
はじめに
この記事では、Attentionを使用することなくコンテキスト情報を考慮することができるLambda Networksについて解説します。
研究の概要
近年活躍著しいTransformerはAttentionという注意機構を持っています。AttentionはAttention Map(どのデータとどのデータの関係性が強いのかを示す)を作成することで、LSTMやRNNといった従来の深層学習モデルが扱うことができなかった長期の依存関係を特徴量として獲得することができるようになりました。しかしながら、Attentionはデータの大きさが大きくなるほどその計算量も増えるため、適用範囲は限られていました。そこで今回紹介するLambda Networksでは、Attention Mapの作成を必要とせず、コンテキスト情報を獲得することができるLambda Layerを導入することで計算量の問題も解決しています。次に示すグラフはLamdaResNetとEfficientNet、ResNetにおける学習時間と予測精度を比較したものです。
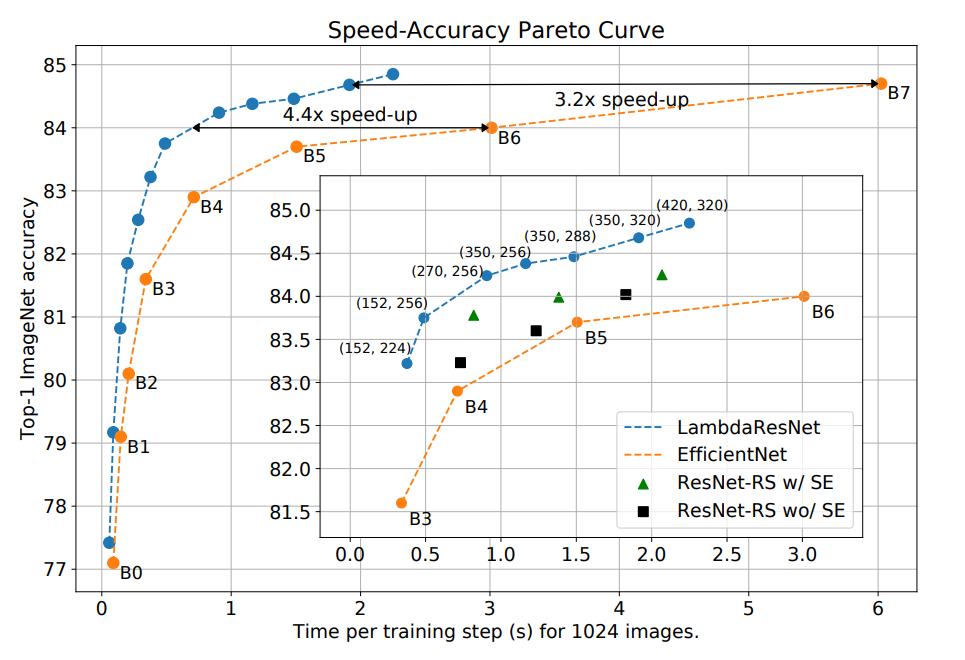
LamdaResNetはResNetのボトルネックブロックにおける畳み込み層をLambda Layerに置き換えたものです。EfficientNetの学習・正則化設定に合わせた場合、LambdaResNetはEfficientNetより3.2-4.4倍速く、ResNet-RS with squeeze-and-excitationより1.6-2.3倍速い結果となりました。また、画像サイズ320で学習し最大のLambdaResNetであるLambdaResNet-420は84.9%のトップ1の精度を達成しました。
Attention
Lambda Layerを解説する前にAttentionについておさらいしたいと思います。Attentionは以下の式から求めることができます。
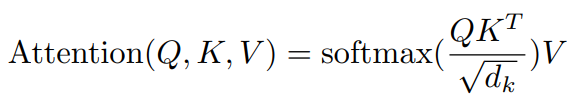
ここで用いられているQ, K, Vはそれぞれquery, key, valueでした。これら3つの要素は画像データなりテキストデータなり何でもよいのですが、Self-Attentionの場合はquery, key, valueは同じデータになります。
Attentionにおける操作を図で表すと以下のようになります。
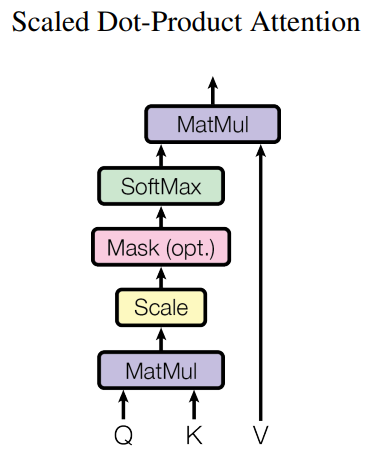
MatMulでqueryとkeyで内積をとっています。ここで内積が意味するのはqueryとkeyの関係性を探っているということです。queryとkeyの各要素が似ていれば値が大きくなり、似ていなければ値が小さくなります。その後softmaxをかけていますが、これはMatMulで算出したqueryとkeyにおける各要素の類似度を0~1に収まるようにしています。そうすることで、データにおいてどの要素が重要であるのかを表すことができます。これがいわゆるAttention Mapと呼ばれるものです。最後にそのAttention MapをMatMulでvalueと掛け合わせていますが、これはAttention Mapを元のデータと掛け合わせることで関係性があるところを強調しているイメージです。

