:テストデータを作成する場合はTrue
- train_dataset:test_flag=Trueの場合は、学習データを入力する
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
BATCH_SIZE = 64 # バッチサイズ MAX_LENGTH = 60 # シーケンスの長さ USE_TPU = False # TPUを使うか BUFFER_SIZE = 50000 train_dataset = preprocess_utils.PreprocessData( mecab = MeCab.Tagger("-Ochasen"), source_data = train_source, target_data = train_target, max_length = MAX_LENGTH, batch_size = BATCH_SIZE, test_flag = False, train_dataset = None, ) train_dataset.preprocess_data() test_dataset = preprocess_utils.PreprocessData( mecab = MeCab.Tagger("-Ochasen"), source_data = test_source, target_data = test_target, max_length = MAX_LENGTH, batch_size = BATCH_SIZE, test_flag = True, train_dataset = train_dataset ) test_dataset.preprocess_data() |
バッチ作成
ここでは、学習に使うバッチデータを作成しています。
バッチサイズが64なので、64のデータを一つのまとまりとしてバッチを作成します。
予測ではTPUを使用しないので、実行されるコードは以下の2行となります。
|
1 2 |
trainset = tf.data.Dataset.from_tensor_slices((train_dataset.source_vector, train_dataset.target_vector)) trainset = trainset.map(lambda source, target: (tf.cast(source, tf.int64), tf.cast(target, tf.int64))).shuffle(buffer_size=BUFFER_SIZE).batch(BATCH_SIZE).prefetch(buffer_size=tf.data.experimental.AUTOTUNE) |
モデル定義
使用するハイパラメータは以下の通りです。
- num_layers:レイヤー数
- d_model:中間層の次元数
- num_heads:Multi Head Attentionのヘッド数
- dff:Feed Forward Networkの次元数
- dropout_rate:ドロップアウト率
|
1 2 3 4 5 6 7 8 |
num_layers=4 # レイヤー数 d_model=64 # 中間層の次元数 num_heads=4 # Multi Head Attentionのヘッド数 dff=2048 # Feed Forward Networkの次元数 dropout_rate = 0.1 # ドロップアウト率 source_vocab_size = max(train_dataset.source_token.values()) + 1 # source文の語彙数 target_vocab_size = max(train_dataset.target_token.values()) + 1 # target文の語彙数 |
また、今回はモデルの読み書きにpklファイルを用いているので、初期化関数を定義しています。
モデルの読み書きはGCPで行うのが一般的ですが、今回はGCPを使用しないので、このやり方を採用しました。
この関数はTransformerや最適化関数、損失関数などを定義した後に実行することで、学習済みの重みを初期の重みとして利用することができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 重み初期化 def initialize_weight(checkpoint_path, optimizer, transformer, max_length, batch_size, use_tpu=False): if os.path.exists(checkpoint_path+'.pkl'): if use_tpu: number_of_tpu_cores = tpu_cluster_resolver.num_accelerators()['TPU'] initialize_source, initialize_target = [[1]*max_length]*number_of_tpu_cores, [[1]*max_length]*number_of_tpu_cores initialize_set = tf.data.Dataset.from_tensor_slices((initialize_source, initialize_target)) initialize_set = initialize_set.map(lambda source, target: (tf.cast(source, tf.int64), tf.cast(target, tf.int64)) ).shuffle(buffer_size=BUFFER_SIZE).batch(batch_size).prefetch( buffer_size=tf.data.experimental.AUTOTUNE ) initialize_set = strategy.experimental_distribute_dataset(initialize_set) for inp, tar in initialize_set: distributed_train_step(inp, tar) else: initialize_set = tf.ones([batch_size, max_length], tf.int64) train_step(initialize_set, initialize_set) try: weight_utils.load_weights_from_pickle(checkpoint_path, optimizer, transformer) except: print('Failed to load checkpoints.') else: print('No available checkpoints.') |
次に、モデル定義についてみていきましょう。
Transformer
- Transormerクラスを作成しています。クラスの中身については次回以降、解説予定です。
- 先ほど定義したハイパーパラメータが入力されているのがわかります。
|
1 2 3 4 5 6 |
# Transformer transformer = model.Transformer(num_layers, d_model, num_heads, dff, source_vocab_size, target_vocab_size, pe_input=source_vocab_size, pe_target=target_vocab_size, rate=dropout_rate) |
Learning Rate
- ここでは学習率を設定しています。
- 学習が進むごとに学習率が小さくなるように設定されています。
|
1 2 |
# Learning Rate learning_rate = model.CustomSchedule(d_model) |
Optimizer
- optimizerにはAdamを使用し、先ほど設定したlearning_rateに従います。
|
1 2 3 |
# Optimizer optimizer = tf.keras.optimizers.Adam(learning_rate, beta_1=0.9, beta_2=0.98, epsilon=1e-9) |
Loss Function
- 損失関数にはSparseCategoricalCrossentropyを使用します。
- 予測した単語確率と正解単語間の損失を求めます。
- また、損失を計算する際はPADの0を無視するためにマスクします。
|
1 2 3 4 5 6 7 8 9 10 11 |
