
この記事では、言語処理100本ノック第1章の解説 に引き続き、言語処理100本ノック第2章の解説を行っていきます。 第2章では、UNIXコマンドを用いて、txtファイルを処理していくことがメインになります。 それでは、 第2章の問題を解きましたので、処理の流れとポイントを踏まえて、解説していきます。
問題と解説
popular-names.txtは,アメリカで生まれた赤ちゃんの「名前」「性別」「人数」「年」をタブ区切り形式で格納したファイルである.以下の処理を行うプログラムを作成し,popular-names.txtを入力ファイルとして実行せよ.さらに,同様の処理をUNIXコマンドでも実行し,プログラムの実行結果を確認せよ.
- popular-names.txtをダウンロードし、保存する。
|
1 2 |
#popular-names.txtをダウンロードし、baby.txtに保存する !curl https://nlp100.github.io/data/popular-names.txt -o popular-names.txt |
行数のカウント
行数をカウントせよ.確認にはwcコマンドを用いよ.
【コード】
|
1 2 3 4 |
import pandas as pd df = pd.read_table("popular-names.txt", header=None) print(df.shape[0]) |
|
1 2 |
#UNIXコマンド !wc popular-names.txt |
【出力結果】

【処理の流れ】
- pandasをimportする。
- ヘッダーを無くし、textファイルを読み込む。
- 行数が欲しいので、df.shape[0]で、行数だけを取得。
【ポイント】
- pd.read_table()関数:textファイルを読み込む関数として用意されている。
- header引数:popular-names.txtは、ヘッダーがないのでNoneにしないと、データの1行目がヘッダーに指定されてしまう。
- DataFrame.shape属性(Series.shape属性):DataFrame(Series)の次元をタプルで、返す。今回のDataFrameの場合、戻り値は(行数, 列数)になっているため、インデックスを指定すれば、行数または列数を取得できる。
タブをスペースに置換
タブ1文字につきスペース1文字に置換せよ.確認にはsedコマンド,trコマンド,もしくはexpandコマンドを用いよ.
【コード】
|
1 2 3 4 |
with open("popular-names.txt") as f : for data in f: data = data.replace("\n", "") print(data.replace("\t", " ")) |
|
1 2 |
#UNIXコマンド !sed -e 's/\t/ /g' ./popular-names.txt |
【出力結果】