query, key, valueといったものは次に説明するLambda Layerでも使用されています。
Lambda Layer
Lambda Layerは、Attention Mapを作成しない代わりにコンテンツベースと位置ベースの2つの相互作用をモデル化するすることでコンテキスト情報を考慮しています。コンテンツベースと位置ベースの役割は以下の通りです。
- コンテンツベース:コンテキストの内容を考慮する。ただし、クエリの位置とコンテキストの関係(例えば、2つのピクセル間の相対距離)は無視される
- 位置ベース:クエリの位置とコンテキストの位置の関係を考慮する
つまり、コンテンツベースはコンテキストの内容を扱い、位置ベースはデータの位置関係を扱っています。
モデルアーキテクチャ
Lambda Layerの計算グラフと各図が意味するものは以下の通りです。
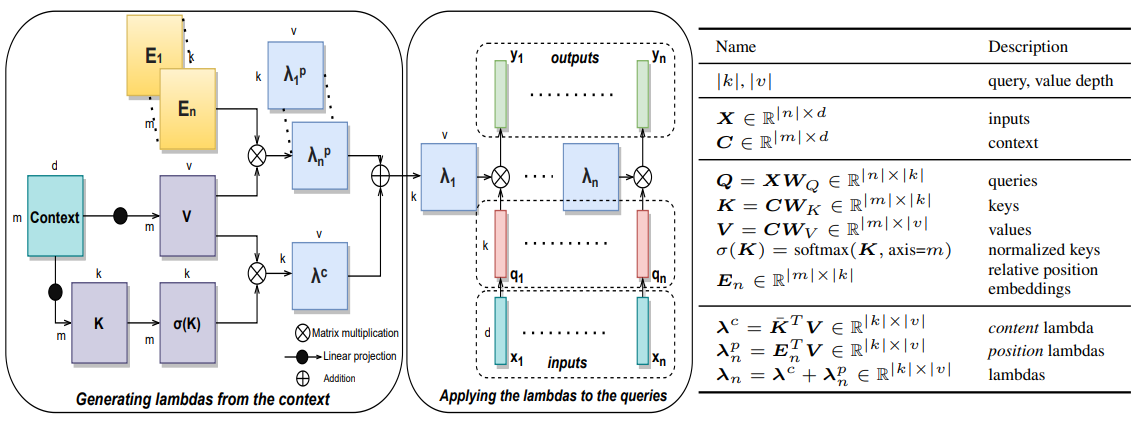
- 左:Lambda Layerの詳細
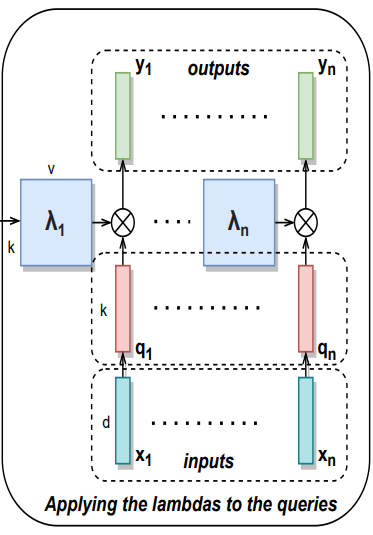
- 中央:Lambda Layerをqueryに適用
- 右:各変数の詳細
まず、右の表から見ていきましょう。ここでは左図と中央の図で記載されている各変数の詳細を記載しています。Xは入力データ、Cはコンテキストですが、ここでは同一のデータ(画像やテキストなど)と考えて構いません。Q, K, VはXとCを畳み込みしたものです。σ(K)はKにsoftmaxを適用したもの、Enは位置関係を示す埋め込み表現です。λcはコンテンツベースのlambda、λnpは位置ベースのlambdaで、それらを足したものがλnになります。