# Loss loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction='none') # Loss Function def loss_function(real, pred): mask = tf.math.logical_not(tf.math.equal(real, 0)) loss_ = loss_object(real, pred) mask = tf.cast(mask, dtype=loss_.dtype) loss_ *= mask return tf.reduce_mean(loss_) |
metrics
- metricsを下記のように設定します。
|
1 2 |
train_loss = tf.keras.metrics.Mean(name='train_loss') train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy') |
予測
予測はnに任意の数値を入れるとその番号のデータを予測用のデータセットから取り出して予測するようになっています。
predict関数に予測したい文章のベクトルを入力することで、翻訳後の文章とattention_weightsを出力します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 翻訳 n = 0# 任意のテストデータを指定 print("Input:", ' '.join([train_dataset.source_index[i] for i in test_dataset.source_vector[n][:np.argmax(test_dataset.source_vector[n], 0)+1]])) result, attention = predict(test_dataset.source_vector[n][:np.argmax(test_dataset.source_vector[n], 0)+1]) txt = "" for i in result[1:]: txt+=train_dataset.target_index[i.numpy()] print("Output:", txt) # Attention Weightをプロット plot_attention_weights(attention, test_dataset.source_vector[n][:np.argmax(test_dataset.source_vector[n], 0)+1], result[1:], "decoder_layer4_block2") |
predict関数の内部では、入力文のシーケンスと仮のターゲット文のシーケンスをtransfomerの実行関数に入力し、ターゲット文の次に次に来る単語を予測します。
ちなみに仮のターゲット文のシーケンスの初期状態はトークンが存在するだけです。
transformerが予測結果を出力したら、その単語を仮のターゲット文の最後尾に追加し、再びtransformerに入力します。
これをトークンを予測するか、ターゲット文の最大シーケンス長になるまで繰り返しますことでターゲット文を生成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
def predict(input_vec): encoder_input = np.array([input_vec]) decoder_input = [max(train_dataset.target_token.values())-2] output = tf.expand_dims(decoder_input, 0) for i in range(train_dataset.max_length): enc_padding_mask, combined_mask, dec_padding_mask = model.create_masks( encoder_input, output) predictions, attention_weights = transformer(encoder_input, output, False, enc_padding_mask, combined_mask, dec_padding_mask) predictions = predictions[: ,-1:, :] predicted_id = tf.cast(tf.argmax(predictions, axis=-1), tf.int32) if predicted_id == max(train_dataset.target_token.values())-1: return tf.squeeze(output, axis=0), attention_weights output = tf.concat([output, predicted_id], axis=-1) return tf.squeeze(output, axis=0), attention_weights |
また、plot_attention_weights関数は、予測結果をもとにattention_weightsの図を作成する関数です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
def plot_attention_weights(attention, input_source, result, layer): fig = plt.figure(figsize=(16, 8)) sentence = tf.cast(input_source, tf.int64) attention = attention[layer][0,:, :, :len(input_source)] for head in range(attention.shape[0]): ax = fig.add_subplot(2, 4, head+1) ax.matshow(attention[head][:-1, :], cmap='viridis') fontdict = {'fontsize': 10} ax.set_xticks(range(len(sentence))) ax.set_yticks(range(len(result))) ax.set_ylim(len(result)-1.5, -0.5) tmp_list = [] for i in sentence: try: tmp_list.append(train_dataset.source_index[i.numpy()]) except: pass ax.set_xticklabels(tmp_list, fontdict=fontdict, rotation=90) ax.set_yticklabels([train_dataset.target_index[i.numpy()] for i in result if i < max(train_dataset.target_token.values()) - 1], fontdict=fontdict) ax.set_xlabel('Head {}'.format(head+1)) plt.tight_layout() plt.show() |
予測結果
次に予測結果を見てましょう。
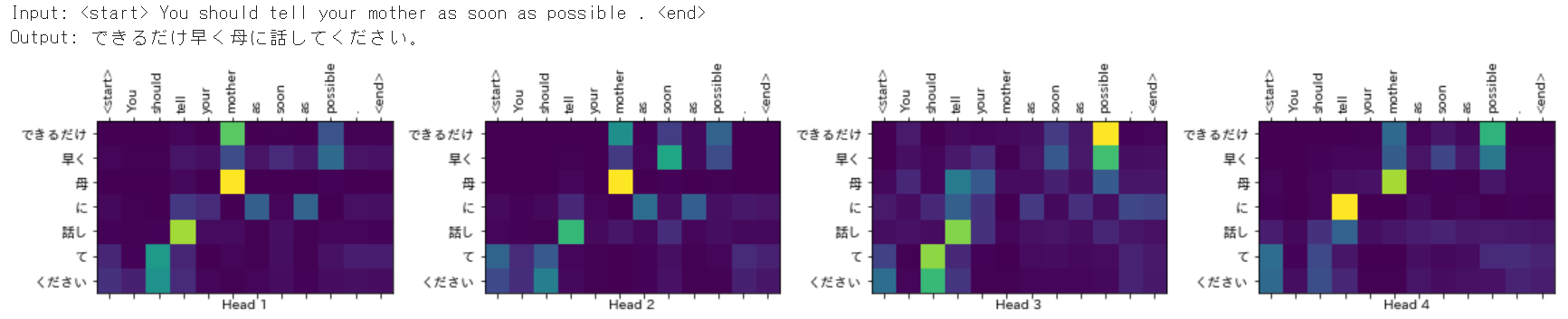
この例では、「 You should tell your mother as soon as possible .」という入力文に対して「できるだけ早く母に話してください。」という文章を出力しました。
それらしい文章に翻訳できていることがわかります。
また、その下のattention_weightsの図を見てみましょう。
attention_weightsの図を見ると入力文と出力文における単語間の関連性を見ることができます。
これは各headのattention_weightsの図を示したものになりますが、色が明るいほど単語間の関連性が強く出ているのがわかります。
例えば、head_1では「mother」という単語と「母」という単語間の関連性が強く出ており、翻訳前の単語と翻訳後の単語とでちゃんと結びつきができていると思われます。
また、他のheadも見てみると「tell」と「話し」の関係性が出ていたり、「possible」と「できるだけ」も対応付けられていることがわかります。
以上、Predict_on_GPU.ipynbの解説でした。
次回はTransformerがどのように学習をして、このような機械翻訳を実現しているのかを解説します。
(K.K)