【処理の流れ】
- textファイルを1行ずつ読み込む。
- 改行文字を削除し、タブを空白文字に置換する。
【ポイント】
- replace(“\n”, “”):空白文字に置き換えず、文字を削除していることに注意。
1列目をcol1.txtに,2列目をcol2.txtに保存
各行の1列目だけを抜き出したものをcol1.txtに,2列目だけを抜き出したものをcol2.txtとしてファイルに保存せよ.確認にはcutコマンドを用いよ.
【コード】
|
1 2 3 4 5 |
df1 = df.iloc[:, 0] df2 = df.iloc[:, 1] df1.to_csv("col1.txt", sep=",", header=False, index=False) df2.to_csv("col2.txt", sep=",", header=False, index=False) |
|
1 2 3 |
#UNIXコマンド !cut -f 1 popular-names.txt > col1.txt !cut -f 2 popular-names.txt > col2.txt |
【出力結果】
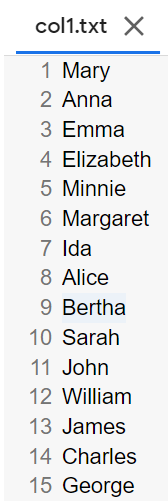
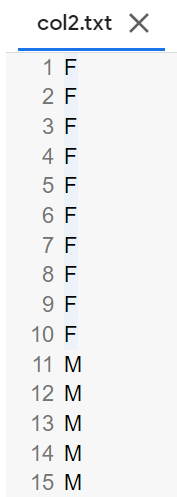
col1.txtとcol2.txtをマージ
12で作ったcol1.txtとcol2.txtを結合し,元のファイルの1列目と2列目をタブ区切りで並べたテキストファイルを作成せよ.確認にはpasteコマンドを用いよ.
【コード】
|
1 2 3 4 5 |
col1 = pd.read_csv("col1.txt", header=None) col2 = pd.read_csv("col2.txt", header=None) col1_2 = pd.concat([col1, col2], axis=1) col1_2.to_csv("col1_2.txt", sep="\t", header=False, index=False) |
|
1 2 |
#UNIXコマンド !paste col1.txt col2.txt > col1_2.txt |
【出力結果】
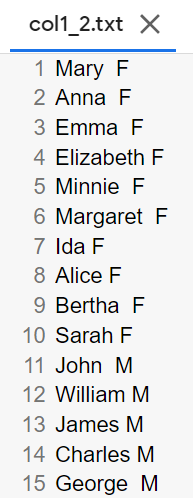
【処理の流れ】
- 12.で作成した、csvファイルをそれぞれコールする。
- pd.concat([col1, col2], axis=1)を指定して、横にそれぞれのデータを連結させる。
- 連結させたデータをタブ区切りで、ファイルに書き込む。
【ポイント】
- pd.concat()関数:DataFrame、Seriesオブジェクトを引数に受け取り、axis引数に指定した方向にデータを連結する。行方向(横)に連結させたい場合は、axis=1。列方向(縦)に連結させたい場合は、axis=0を指定する。
先頭からN行を出力
自然数Nをコマンドライン引数などの手段で受け取り,入力のうち先頭のN行だけを表示せよ.確認にはheadコマンドを用いよ.
【コード】
|
1 |
df.head(10) |
|
1 2 |
#UNIXコマンド !head -n 10 popular-names.txt |
【出力結果】
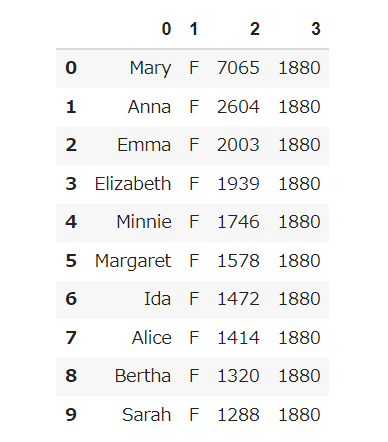
末尾のN行を出力
自然数Nをコマンドライン引数などの手段で受け取り,入力のうち末尾のN行だけを表示せよ.確認にはtailコマンドを用いよ.
【コード】
|
1 |
df.tail(10) |
|
1 2 |
#UNIXコマンド !tail -n 10 popular-names.txt |
【出力結果】
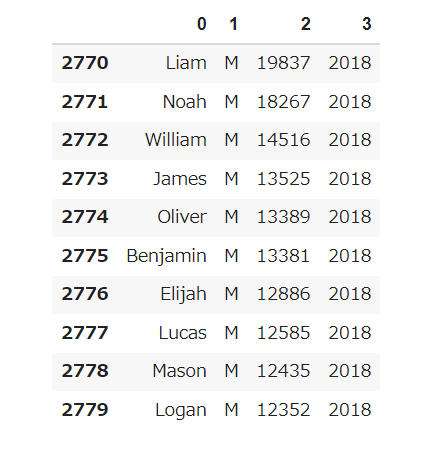
ファイルをN分割する
自然数Nをコマンドライン引数などの手段で受け取り,入力のファイルを行単位でN分割せよ.同様の処理をsplitコマンドで実現せよ.
【コード】
|
1 2 3 4 5 |
n = 2 idx = df.shape[0] // n for i in range(n): df_split = df.iloc[i * idx:(i + 1) * idx] df_split.to_csv(f"popular-names{i}.txt", sep="\t",header=False, index=False) |
|
1 2 |
#UNIXコマンド !split -n 2 popular-names.txt |
【出力結果】
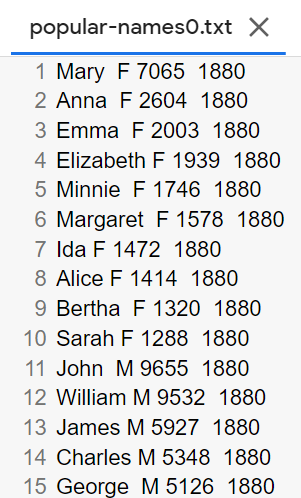