以上の変数を踏まえて左図のLambda Layerを見てみましょう。
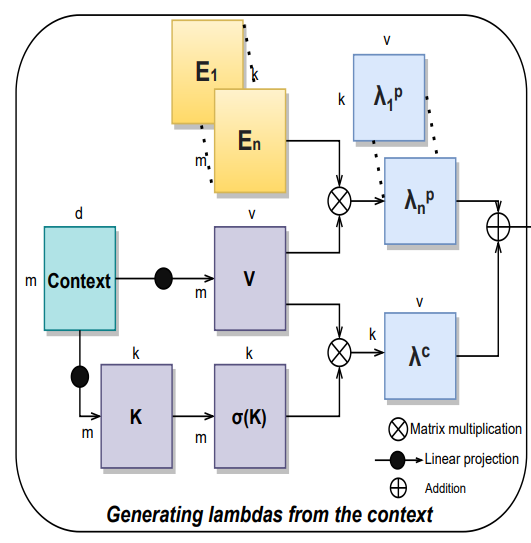
まずContextからK, Vを作り、Kはsoftmaxで非線形化した後にVと掛け合わせています。これはλc、コンテンツベースのlambdaにあたり、コンテキストを固定サイズの線形関数に集約しています。
つづいて、E1~EnとVを掛け合わせることでλnp、位置ベースのlambdaを作っています。E1~Enは位置情報を保持する埋め込み表現です。ここではクエリの位置とコンテキストの位置の関係を考慮させています。
そして、そこから得られたλcとλnpを足し合わせることでλnを得ています。ここの処理の図を数式で書くと以下のようになります。
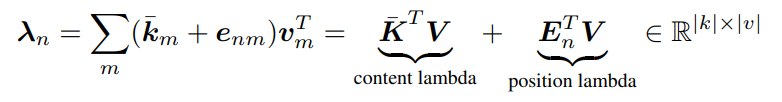
最後に中央の図のLambdaをqueryに適用している部分ですが、ここでは各位置ごとに作成されたλnをそれぞれ対応するqnと掛け合わせ最終的な出力ynを得ていることが分かります。
この部分を数式で書くと以下のようになります。コンテンツベースのlambdaと位置ベースのlambdaを足し合わせたものを転置してqueryに掛け合わせています。
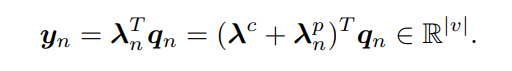
コード解説
つづいて、実装コードについて解説します。実装コードは論文にも記載されていますが、こちらのものを使用します。PyTorchとTensorFlowで実装されていますが、今回はPyTorchのコードを参照します。
Lambda Layerはクラスとして記述されています。まずは__init__メソッドの内容から見ていきたいと思います。
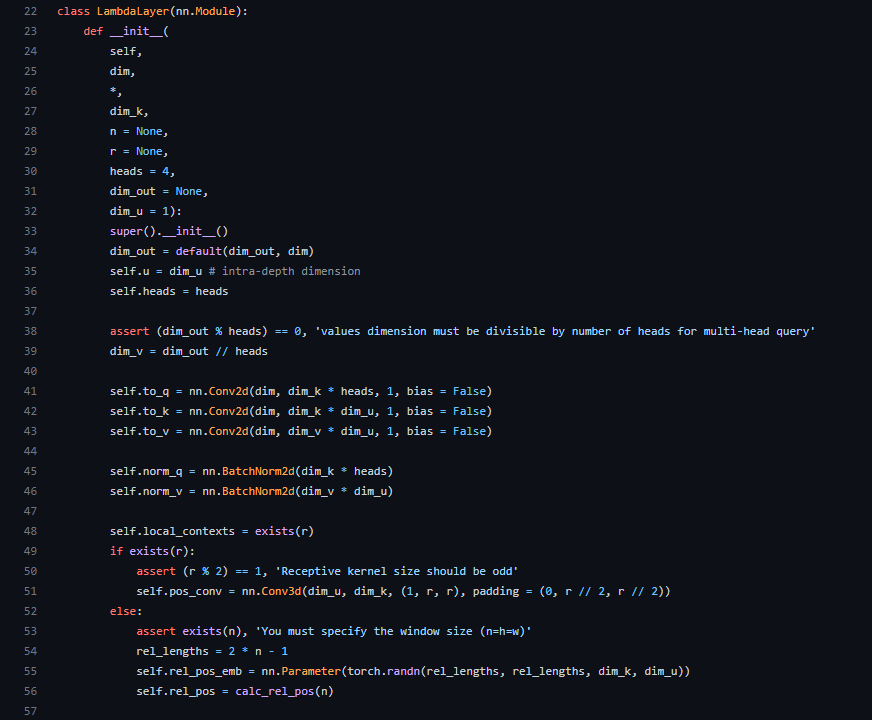
引数については以下の通りです。
- dim:入力次元数
- dim_out:出力次元数
- n:グローバルコンテキストのサイズ