【処理の流れ】
- DataFrameの行数をN分割数で割る(小数点切り捨て)。
- df.iloc[i * idx:(i + 1) * idx]を指定して、DataFrameの行を分割する。
- csvファイルに、データをタブ区切りで、書き込んでいく。
【ポイント】
- idx = df.shape[0] // n:データ数を分割数Nで割る(切り捨て除算)。
- df.iloc[i * idx:(i + 1) * idx]:i * idxから(i + 1) * idxの一つ手前までのDataFrameの行を抽出している。
1列目の文字列の異なり
1列目の文字列の種類(異なる文字列の集合)を求めよ.確認にはcut, sort, uniqコマンドを用いよ.
【コード】
|
1 |
print(set(df.iloc[:, 0])) |
|
1 2 |
#UNIXコマンド !cut -f 1 popular-names.txt | sort | uniq |
【出力結果】

【処理の流れ】
- DataFrameの1列目を抽出し、set()関数を使用して、重複を無くす。
【ポイント】
- set()関数(組み込み):引数にイテラブルオブジェクトを受け取る。戻り値は、setオブジェクト。setオブジェクトの要素は、順序と重複がないことに注意する。
各行を3コラム目の数値の降順にソート
各行を3コラム目の数値の逆順で整列せよ(注意: 各行の内容は変更せずに並び替えよ).確認にはsortコマンドを用いよ(この問題はコマンドで実行した時の結果と合わなくてもよい).
【コード】
|
1 |
df.sort_values(2, ascending=False) |
|
1 2 |
#UNIXコマンド !cut -f 3 popular-names.txt | sort -n -r |
【出力結果】
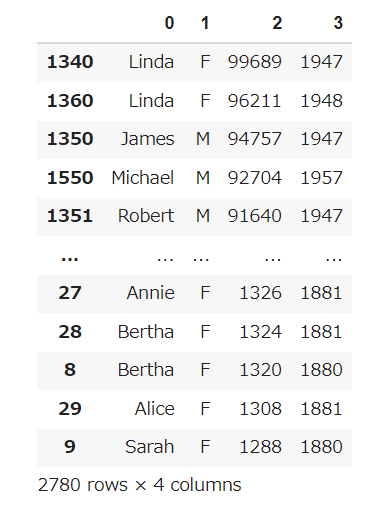
【処理の流れ】
- DataFrameの3列目のデータを降順にし、それをもとに、すべてのデータを並び替える。
【ポイント】
- DataFrame.sort_values()メソッド(Series.sort_values()):第一引数にsortしたい列名を指定する。指定した列データを基準にDataFrame全体をsortする。デフォルトで、昇順にする。
- ascending引数:ascending=Falseを指定することで、降順にする。
各行の1コラム目の文字列の出現頻度を求め,出現頻度の高い順に並べる
各行の1列目の文字列の出現頻度を求め,その高い順に並べて表示せよ.確認にはcut, uniq, sortコマンドを用いよ.
【コード】
|
1 2 |
sr = df[0] print(sr.value_counts()) |
|
1 2 |
#UNIXコマンド !cut -f 1 popular-names.txt | sort | uniq -c | sort -n -r |
【出力結果】

【処理の流れ】
- DataFrameの1列目を取得する。
- value_counts()で求められた、1列目の各要素数を降順に並び替える。
【ポイント】
- Series.value_counts()メソッド:デフォルトで、各要素数を降順で出力する。
- DataFrameに使用する場合は、DataFrame.apply()メソッドと併用する必要がある。
おわりに
以上が、言語処理100本ノック第2章の解説になります。個人的には、「問16.ファイルをN分割する」のところで、分割アルゴリズムを考える事に時間がかかりました。実装方法は、一通りではないので、自分なりのコードで挑戦してみてはいかかでしょうか。次は、言語処理100本ノック第3章の解説を行っていきます。
K.Y