- r:ローカルコンテキストのサイズ
- dim_k:keyの次元数
- heads:マルチqueryのヘッド数
- dim_u:intra-depthの次元数。lambdaを適用するコストを一定に保ちつつ、lambdaを生成するためにより多くの計算を割り当てるもの。
nn.Conv2d(41行目~43行目)では、二次元の畳み込み層を定義していることが分かります。カーネルサイズは1です。その後、nn.BatchNorm2d(45行目~46行目)と、正規化層が定義されています。
48行目以降では、グローバルコンテキストにするかローカルコンテキストにするかをで処理が異なります。この部分は後ほどforwardメソッドと一緒に説明したいと思います。
つづいてLambda Layerクラスのforward関数について見てみましょう。
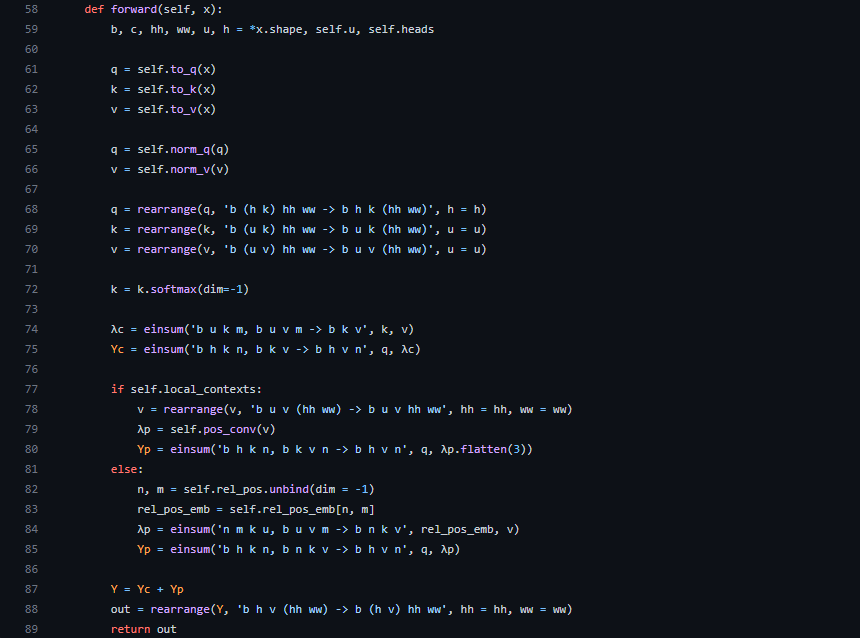
引数にあるxは入力データです。59行目で変数に代入しているのは、それぞれベクトルxの形状、intra-depthの次元数、マルチqueryのヘッド数です。61行目~63行目で入力データに対して畳み込みを行い、q, k, vを得ます。その後、q, vは正規化され(65, 66行目)ていることが分かります。
68行目~70行目ではq, k, vそれぞれのベクトルの形状が変更されています。ここでは、einopsという可読性と信頼性の高い柔軟で強力なテンソル演算を提供するライブラリを用いており、rearrange(再配置)メソッドで軸の入れ替えを行っています。einopsの詳細については下記のGitHubリポジトリを参照してください。
q, k, vの形状を変更した後、72行目でkがsoftmaxに適用されています。これはモデルアーキテクチャのところで説明したコンテンツベースのlambdaを作成する部分です。74行目でk, vが掛け合わされ、λcを出力していることが分かります。この計算はアインシュタインの縮約記法で書かれています。

75行目ではqueryとコンテンツベースのlambdaが掛け合わされています。これも同じくモデルアーキテクチャのところで説明した以下の計算式の部分をやっています。λnp(位置ベースのlambda)についても以降のコードでqueryと掛け合わせている部分がでてきます。
つづいて77行目以降を見ていきましょう。ここでは位置ベースのlambda、λnpを算出しています。ただ、self.local_contextsによって処理が異なります。LambdaLayerクラス__init__メソッドのところでも同様の部分がありましたが、グローバルコンテキストにするかローカルコンテキストにするかによって処理を変えています。
ローカルコンテキストの場合

ローカルコンテキストの場合はvalueの形状を変更して、pos_convという関数にvalueを入力しています。このpos_convはLambdaLayerクラスの__init__メソッドで定義されていたもので、以下を見ると3次元の畳み込み層(nn.Conv3d)であることが分かります。

そして、カーネルサイズに引数rが利用されています。このrは参照するローカルコンテキストのサイズを表しています。最終的に畳み込み処理を施したλpとqueryを掛け合わせ、位置ベースのローカルコンテキストYpを得ています(forwardメソッド80行目)。
グローバルコンテキストの場合

グローバルコンテキストの場合はvalueと”rel_pos_emb”を掛け合わせることで位置ベースのlambda、λnpを作成しています(84行目)。このrel_pos_embは82と83行目から得られるものですが、詳しくはLambdaLayerクラスの__init__メソッドで定義されています。

rel_pos_embはnn.Parameterを用いてレイヤーのパラメータの初期値を乱数で設定しています。rel_posはまた別の関数(calc_rel_pos)になります(56行目)。

calc_rel_posはグローバルコンテキストのサイズnにあわせて相対位置のインデックスを作成します。これらを踏まえて再びforwardメソッドに戻ると、rel_pos_embはself.rel_pos_embに相対位置のインデックス(n, m)でアクセスしたものになります(82と83行目)。
以上が位置ベースのlambdaになります。
そして、最後にYcとYpを足して再度rearangeでベクトルの形状を変更したものを出力として返すことでLambdaLayerの計算は終わります(87行目~89行目)。

おわりに
今回はAttentionを使用しないことで計算量を効率化するだけではなく予測精度も改善しているLambda Networksについて紹介してきました。Lambda Networksではコンテキストの考慮をコンテンツベースのlambdaと位置ベースのlambdaに分けることで計算を工夫していることが分かりました。近年、AI分野の発展を支えてきたAttentionを使用しないで、これだけの成果を出せたという点で非常に興味深い研究でした。
- 参考文献
- https://arxiv.org/abs/2102.08602
- https://github.com/lucidrains/lambda-networks
(K. K)
